
แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
สำรวจพื้นฐานของ Apache Hadoop และบทบาทในสถาปัตยกรรมข้อมูลขนาดใหญ่ รวมถึงส่วนประกอบ ประโยชน์ และกลยุทธ์การปรับใช้ เรียนรู้ว่ามันเข้ากับระบบนิเวศข้อมูลสมัยใหม่และอำนวยความสะดวกในการประมวลผลขนาดใหญ่ได้อย่างไร

Hadoop Distributed File System (HDFS) เป็นหนึ่งในองค์ประกอบพื้นฐานของเฟรมเวิร์ก Apache Hadoop เป็นระบบไฟล์แบบกระจาย ทนทานต่อข้อผิดพลาด และปรับขนาดได้ซึ่งปรับให้เหมาะสมสำหรับการจัดการข้อมูลปริมาณมากในคลัสเตอร์ขนาดใหญ่ของโหนดคอมพิวเตอร์ HDFS ได้รับการออกแบบมาเพื่อรองรับงานประมวลผลข้อมูลเป็นชุด และได้รับการปรับให้เหมาะสมที่สุดสำหรับการดำเนินการอ่านแบบสตรีมมิ่งขนาดใหญ่ ทำให้เหมาะสำหรับใช้ในสถาปัตยกรรมข้อมูลขนาดใหญ่
HDFS จัดเก็บข้อมูลในหลาย ๆ โหนดในคลัสเตอร์ โดยมีการจำลองแบบข้อมูลเป็นคุณลักษณะหลักเพื่อให้แน่ใจว่ามีความทนทานต่อข้อผิดพลาดและความพร้อมใช้งานสูง ปัจจัยการจำลองแบบเริ่มต้นคือ 3 แต่สามารถปรับให้ตรงกับความต้องการของพื้นที่จัดเก็บข้อมูลและข้อกำหนดด้านความน่าเชื่อถือที่เฉพาะเจาะจงได้ ข้อมูลถูกแบ่งออกเป็นบล็อก (โดยค่าเริ่มต้น ขนาด 128 MB) และกระจายไปทั่วคลัสเตอร์ สิ่งนี้ทำให้มั่นใจได้ว่าข้อมูลจะถูกจัดเก็บและประมวลผลใกล้กับแหล่งที่มามากที่สุดเท่าที่จะเป็นไปได้ ลดเวลาแฝงของเครือข่ายและปรับปรุงประสิทธิภาพ
มีสององค์ประกอบหลักของ HDFS:
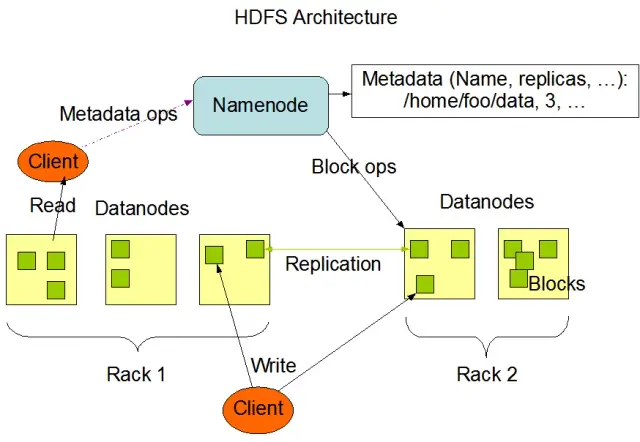
แหล่งที่มาของรูปภาพ: Apache Hadoop
HDFS มีการดำเนินการกับไฟล์ที่หลากหลายและสนับสนุนคุณลักษณะของระบบไฟล์แบบดั้งเดิม เช่น การสร้าง การลบ และการเปลี่ยนชื่อไฟล์และไดเร็กทอรี การดำเนินงานหลักประกอบด้วย:
ไคลเอนต์สามารถโต้ตอบกับ HDFS โดยใช้อินเทอร์เฟซบรรทัดคำสั่ง Hadoop, Java API หรือเบราว์เซอร์ HDFS บนเว็บ
MapReduce เป็นรูปแบบการเขียนโปรแกรมและองค์ประกอบหลักของ Apache Hadoop ที่ใช้สำหรับการประมวลผลข้อมูลแบบกระจายขนาดใหญ่ ช่วยให้นักพัฒนาสามารถเขียนโปรแกรมที่สามารถประมวลผลข้อมูลจำนวนมหาศาลแบบขนานผ่านโหนดจำนวนมาก โมเดล MapReduce ขึ้นอยู่กับการดำเนินการหลักสองอย่าง: แผนที่และการลดขนาด
ในขั้นตอนแผนที่ ข้อมูลอินพุตจะถูกแบ่งออกเป็นส่วนย่อย และฟังก์ชันแผนที่จะประมวลผลแต่ละส่วนพร้อมกัน ฟังก์ชันรับคู่คีย์-ค่าเป็นอินพุตและสร้างคู่คีย์-ค่าระดับกลางเป็นเอาต์พุต คู่เอาต์พุตจะถูกจัดเรียงตามคีย์เพื่อเตรียมพร้อมสำหรับขั้นตอนการลด
