

機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
Apache Hadoopの基礎と、そのコンポーネント、利点、導入戦略など、ビッグデータアーキテクチャにおけるその役割について説明します。最新のデータエコシステムにどのように適合し、大規模処理を促進するかを学びます。

Hadoop分散ファイルシステム(HDFS)は、Apache Hadoopフレームワークの基本コンポーネントの1つです。HDFSは、計算ノードの大規模クラスタ全体で大量のデータを管理するために最適化された、分散型、耐障害性、スケーラブルなファイルシステムです。HDFSはバッチデータ処理タスクに対応するように設計されており、大規模なストリーミング読み取り操作に高度に最適化されているため、ビッグデータアーキテクチャでの使用に最適です。
HDFSは、フォールトトレランスと高可用性を確保するための重要な機能であるデータレプリケーションによって、クラスタ内の複数のノードにわたってデータを保存します。デフォルトのレプリケーション係数は3だが、特定のデータストレージと信頼性要件のニーズに合わせて調整することができる。データはブロック(デフォルトでは128MBサイズ)に分割され、クラスタ全体に分散されます。これにより、データの保存と処理が可能な限りソースに近い場所で行われるようになり、ネットワークの待ち時間が短縮され、パフォーマンスが向上します。
HDFSには2つの主要コンポーネントがあります:
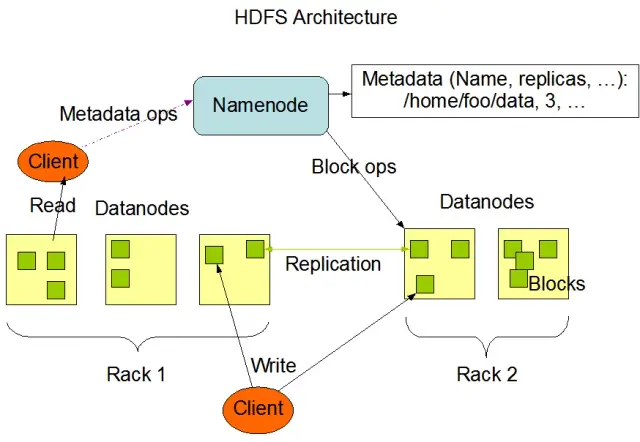
画像ソースApache Hadoop
HDFSは様々なファイル操作を提供し、ファイルやディレクトリの作成、削除、名前の変更などの伝統的なファイルシステムの機能をサポートしています。主な操作は以下の通りです:
クライアントはHadoopコマンドラインインターフェイス、Java API、またはウェブベースのHDFSブラウザを使ってHDFSとやり取りすることができます。
MapReduceはプログラミングモデルであり、大規模な分散データ処理に使用されるApache Hadoopのコアコンポーネントです。開発者は大量のデータを多数のノードで並列処理できるプログラムを書くことができる。MapReduceモデルは、2つの主要な操作に基づいている:MapとReduceだ。
Map段階では、入力データがチャンクに分割され、Map関数が各チャンクを並列処理する。この関数は入力としてキーと値のペアを受け取り、出力として中間のキーと値のペアを生成する。出力されたペアはキーでソートされ、Reduceステージに準備される。
Reduceステージは、Map関数によって生成された中間的なキーと値のペアを集約し、それらをさらに処理して最終的な出力を生成します。Reduce関数は、同じキーを共有する値の各グループに適用される。Reduce関数の出力は、特定のユースケースに応じて、HDFSまたは他のストレージシステムに書き戻される。
MapReduceを使って単語の頻度を計算する簡単な例を考えてみよう。テキスト文書を含む大きなデータセットが与えられると、Map関数は各文書を個別に処理し、各単語の出現回数を数え、単語頻度のペアを出力する。Reduceステージでは、Map関数によって生成された中間的なキーと値のペアが単語ごとに集約され、単語頻度の合計が計算され、最終的な出力が生成される。
MapReduceはまた、故障したタスクを他の利用可能なノードで自動的に再起動できるフォールト・トレランス・メカニズムを内蔵しており、個々のノードが故障しても処理が継続することを保証する。
AppMaster.ioは、バックエンド、ウェブ、モバイル・アプリケーションを開発するための強力な ノーコード・ プラットフォームであり、Hadoopベースのビッグデータ・ソリューションを補完することができます。AppMaster.ioを使用すると、HDFSやMapReduceなどのHadoopコンポーネントとシームレスに統合し、ビッグデータアーキテクチャによって生成・保存されたデータを処理・分析するWebおよびモバイルアプリケーションを構築できます。
