
App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Explore os fundamentos do Apache Hadoop e o seu papel na arquitetura de grandes volumes de dados, incluindo os seus componentes, vantagens e estratégias de implementação. Saiba como ele se encaixa em ecossistemas de dados modernos e facilita o processamento em grande escala.

O HDFS (Hadoop Distributed File System) é um dos componentes fundamentais da estrutura do Apache Hadoop. É um sistema de arquivos distribuído, tolerante a falhas e escalável, otimizado para gerenciar grandes volumes de dados em grandes clusters de nós de computação. O HDFS foi concebido para acomodar tarefas de processamento de dados em lote e está altamente optimizado para grandes operações de leitura em fluxo contínuo, o que o torna ideal para utilização na arquitetura de grandes volumes de dados.
O HDFS armazena dados em vários nós de um cluster, com a replicação de dados como um recurso fundamental para garantir tolerância a falhas e alta disponibilidade. O fator de replicação predefinido é 3, mas pode ser ajustado para satisfazer as necessidades dos requisitos específicos de armazenamento de dados e de fiabilidade. Os dados são divididos em blocos (por defeito, 128 MB de tamanho) e distribuídos pelo cluster. Isso garante que os dados sejam armazenados e processados o mais próximo possível de sua origem, reduzindo a latência da rede e melhorando o desempenho.
Existem dois componentes principais do HDFS:
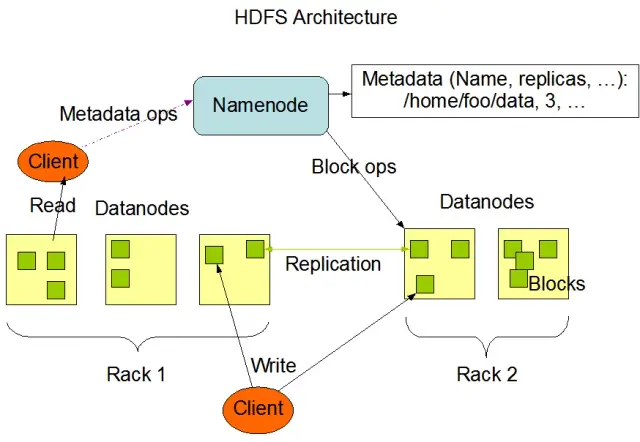
Fonte da imagem: Apache Hadoop
O HDFS fornece várias operações de ficheiros e suporta as funcionalidades tradicionais do sistema de ficheiros, como a criação, eliminação e renomeação de ficheiros e directórios. As principais operações incluem:
Os clientes podem interagir com o HDFS usando a interface de linha de comando do Hadoop, APIs Java ou navegadores HDFS baseados na Web.
O MapReduce é um modelo de programação e um componente central do Apache Hadoop utilizado para o processamento de dados distribuídos em grande escala. Ele permite que os desenvolvedores escrevam programas que podem processar grandes quantidades de dados em paralelo em um grande número de nós. O modelo MapReduce é baseado em duas operações principais: Mapear e Reduzir.
Na fase Map, os dados de entrada são divididos em partes e a função Map processa cada parte em paralelo. A função recebe pares chave-valor como entrada e gera pares chave-valor intermédios como saída. Os pares de saída são ordenados por chave para os preparar para a fase Reduzir.
A fase Reduce agrega os pares de valores-chave intermédios gerados pela função Map, processando-os para produzir a saída final. A função Reduce é aplicada a cada grupo de valores que partilham a mesma chave. A saída da função Reduce é gravada de volta no HDFS ou noutro sistema de armazenamento, dependendo do caso de utilização específico.
Vamos considerar um exemplo simples de cálculo de frequência de palavras usando MapReduce. Dado um grande conjunto de dados contendo documentos de texto, a função Map processa cada documento individualmente, contando as ocorrências de cada palavra e emitindo os pares palavra-frequência. Na fase Reduce, os pares de valores-chave intermédios gerados pela função Map são agregados por palavra e as frequências totais das palavras são calculadas, produzindo o resultado final.
