
Ekipman rezervasyon uygulaması: çakışmaları önleyin ve iadeleri takip edin
Çifte rezervasyonları önleyen, iadeleri ve hasarları kaydeden, arızalı ekipmanları bakım bekletmesine alan bir ekipman rezervasyon uygulaması planlayın.
Bileşenleri, avantajları ve dağıtım stratejileri dahil olmak üzere Apache Hadoop'un temellerini ve büyük veri mimarisindeki rolünü keşfedin. Modern veri ekosistemlerine nasıl uyduğunu ve büyük ölçekli işlemeyi nasıl kolaylaştırdığını öğrenin.

Hadoop Dağıtılmış Dosya Sistemi (HDFS), Apache Hadoop çerçevesinin temel bileşenlerinden biridir. Büyük bilgi işlem düğümü kümelerinde büyük hacimli verileri yönetmek için optimize edilmiş, dağıtılmış, hataya dayanıklı ve ölçeklenebilir bir dosya sistemidir. HDFS, toplu veri işleme görevlerini barındıracak şekilde tasarlanmıştır ve büyük, akışlı okuma işlemleri için yüksek düzeyde optimize edilmiştir, bu da onu büyük veri mimarisinde kullanım için ideal hale getirir.
HDFS, hata toleransı ve yüksek kullanılabilirlik sağlamak için temel bir özellik olarak veri çoğaltma ile verileri bir kümedeki birden çok düğümde depolar. Varsayılan çoğaltma faktörü 3'tür, ancak belirli veri depolama ve güvenilirlik gereksinimlerinin gereksinimlerini karşılamak için ayarlanabilir. Veri bloklara bölünür (varsayılan olarak 128 MB boyutundadır) ve küme boyunca dağıtılır. Bu, verilerin kaynağına mümkün olduğunca yakın bir yerde saklanmasını ve işlenmesini sağlayarak ağ gecikmesini azaltır ve performansı artırır.
HDFS'nin iki ana bileşeni vardır:
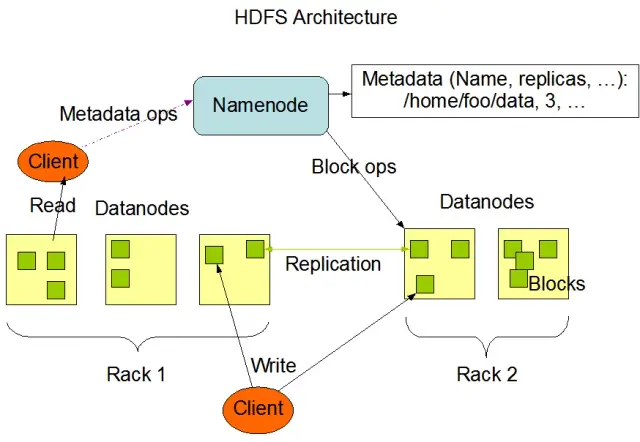
Görüntü kaynağı: Apache Hadoop
HDFS, çeşitli dosya işlemleri sağlar ve dosya ve dizin oluşturma, silme ve yeniden adlandırma gibi geleneksel dosya sistemi özelliklerini destekler. Birincil işlemler şunları içerir:
İstemciler, Hadoop komut satırı arabirimini, Java API'lerini veya web tabanlı HDFS tarayıcılarını kullanarak HDFS ile etkileşim kurabilir.
MapReduce, büyük ölçekli, dağıtılmış veri işleme için kullanılan bir programlama modeli ve Apache Hadoop'un çekirdek bileşenidir. Geliştiricilerin çok sayıda düğümde çok büyük miktarda veriyi paralel olarak işleyebilen programlar yazmasına olanak tanır. MapReduce modeli iki temel işleme dayanmaktadır: Haritala ve Küçült.
Harita aşamasında, girdi verileri parçalara bölünür ve Harita işlevi her bir parçayı paralel olarak işler. İşlev, anahtar-değer çiftlerini girdi olarak alır ve ara anahtar-değer çiftlerini çıktı olarak üretir. Çıkış çiftleri, onları Azaltma aşamasına hazırlamak için anahtara göre sıralanır.
Azaltma aşaması, Harita işlevi tarafından oluşturulan ara anahtar-değer çiftlerini toplar ve nihai çıktıyı üretmek için bunları daha fazla işler. Azalt işlevi, aynı anahtarı paylaşan her bir değer grubuna uygulanır. Küçült işlevinin çıktısı, belirli kullanım durumuna bağlı olarak HDFS'ye veya başka bir depolama sistemine geri yazılır.
MapReduce kullanarak kelime sıklığını hesaplamanın basit bir örneğini ele alalım. Metin belgelerini içeren büyük bir veri kümesi verildiğinde, Harita işlevi her belgeyi ayrı ayrı işler, her kelimenin tekrarını sayar ve kelime-frekans çiftlerini yayar. Azaltma aşamasında, Harita işlevi tarafından oluşturulan ara anahtar/değer çiftleri sözcük bazında toplanır ve toplam sözcük frekansları hesaplanarak nihai çıktı üretilir.