HadoopとAppMaster.ioの両方の利点を活用することで、企業はHadoopのスケーラビリティと効率性と、no-code アプリケーション開発のスピードとコスト効率を組み合わせた強力なビッグデータアプリケーションを作成することができます。AppMaster.io の直感的な ドラッグ・アンド・ドロップ・ インターフェースとビジュアル・ビジネス・プロセス・デザイナーにより、深いコーディングの専門知識がなくてもアプリケーションを迅速に構築できるため、 市場投入までの時間が短縮 され、開発コストが削減されます。
さらに、AppMaster.ioは、オンプレミスまたはクラウドにデプロイ可能な実際のアプリケーションを生成するため、データとアプリケーションのインフラストラクチャを完全に制御することができます。この柔軟性により、組織の規模や業種に関係なく、特定のニーズに合わせた包括的なビッグデータ・ソリューションを構築することができます。
AppMaster.ioをHadoopと組み合わせてビッグデータアーキテクチャに使用することで、アプリケーション開発の迅速化、 開発コストの削減、大規模データセットの処理・分析効率の向上など、数多くの利点が得られます。両プラットフォームの長所を活用することで、企業は成長を促進し、価値ある洞察をもたらすスケーラブルなビッグデータアプリケーションを構築することができます。
Hadoopクラスタの適切な展開戦略を選択することは、ビッグデータインフラストラクチャの最適なパフォーマンスと管理を確保する上で非常に重要です。Hadoopクラスタをセットアップする際には、3つの主要な展開モデルから選択できます:
オンプレミス展開では、Hadoopクラスターは組織内のデータセンターを利用して社内でセットアップおよび管理されます。このアプローチには、物理的セキュリティの管理、データの主権、コンプライアンスのための既知の環境など、いくつかの利点があります。しかし、オンプレミスのデプロイメントでは、ハードウェア、メンテナンス、IT要員への先行投資が必要になり、リソースが集中する可能性があります。また、物理インフラだけに頼っていると、リソースのスケーリングが困難になることもある。
クラウドベースの Hadoop クラスタのデプロイでは、 Amazon Web Services (AWS)、Google Cloud Platform (GCP)、 Microsoft Azure などのクラウドプラットフォームのスケーラビリティ、柔軟性、コスト効率を活用します。クラウド・サービス・プロバイダーがインフラ管理の責任を負うため、チームはデータ処理と分析に専念できます。クラウドベースのデプロイメントには従量課金モデルがあり、消費したリソースに対してのみ支払いが発生します。しかし、サードパーティのクラウド・プロバイダーにデータを預ける場合、データ・セキュリティやコンプライアンスに懸念を持つ組織もあるだろう。
ハイブリッドデプロイメント戦略は、オンプレミスとクラウドベースの両方の長所を組み合わせたものです。このモデルでは、機密データや規制対象のワークロードはオンプレミスに残し、その他のワークロードやデータはクラウドにオフロードしてコスト効率と拡張性を高めることができます。ハイブリッド導入により、企業はクラウドコンピューティングが提供する利点を活用しながら、制御、セキュリティ、柔軟性に対するニーズのバランスを取ることができます。
各展開モデルには長所と短所があるため、Hadoop クラスタに最適な戦略を選択する際には、コスト、スケーラビリティ、メンテナンス、セキュリティ、コンプライアンス要件を考慮することが不可欠です。