ขั้นตอนการลดรวมคู่คีย์-ค่าระดับกลางที่สร้างโดยฟังก์ชันแผนที่ ประมวลผลเพิ่มเติมเพื่อสร้างเอาต์พุตขั้นสุดท้าย ฟังก์ชันย่อจะใช้กับแต่ละกลุ่มของค่าที่ใช้คีย์เดียวกันร่วมกัน เอาต์พุตของฟังก์ชัน Reduce จะถูกเขียนกลับไปยัง HDFS หรือระบบจัดเก็บข้อมูลอื่น ขึ้นอยู่กับกรณีการใช้งานเฉพาะ
ลองพิจารณาตัวอย่างง่ายๆ ของการคำนวณความถี่ของคำโดยใช้ MapReduce ด้วยชุดข้อมูลขนาดใหญ่ที่มีเอกสารข้อความ ฟังก์ชัน Map จะประมวลผลเอกสารแต่ละฉบับแยกจากกัน นับจำนวนคำที่เกิดขึ้นในแต่ละคำและปล่อยคู่ความถี่คำ ในขั้นตอนการลด คู่คีย์-ค่าระดับกลางที่สร้างโดยฟังก์ชันแผนที่จะรวมกันเป็นคำ และความถี่ของคำทั้งหมดจะถูกคำนวณ ทำให้เกิดเอาต์พุตสุดท้าย
นอกจากนี้ MapReduce ยังมีกลไกการยอมรับข้อผิดพลาดในตัวที่สามารถรีสตาร์ทงานที่ล้มเหลวโดยอัตโนมัติบนโหนดอื่นๆ ที่มีอยู่ ทำให้มั่นใจได้ว่าการประมวลผลจะดำเนินต่อไปแม้ว่าแต่ละโหนดจะล้มเหลวก็ตาม
AppMaster.io ซึ่งเป็นแพลตฟอร์ม แบบไม่ใช้โค้ดอัน ทรงพลังสำหรับการพัฒนาแบ็กเอนด์ เว็บ และแอปพลิเคชันมือถือ สามารถเสริมโซลูชันข้อมูลขนาดใหญ่บน Hadoop ได้ ด้วย AppMaster.io คุณสามารถสร้างเว็บและแอปพลิเคชันมือถือที่ผสานรวมกับส่วนประกอบ Hadoop เช่น HDFS และ MapReduce ได้อย่างราบรื่น เพื่อประมวลผลและวิเคราะห์ข้อมูลที่สร้างและจัดเก็บโดยสถาปัตยกรรมบิ๊กดาต้าของคุณ
ด้วยการใช้ประโยชน์จากทั้ง Hadoop และ AppMaster.io ธุรกิจต่างๆ สามารถสร้างแอปพลิเคชันข้อมูลขนาดใหญ่ที่ทรงพลัง ซึ่งรวมความสามารถในการปรับขนาดและประสิทธิภาพของ Hadoop เข้ากับความเร็วและความคุ้มค่าของการพัฒนาแอปพลิเค no-code อินเทอร์เฟซ แบบลากและวาง ที่ใช้งานง่ายของ AppMaster.io และตัวออกแบบกระบวนการทางธุรกิจด้วยภาพของ AppMaster ช่วยให้คุณสร้างแอปพลิเคชันได้อย่างรวดเร็วโดยไม่จำเป็นต้องมีความเชี่ยวชาญในการเขียนโค้ดเชิงลึก ทำให้ มีเวลาออกสู่ตลาดได้เร็วขึ้น และลดต้นทุนการพัฒนา
ยิ่งไปกว่านั้น เนื่องจาก AppMaster.io สร้างแอปพลิเคชันจริงที่สามารถปรับใช้ในองค์กรหรือในระบบคลาวด์ คุณจึงสามารถควบคุมข้อมูลและโครงสร้างพื้นฐานแอปพลิเคชันของคุณได้อย่างเต็มที่ ความยืดหยุ่นนี้ช่วยให้คุณสร้างโซลูชันข้อมูลขนาดใหญ่ที่ครอบคลุมซึ่งปรับให้เหมาะกับความต้องการเฉพาะของคุณ โดยไม่คำนึงถึงขนาดขององค์กรหรือภาคอุตสาหกรรมของคุณ