MapReduce ayrıca, diğer mevcut düğümlerde başarısız olan görevleri otomatik olarak yeniden başlatabilen ve bireysel düğümlerin başarısızlığına rağmen işlemenin devam etmesini sağlayan yerleşik bir hata toleransı mekanizmasına sahiptir.
Arka uç, web ve mobil uygulamalar geliştirmek için kod gerektirmeyen güçlü bir platform olan AppMaster.io , Hadoop tabanlı büyük veri çözümlerini tamamlayabilir. AppMaster.io ile, büyük veri mimariniz tarafından üretilen ve depolanan verileri işlemek ve analiz etmek için HDFS ve MapReduce gibi Hadoop bileşenleriyle sorunsuz bir şekilde entegre olan web ve mobil uygulamalar oluşturabilirsiniz.
İşletmeler, hem Hadoop hem de AppMaster.io'nun avantajlarından yararlanarak, Hadoop'un ölçeklenebilirliği ve verimliliği ile no-code uygulama geliştirmenin hızı ve maliyet etkinliğini birleştiren güçlü büyük veri uygulamaları oluşturabilir. AppMaster.io'nun sezgisel sürükle ve bırak arabirimi ve görsel iş süreci tasarımcısı, derinlemesine kodlama uzmanlığına ihtiyaç duymadan uygulamaları hızlı bir şekilde oluşturmanıza olanak tanıyarak, daha hızlı pazara sürüm süresi ve daha düşük geliştirme maliyetleri sağlar.
Ayrıca, AppMaster.io şirket içinde veya bulutta konuşlandırılabilen gerçek uygulamalar oluşturduğundan, verileriniz ve uygulama altyapınız üzerinde tam kontrol sağlayabilirsiniz. Bu esneklik, kuruluşunuzun boyutu veya sektör sektörü ne olursa olsun, özel ihtiyaçlarınıza göre uyarlanmış kapsamlı bir büyük veri çözümü oluşturmanıza olanak tanır.
AppMaster.io'yu büyük veri mimarisi için Hadoop ile birlikte kullanmak, daha hızlı uygulama geliştirme, daha düşük geliştirme maliyetleri ve büyük ölçekli veri kümelerini işleme ve analiz etmede artan verimlilik dahil olmak üzere çok sayıda avantaj sağlayabilir. İşletmeler, her iki platformun güçlü yönlerinden yararlanarak, büyümeyi destekleyen ve değerli içgörüler sağlayan ölçeklenebilir büyük veri uygulamaları oluşturabilir.
Hadoop kümeleri için doğru dağıtım stratejisini seçmek, büyük veri altyapınızın optimum performansını ve yönetimini sağlamak için çok önemlidir. Hadoop kümelerini kurarken seçebileceğiniz üç ana dağıtım modeli vardır:
Şirket içi dağıtımda, Hadoop kümeleri kuruluşunuzun kendi veri merkezleri kullanılarak şirket içinde kurulur ve yönetilir. Bu yaklaşım, fiziksel güvenlik üzerinde kontrol, veri egemenliği ve uyumluluk için bilinen bir ortam gibi çeşitli avantajlar sunar. Yine de şirket içi dağıtımlar, donanım, bakım ve BT personeline daha fazla ön yatırım gerektirerek kaynak açısından yoğun olabilir. Ayrıca, yalnızca fiziksel altyapıya güvenildiğinde kaynakları ölçeklendirmek zor olabilir.
Hadoop kümelerinin bulut tabanlı dağıtımı , Amazon Web Services (AWS) , Google Cloud Platform (GCP) ve Microsoft Azure gibi bulut platformlarının ölçeklenebilirliği, esnekliği ve maliyet verimliliğinden yararlanır. Bulut hizmeti sağlayıcısı, altyapı yönetiminin sorumluluğunu alarak ekibinizin veri işleme ve analizine odaklanmasını sağlar. Bulut tabanlı konuşlandırmalar, kullandıkça öde fiyatlandırma modelleri sunar, yani yalnızca tükettiğiniz kaynaklar için ödeme yaparsınız. Yine de bazı kuruluşlar, verilerini üçüncü taraf bulut sağlayıcılarına emanet ederken veri güvenliği ve uyumluluğu konusunda endişeleri olabilir.
Hibrit dağıtım stratejisi, hem şirket içi hem de bulut tabanlı dağıtımların güçlü yanlarını birleştirir. Bu modelde, hassas veriler ve düzenlemeye tabi iş yükleri şirket içinde kalabilirken, diğer iş yükleri ve veriler maliyet verimliliği ve ölçeklenebilirlik için buluta yüklenebilir. Hibrit dağıtım, kuruluşların bulut bilgi işlemin sunduğu avantajlardan yararlanırken kontrol, güvenlik ve esneklik ihtiyaçlarını dengelemesine olanak tanır.
Her dağıtım modelinin artıları ve eksileri vardır, bu nedenle Hadoop kümeniz için en uygun stratejiyi seçerken maliyet, ölçeklenebilirlik, bakım, güvenlik ve uyumluluk gereksinimlerini göz önünde bulundurmanız önemlidir.