Apache Hadoopは、さまざまなビッグデータの課題に対処し、大量の構造化データおよび非構造化データを分析して価値ある洞察を引き出すために、業界全体で広く使用されています。ここでは、Hadoop の一般的な実際のアプリケーションをいくつか紹介します:
Apache Hadoop は、さまざまな業界におけるビッグデータの課題に対処するための強力で汎用性の高いソリューションです。そのコンポーネント、メリット、導入戦略、ユースケースを理解することは、大規模データの保存と処理にこのテクノロジーを採用しようとしている組織にとって不可欠です。
Hadoop をno-codeAppMaster プラットフォームのような最新の開発アプローチと組み合わせることで、包括的でスケーラブルかつ効率的なデータ処理エコシステムが実現します。適切な戦略と導入モデルによって、組織はHadoopのパワーを活用し、ビッグデータの可能性を活かして、より良い意思決定、最適化、イノベーションを推進することができます。
セオドア・レビットの格言は、 「イノベーションは、変化、改善、進歩をもたらす火花のようなもの である。HadoopとAppMaster 、その火花をとらえるようなものです。このダイナミックなコンビは、大きな決断を下し、より賢く働き、斬新なアイデアを思いつくよう組織を後押しする。あなたの進路を計画するとき、ビッグデータが成長の可能性を秘めた宝箱のようなものであることを思い出してください。そして、適切なツールがあれば、進歩とより良い時代への扉を開くことができる。
Apache Hadoopは、大量のデータを効率的に保存、処理、分析するために設計されたオープンソースのフレームワークである。ストレージ用のHadoop Distributed File System (HDFS)や処理用のMapReduceなど、ビッグデータの様々な側面を処理するために連携する複数のコンポーネントで構成されている。ビッグデータアーキテクチャにおいて、Hadoopは礎石として機能し、膨大なデータセットを管理し、そこから洞察を引き出すためのインフラを提供する。
Apache Hadoopは、分散並列処理機能によってビッグデータの課題に対処する。Apache Hadoopはデータを小さな塊に分解し、相互に接続されたマシンのクラスタ全体で並列処理する。このアプローチにより、スケーラビリティ、耐障害性、パフォーマンスが向上し、大規模なデータ処理や分析タスクを処理することが可能になる。
Apache HadoopはHadoop分散ファイルシステム(HDFS)を採用し、マシンのクラスタ全体でデータストレージを管理する。HDFSはデータをブロックに分割し、フォールトトレランスのためにそれらを複製し、クラスタ全体に分散する。この分散ストレージアーキテクチャにより、高い可用性と信頼性が保証される。
MapReduceは、分散データ処理を可能にするHadoop内のプログラミングモデルと処理エンジンである。データを処理する「マップ」フェーズと、集計や要約を行う「リデュース」フェーズの2つのフェーズにタスクを分割する。MapReduceにより、開発者は多数のノードにまたがってスケールするコードを書くことができ、ビッグデータの並列処理に適している。
Apache Hadoopを統合するには、データの保存と処理を担当する複数のノードで構成されるHadoopクラスタをセットアップする必要がある。組織は既存のシステムやツールとともにHadoopを導入し、コネクタやAPIを使用してデータ交換を促進することができる。さらに、Hadoopはさまざまなデータ取り込み方法をサポートしており、さまざまなソースからのデータに対応している。
Apache Hadoopは、ビッグデータ技術の進歩とともに進化し続けている。より新しいツールやフレームワークが登場した一方で、Hadoopは多くのビッグデータエコシステムの基本的な構成要素であり続けています。その堅牢性、柔軟性、多様なデータタイプを扱う能力は、ビッグデータの世界における将来のユースケースや課題に対して、Hadoopを有利に位置づけています。