การใช้ AppMaster.io ร่วมกับ Hadoop สำหรับสถาปัตยกรรมข้อมูลขนาดใหญ่สามารถให้ประโยชน์มากมาย รวมถึงการพัฒนาแอปพลิเคชันที่รวดเร็วขึ้น ลดค่าใช้จ่ายในการพัฒนา และเพิ่มประสิทธิภาพในการประมวลผลและวิเคราะห์ชุดข้อมูลขนาดใหญ่ ด้วยการใช้ประโยชน์จากจุดแข็งของทั้งสองแพลตฟอร์ม ธุรกิจสามารถสร้างแอปพลิเคชันข้อมูลขนาดใหญ่ที่ปรับขนาดได้ ซึ่งขับเคลื่อนการเติบโตและให้ข้อมูลเชิงลึกที่มีค่า
การเลือกกลยุทธ์การปรับใช้ที่เหมาะสมสำหรับคลัสเตอร์ Hadoop มีความสำคัญอย่างยิ่งต่อการประกันประสิทธิภาพสูงสุดและการจัดการโครงสร้างพื้นฐานข้อมูลขนาดใหญ่ของคุณ มีโมเดลการปรับใช้หลักสามแบบให้เลือกเมื่อตั้งค่าคลัสเตอร์ Hadoop:
ในการปรับใช้ภายในองค์กร คลัสเตอร์ Hadoop ได้รับการตั้งค่าและจัดการภายในองค์กร โดยใช้ศูนย์ข้อมูลขององค์กรคุณเอง วิธีการนี้มีข้อดีหลายประการ เช่น การควบคุมความปลอดภัยทางกายภาพ อำนาจอธิปไตยของข้อมูล และสภาพแวดล้อมที่เป็นที่รู้จักสำหรับการปฏิบัติตามข้อกำหนด ถึงกระนั้น การปรับใช้ภายในองค์กรอาจใช้ทรัพยากรมาก ทำให้ต้องมีการลงทุนล่วงหน้ามากขึ้นในด้านฮาร์ดแวร์ การบำรุงรักษา และบุคลากรด้านไอที นอกจากนี้ การปรับขนาดทรัพยากรอาจเป็นเรื่องที่ท้าทายเมื่อต้องพึ่งพาโครงสร้างพื้นฐานทางกายภาพเพียงอย่างเดียว
การปรับใช้คลัสเตอร์ Hadoop บนคลาวด์ใช้ประโยชน์จากความสามารถในการปรับขนาด ความยืดหยุ่น และความคุ้มค่าของแพลตฟอร์มคลาวด์ เช่น Amazon Web Services (AWS) , Google Cloud Platform (GCP) และ Microsoft Azure ผู้ให้บริการระบบคลาวด์มีหน้าที่รับผิดชอบในการจัดการโครงสร้างพื้นฐาน ทำให้ทีมของคุณสามารถมุ่งเน้นไปที่การประมวลผลและวิเคราะห์ข้อมูล การปรับใช้บนคลาวด์นำเสนอรูปแบบการกำหนดราคาแบบจ่ายตามการใช้งาน หมายความว่าคุณจ่ายเฉพาะทรัพยากรที่คุณใช้เท่านั้น ถึงกระนั้น บางองค์กรอาจมีข้อกังวลเกี่ยวกับความปลอดภัยของข้อมูลและการปฏิบัติตามข้อกำหนดเมื่อมอบความไว้วางใจให้กับผู้ให้บริการระบบคลาวด์บุคคลที่สาม