O MapReduce também possui um mecanismo integrado de tolerância a falhas que pode reiniciar automaticamente tarefas com falha em outros nós disponíveis, garantindo que o processamento continue apesar da falha de nós individuais.
O AppMaster.io, uma poderosa plataforma sem código para o desenvolvimento de aplicações backend, Web e móveis, pode complementar as soluções de grandes volumes de dados baseadas no Hadoop. Com o AppMaster.io, pode criar aplicações Web e móveis que se integram perfeitamente com os componentes do Hadoop, como o HDFS e o MapReduce, para processar e analisar os dados gerados e armazenados pela sua arquitetura de grandes volumes de dados.
Ao tirar partido das vantagens do Hadoop e do AppMaster.io, as empresas podem criar poderosas aplicações de grandes volumes de dados que combinam a escalabilidade e a eficiência do Hadoop com a velocidade e a rentabilidade do desenvolvimento de aplicações no-code. AppMaster A interface intuitiva de arrastar e largar do .io e o designer visual de processos empresariais permitem-lhe criar aplicações rapidamente sem necessitar de conhecimentos profundos de codificação, o que resulta num tempo de colocação no mercado mais rápido e em custos de desenvolvimento reduzidos.
Além disso, uma vez que o AppMaster.io gera aplicações reais que podem ser implementadas no local ou na nuvem, pode manter o controlo total sobre os seus dados e a sua infraestrutura de aplicações. Esta flexibilidade permite-lhe criar uma solução abrangente de Big Data adaptada às suas necessidades específicas, independentemente da dimensão da sua organização ou do sector industrial.
A utilização do AppMaster.io em conjunto com o Hadoop para a arquitetura de grandes volumes de dados pode proporcionar inúmeras vantagens, incluindo um desenvolvimento de aplicações mais rápido, custos de desenvolvimento reduzidos e uma maior eficiência no processamento e análise de conjuntos de dados de grande escala. Ao aproveitar os pontos fortes de ambas as plataformas, as empresas podem criar aplicações de Big Data escaláveis que impulsionam o crescimento e fornecem informações valiosas.
A seleção da estratégia de implementação correcta para clusters Hadoop é crucial para garantir um desempenho e uma gestão ideais da sua infraestrutura de grandes volumes de dados. Existem três modelos de implantação principais para escolher ao configurar clusters do Hadoop:
Numa implementação no local, os clusters do Hadoop são configurados e geridos internamente, utilizando os próprios centros de dados da sua organização. Esta abordagem oferece várias vantagens, como o controlo da segurança física, a soberania dos dados e um ambiente conhecido para conformidade. Ainda assim, as implantações locais podem consumir muitos recursos, exigindo mais investimentos iniciais em hardware, manutenção e pessoal de TI. Além disso, o dimensionamento de recursos pode ser um desafio quando se depende apenas da infraestrutura física.
A implantação de clusters Hadoop com base na nuvem aproveita a escalabilidade, a flexibilidade e a economia das plataformas de nuvem, como Amazon Web Services (AWS), Google Cloud Platform (GCP) e Microsoft Azure. O fornecedor de serviços na nuvem assume a responsabilidade pela gestão da infraestrutura, permitindo que a sua equipa se concentre no processamento e análise de dados. As implementações baseadas na nuvem oferecem modelos de preços pay-as-you-go, o que significa que só paga pelos recursos que consome. Ainda assim, algumas organizações podem ter preocupações relativamente à segurança e conformidade dos dados quando confiam os seus dados a fornecedores terceiros de serviços na nuvem.
Uma estratégia de implementação híbrida combina os pontos fortes das implementações no local e baseadas na nuvem. Nesse modelo, os dados confidenciais e as cargas de trabalho regulamentadas podem permanecer no local, enquanto outras cargas de trabalho e dados podem ser transferidos para a nuvem para obter eficiência de custo e escalabilidade. Uma implementação híbrida permite que as organizações equilibrem as suas necessidades de controlo, segurança e flexibilidade, ao mesmo tempo que tiram partido das vantagens oferecidas pela computação em nuvem.
Cada modelo de implantação tem prós e contras, por isso é essencial considerar os requisitos de custo, escalabilidade, manutenção, segurança e conformidade ao escolher a estratégia mais adequada para o seu cluster Hadoop.