Apache Hadoop, çeşitli büyük veri zorluklarını ele almak, değerli içgörüler elde etmek için büyük hacimli yapılandırılmış ve yapılandırılmamış verileri analiz etmek için endüstrilerde yaygın olarak kullanılmaktadır. İşte Hadoop'un bazı yaygın gerçek hayat uygulamaları:
Apache Hadoop, çeşitli sektörlerdeki büyük veri sorunlarının üstesinden gelmek için güçlü ve çok yönlü bir çözümdür. Bileşenlerini, faydalarını, dağıtım stratejilerini ve kullanım durumlarını anlamak, bu teknolojiyi büyük ölçekli veri depolama ve işleme için benimsemek isteyen kuruluşlar için çok önemlidir.
Hadoop'u no-codeAppMaster platformu gibi diğer modern geliştirme yaklaşımlarıyla birleştirmek, işletmelere kapsamlı, ölçeklenebilir ve verimli bir veri işleme ekosistemi sunar. Doğru strateji ve devreye alma modeli ile kuruluşunuz, Hadoop'un gücünden yararlanabilir ve daha iyi karar verme, optimizasyon ve yenilik sağlamak için büyük verinin potansiyelinden yararlanabilir.
Theodore Levitt'in sözü pek çok doğruyu barındırıyor: "İnovasyon, hayata değişim, gelişme ve ilerleme getiren kıvılcım gibidir." Hadoop ve AppMaster birleştirdiğimizde, bu kıvılcımı yakalamak gibidir. Bu dinamik ikili, kuruluşları büyük kararlar almaya, daha akıllıca çalışmaya ve yeni fikirler bulmaya itiyor. Yolunuzu planlarken, büyük verilerin büyüme için bir hazine sandığı gibi olduğunu unutmayın. Ve doğru araçlarla, ilerlemeye ve daha iyi zamanlara giden kapıyı açıyorsunuz.
Apache Hadoop, büyük hacimli verileri verimli bir şekilde depolamak, işlemek ve analiz etmek için tasarlanmış açık kaynaklı bir çerçevedir. Depolama için Hadoop Dağıtılmış Dosya Sistemi (HDFS) ve işleme için MapReduce gibi büyük verilerin çeşitli yönlerini işlemek için birlikte çalışan birden çok bileşen içerir. Büyük veri mimarisinde Hadoop, büyük veri kümelerini yönetmek ve bunlardan içgörüler elde etmek için altyapı sağlayan bir mihenk taşı görevi görür.
Apache Hadoop, dağıtılmış ve paralel işleme yetenekleri aracılığıyla büyük veri sorunlarının üstesinden gelir. Verileri, birbirine bağlı makinelerden oluşan bir kümede paralel olarak işlenen daha küçük parçalara ayırır. Bu yaklaşım, ölçeklenebilirliği, hata toleransını ve performansı geliştirerek büyük ölçekli veri işleme ve analiz görevlerini gerçekleştirmeyi mümkün kılar.
Apache Hadoop, bir makine kümesinde veri depolamayı yönetmek için Hadoop Dağıtılmış Dosya Sistemini (HDFS) kullanır. HDFS, verileri bloklara ayırır, hata toleransı için çoğaltır ve küme genelinde dağıtır. Bu dağıtılmış depolama mimarisi, yüksek kullanılabilirlik ve güvenilirlik sağlar.
MapReduce, Hadoop içinde dağıtılmış veri işlemeyi sağlayan bir programlama modeli ve işleme motorudur. Görevleri iki aşamaya ayırır: veri işleme için "harita" aşaması ve toplama ve özetleme için "azaltma" aşaması. MapReduce, geliştiricilerin çok sayıda düğümde ölçeklenen kod yazmasına izin vererek, onu büyük verilerin paralel işlenmesi için uygun hale getirir.
Apache Hadoop'u entegre etmek, veri depolama ve işlemeden sorumlu birden fazla düğümden oluşan bir Hadoop kümesi kurmayı içerir. Kuruluşlar, veri alışverişini kolaylaştırmak için bağlayıcılar ve API'ler kullanarak Hadoop'u mevcut sistem ve araçların yanı sıra dağıtabilir. Ek olarak Hadoop, çeşitli veri alma yöntemlerini destekleyerek onu çeşitli kaynaklardan gelen verilerle uyumlu hale getirir.
Apache Hadoop, büyük veri teknolojilerindeki ilerlemelerle birlikte gelişmeye devam ediyor. Daha yeni araçlar ve çerçeveler ortaya çıkmış olsa da Hadoop, birçok büyük veri ekosisteminin temel bir bileşeni olmaya devam ediyor. Sağlamlığı, esnekliği ve çeşitli veri türlerini işleme yeteneği, onu gelecekteki kullanım durumları ve büyük veri dünyasındaki zorluklar için iyi konumlandırır.



Ücretsiz planla AppMaster ile denemeler yapın.
Hazır olduğunuzda uygun aboneliği seçebilirsiniz.