กลยุทธ์การปรับใช้แบบไฮบริดรวมจุดแข็งของการปรับใช้ทั้งในสถานที่และบนคลาวด์ ในรูปแบบนี้ ข้อมูลที่ละเอียดอ่อนและปริมาณงานที่มีการควบคุมสามารถยังคงอยู่ในองค์กรได้ ในขณะที่ปริมาณงานและข้อมูลอื่นๆ สามารถถ่ายโอนไปยังระบบคลาวด์เพื่อประสิทธิภาพด้านต้นทุนและความสามารถในการปรับขนาด การปรับใช้งานแบบไฮบริดช่วยให้องค์กรสามารถสร้างความสมดุลระหว่างความต้องการด้านการควบคุม ความปลอดภัย และความยืดหยุ่น ในขณะที่ใช้ประโยชน์จากข้อได้เปรียบที่ได้รับจากการประมวลผลแบบคลาวด์
การปรับใช้แต่ละรุ่นมีข้อดีและข้อเสีย ดังนั้นจึงจำเป็นต้องพิจารณาต้นทุน ความสามารถในการปรับขนาด การบำรุงรักษา ความปลอดภัย และการปฏิบัติตามข้อกำหนด เมื่อเลือกกลยุทธ์ที่เหมาะสมที่สุดสำหรับคลัสเตอร์ Hadoop ของคุณ
Apache Hadoop ถูกใช้อย่างกว้างขวางในอุตสาหกรรมต่างๆ เพื่อรับมือกับความท้าทายด้านข้อมูลขนาดใหญ่ต่างๆ วิเคราะห์ข้อมูลที่มีโครงสร้างและไม่มีโครงสร้างปริมาณมากเพื่อดึงข้อมูลเชิงลึกอันมีค่า ต่อไปนี้คือแอปพลิเคชันในชีวิตจริงทั่วไปของ Hadoop:
Apache Hadoop เป็นโซลูชันที่ทรงพลังและหลากหลายสำหรับจัดการกับความท้าทายด้านข้อมูลขนาดใหญ่ในอุตสาหกรรมต่างๆ การทำความเข้าใจองค์ประกอบ ประโยชน์ กลยุทธ์การปรับใช้ และกรณีการใช้งานเป็นสิ่งสำคัญสำหรับองค์กรที่ต้องการนำเทคโนโลยีนี้มาใช้สำหรับการจัดเก็บและประมวลผลข้อมูลขนาดใหญ่
การรวม Hadoop เข้ากับแนวทางการพัฒนาสมัยใหม่อื่นๆ เช่น แพลตฟอร์ม AppMasterno-code ช่วยให้ธุรกิจมีระบบนิเวศการประมวลผลข้อมูลที่ครอบคลุม ปรับขนาดได้ และมีประสิทธิภาพ ด้วยกลยุทธ์และโมเดลการปรับใช้ที่เหมาะสม องค์กรของคุณสามารถใช้ประโยชน์จากพลังของ Hadoop และใช้ประโยชน์จากศักยภาพของข้อมูลขนาดใหญ่เพื่อขับเคลื่อนการตัดสินใจ การเพิ่มประสิทธิภาพ และนวัตกรรมที่ดียิ่งขึ้น
คำพูดของ Theodore Levitt ถือเป็นความจริงมากมาย: "นวัตกรรมเป็นเหมือนประกายไฟที่นำการเปลี่ยนแปลง การปรับปรุง และความก้าวหน้ามาสู่ชีวิต" เมื่อเรารวม Hadoop และ AppMaster ก็เหมือนจับจุดประกายนั้น คู่หูที่ไม่หยุดนิ่งนี้ผลักดันให้องค์กรต่างๆ ตัดสินใจเรื่องสำคัญ ทำงานอย่างชาญฉลาดขึ้น และคิดไอเดียใหม่ๆ ในขณะที่คุณวางแผนเส้นทางของคุณ โปรดจำไว้ว่าข้อมูลขนาดใหญ่เปรียบเสมือนหีบสมบัติที่มีโอกาสเติบโต และด้วยเครื่องมือที่เหมาะสม คุณกำลังเปิดประตูสู่ความก้าวหน้าและเวลาที่ดีกว่า