O Apache Hadoop é amplamente utilizado em todos os sectores para resolver vários desafios de Big Data, analisando grandes volumes de dados estruturados e não estruturados para extrair informações valiosas. Aqui estão algumas aplicações comuns do Hadoop na vida real:
O Apache Hadoop é uma solução poderosa e versátil para enfrentar os desafios dos grandes volumes de dados em vários sectores. Compreender os seus componentes, vantagens, estratégias de implementação e casos de utilização é essencial para as organizações que pretendem adotar esta tecnologia para armazenamento e processamento de dados em grande escala.
A combinação do Hadoop com outras abordagens de desenvolvimento modernas, como a plataforma no-codeAppMaster, oferece às empresas um ecossistema de processamento de dados abrangente, escalável e eficiente. Com a estratégia e o modelo de implementação correctos, a sua organização pode aproveitar o poder do Hadoop e capitalizar o potencial dos grandes volumes de dados para conduzir a uma melhor tomada de decisões, otimização e inovação.
O ditado de Theodore Levitt tem muito de verdade: "A inovação é como a faísca que dá vida à mudança, à melhoria e ao progresso." Quando combinamos Hadoop e AppMaster, é como capturar essa faísca. Esta dupla dinâmica leva as organizações a tomarem grandes decisões, a trabalharem de forma mais inteligente e a apresentarem novas ideias. Ao planear o seu caminho, lembre-se de que os megadados são como uma arca do tesouro de possibilidades de crescimento. E com as ferramentas certas, está a abrir a porta ao progresso e a tempos melhores.
O Apache Hadoop é uma estrutura de código aberto concebida para armazenar, processar e analisar eficientemente grandes volumes de dados. Inclui vários componentes que funcionam em conjunto para tratar vários aspectos dos grandes volumes de dados, como o HDFS (Hadoop Distributed File System) para armazenamento e o MapReduce para processamento. Na arquitetura de grandes volumes de dados, o Hadoop funciona como uma pedra angular, fornecendo a infraestrutura para gerir e obter informações a partir de conjuntos de dados maciços.
O Apache Hadoop aborda os desafios dos grandes volumes de dados através das suas capacidades de processamento distribuído e paralelo. Divide os dados em pedaços mais pequenos, que são processados em paralelo num cluster de máquinas interligadas. Esta abordagem melhora a escalabilidade, a tolerância a falhas e o desempenho, tornando viável o tratamento de tarefas de processamento e análise de dados em grande escala.
O Apache Hadoop utiliza o Hadoop Distributed File System (HDFS) para gerir o armazenamento de dados num cluster de máquinas. O HDFS divide os dados em blocos, replica-os para tolerância a falhas e distribui-os pelo cluster. Esta arquitetura de armazenamento distribuído garante uma elevada disponibilidade e fiabilidade.
O MapReduce é um modelo de programação e um motor de processamento no Hadoop que permite o processamento distribuído de dados. Divide as tarefas em duas fases: a fase "map" para processamento de dados e a fase "reduce" para agregação e resumo. O MapReduce permite que os programadores escrevam código que pode ser escalado num grande número de nós, tornando-o adequado para o processamento paralelo de grandes volumes de dados.
A integração do Apache Hadoop envolve a criação de um cluster Hadoop, que inclui vários nós responsáveis pelo armazenamento e processamento de dados. As organizações podem implementar o Hadoop juntamente com sistemas e ferramentas existentes, utilizando conectores e APIs para facilitar a troca de dados. Além disso, o Hadoop suporta vários métodos de ingestão de dados, tornando-o compatível com dados de várias fontes.
O Apache Hadoop continua a evoluir a par dos avanços nas tecnologias de grandes volumes de dados. Embora tenham surgido novas ferramentas e estruturas, o Hadoop continua a ser um componente fundamental de muitos ecossistemas de grandes volumes de dados. A sua robustez, flexibilidade e capacidade de lidar com diversos tipos de dados posicionam-no bem para futuros casos de utilização e desafios no mundo dos grandes volumes de dados.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