Apache Hadoop เป็นเฟรมเวิร์กโอเพ่นซอร์สที่ออกแบบมาเพื่อจัดเก็บ ประมวลผล และวิเคราะห์ข้อมูลจำนวนมากอย่างมีประสิทธิภาพ ประกอบด้วยองค์ประกอบหลายอย่างที่ทำงานร่วมกันเพื่อจัดการด้านต่างๆ ของข้อมูลขนาดใหญ่ เช่น Hadoop Distributed File System (HDFS) สำหรับการจัดเก็บและ MapReduce สำหรับการประมวลผล ในสถาปัตยกรรมข้อมูลขนาดใหญ่ Hadoop ทำหน้าที่เป็นรากฐานที่สำคัญ โดยจัดเตรียมโครงสร้างพื้นฐานเพื่อจัดการและรับข้อมูลเชิงลึกจากชุดข้อมูลขนาดใหญ่
Apache Hadoop จัดการกับความท้าทายด้านข้อมูลขนาดใหญ่ผ่านความสามารถในการประมวลผลแบบกระจายและแบบขนาน มันแบ่งข้อมูลออกเป็นชิ้นเล็ก ๆ ซึ่งประมวลผลแบบขนานในคลัสเตอร์ของเครื่องที่เชื่อมต่อถึงกัน วิธีการนี้ช่วยเพิ่มความสามารถในการปรับขนาด ความทนทานต่อข้อผิดพลาด และประสิทธิภาพ ทำให้สามารถจัดการกับงานประมวลผลและวิเคราะห์ข้อมูลขนาดใหญ่ได้
Apache Hadoop ใช้ Hadoop Distributed File System (HDFS) เพื่อจัดการพื้นที่จัดเก็บข้อมูลในคลัสเตอร์ของเครื่อง HDFS แบ่งข้อมูลออกเป็นบล็อก จำลองข้อมูลเพื่อความทนทานต่อความผิดพลาด และกระจายข้อมูลไปทั่วคลัสเตอร์ สถาปัตยกรรมสตอเรจแบบกระจายนี้รับประกันความพร้อมใช้งานและความน่าเชื่อถือสูง
MapReduce เป็นโมเดลการเขียนโปรแกรมและเครื่องมือประมวลผลภายใน Hadoop ที่เปิดใช้งานการประมวลผลข้อมูลแบบกระจาย โดยจะแบ่งงานออกเป็นสองช่วง ได้แก่ ระยะ "แผนที่" สำหรับการประมวลผลข้อมูล และระยะ "ลด" สำหรับการรวมและการสรุป MapReduce ช่วยให้นักพัฒนาสามารถเขียนโค้ดที่ปรับขนาดตามโหนดจำนวนมาก ทำให้เหมาะสำหรับการประมวลผลข้อมูลขนาดใหญ่แบบขนาน
การรวม Apache Hadoop เกี่ยวข้องกับการตั้งค่าคลัสเตอร์ Hadoop ซึ่งประกอบด้วยโหนดหลายโหนดที่รับผิดชอบในการจัดเก็บและประมวลผลข้อมูล องค์กรสามารถปรับใช้ Hadoop ควบคู่ไปกับระบบและเครื่องมือที่มีอยู่ โดยใช้ตัวเชื่อมต่อและ API เพื่ออำนวยความสะดวกในการแลกเปลี่ยนข้อมูล นอกจากนี้ Hadoop ยังรองรับวิธีการนำเข้าข้อมูลที่หลากหลาย ทำให้เข้ากันได้กับข้อมูลจากแหล่งต่างๆ
Apache Hadoop พัฒนาอย่างต่อเนื่องควบคู่ไปกับความก้าวหน้าของเทคโนโลยีข้อมูลขนาดใหญ่ ในขณะที่มีเครื่องมือและเฟรมเวิร์กที่ใหม่กว่าเกิดขึ้น Hadoop ยังคงเป็นองค์ประกอบพื้นฐานของระบบนิเวศข้อมูลขนาดใหญ่หลายแห่ง ความแข็งแกร่ง ความยืดหยุ่น และความสามารถในการจัดการประเภทข้อมูลที่หลากหลายทำให้เหมาะสำหรับกรณีการใช้งานในอนาคตและความท้าทายในโลกของข้อมูลขนาดใหญ่



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


