Comprendre le système de fichiers distribués Hadoop (HDFS)
Le système de fichiers distribués Hadoop (HDFS) est l'un des composants fondamentaux du cadre Apache Hadoop. Il s'agit d'un système de fichiers distribué, tolérant aux pannes et évolutif, optimisé pour la gestion de gros volumes de données sur de grandes grappes de nœuds de calcul. HDFS est conçu pour les tâches de traitement de données par lots et est hautement optimisé pour les opérations de lecture en continu, ce qui le rend idéal pour une utilisation dans une architecture big data.
HDFS stocke les données sur plusieurs nœuds d'une grappe, la réplication des données étant une caractéristique essentielle pour garantir la tolérance aux pannes et la haute disponibilité. Le facteur de réplication par défaut est de 3, mais il peut être ajusté pour répondre aux besoins de stockage de données spécifiques et aux exigences de fiabilité. Les données sont divisées en blocs (par défaut, d'une taille de 128 Mo) et distribuées dans le cluster. Cela garantit que les données sont stockées et traitées aussi près que possible de leur source, ce qui réduit la latence du réseau et améliore les performances.
Principaux composants de HDFS
HDFS se compose de deux éléments principaux :
- NameNode: Le NameNode est le serveur principal de HDFS, responsable de la gestion de l'espace de noms, des métadonnées et de la santé du système de fichiers. Il maintient l'arborescence du système de fichiers et les métadonnées de tous les fichiers et répertoires, et assure la réplication des données et le rééquilibrage des blocs de données si nécessaire.
- DataNode: Les DataNodes sont des nœuds de travail au sein de l'architecture HDFS, responsables du stockage et de la gestion des blocs de données sur leurs dispositifs de stockage locaux. Les DataNodes communiquent avec le NameNode pour gérer les tâches de stockage et de réplication. Les données stockées sur ces DataNodes sont généralement réparties sur plusieurs disques, ce qui permet un parallélisme élevé dans les opérations de données.
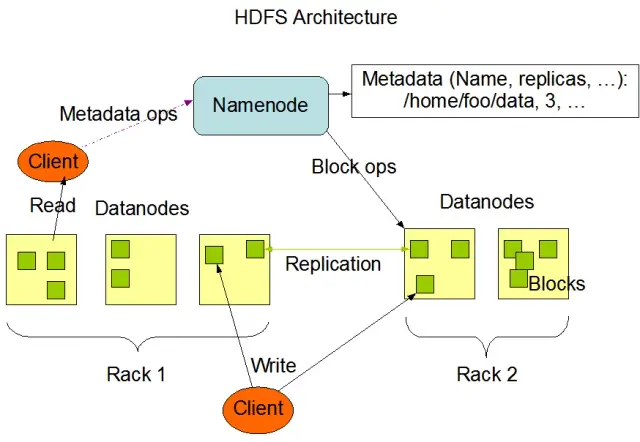
Source de l'image : Apache Hadoop
Opérations HDFS
HDFS fournit diverses opérations sur les fichiers et prend en charge les fonctions traditionnelles des systèmes de fichiers, telles que la création, la suppression et le renommage de fichiers et de répertoires. Les principales opérations sont les suivantes
- écrire, lire et supprimer des fichiers
- Créer et supprimer des répertoires
- Récupérer des métadonnées (telles que la taille des fichiers, l'emplacement des blocs et les temps d'accès)
- Définir et récupérer les autorisations et les quotas des utilisateurs
Les clients peuvent interagir avec HDFS en utilisant l'interface de ligne de commande Hadoop, les API Java ou les navigateurs HDFS basés sur le web.
MapReduce : Le moteur de traitement de Hadoop
MapReduce est un modèle de programmation et un composant central d'Apache Hadoop utilisé pour le traitement de données distribuées à grande échelle. Il permet aux développeurs d'écrire des programmes capables de traiter de grandes quantités de données en parallèle sur un grand nombre de nœuds. Le modèle MapReduce repose sur deux opérations clés : Map et Reduce.
Fonction Map
Lors de l'étape Map, les données d'entrée sont divisées en morceaux et la fonction Map traite chaque morceau en parallèle. La fonction prend des paires clé-valeur en entrée et génère des paires clé-valeur intermédiaires en sortie. Les paires en sortie sont triées par clé afin de les préparer pour l'étape Reduce.
Fonction Reduce
La fonction Reduce agrège les paires clé-valeur intermédiaires générées par la fonction Map, en les traitant de manière plus approfondie pour produire la sortie finale. La fonction Reduce est appliquée à chaque groupe de valeurs partageant la même clé. La sortie de la fonction Reduce est écrite dans HDFS ou dans un autre système de stockage, en fonction du cas d'utilisation spécifique.
Exemple MapReduce
Prenons un exemple simple de calcul de la fréquence des mots à l'aide de MapReduce. Étant donné un grand ensemble de données contenant des documents textuels, la fonction Map traite chaque document individuellement, en comptant les occurrences de chaque mot et en émettant les paires de fréquence de mots. Dans l'étape Reduce, les paires clé-valeur intermédiaires générées par la fonction Map sont agrégées par mot, et les fréquences totales des mots sont calculées, produisant le résultat final.
MapReduce dispose également d'un mécanisme intégré de tolérance aux pannes qui peut automatiquement relancer les tâches défaillantes sur d'autres nœuds disponibles, garantissant ainsi la poursuite du traitement malgré la défaillance de certains nœuds.
AppMaster.io, une puissante plateforme sans code pour le développement d'applications backend, web et mobiles, peut compléter les solutions Big Data basées sur Hadoop. Avec AppMaster.io, vous pouvez créer des applications web et mobiles qui s'intègrent de manière transparente aux composants Hadoop, tels que HDFS et MapReduce, pour traiter et analyser les données générées et stockées par votre architecture big data.
En tirant parti des avantages d'Hadoop et de AppMaster.io, les entreprises peuvent créer de puissantes applications big data qui combinent l'évolutivité et l'efficacité d'Hadoop avec la rapidité et la rentabilité du développement d'applications no-code. AppMaster L'interface intuitive " glisser-déposer " de .io et le concepteur visuel de processus d'entreprise vous permettent de créer des applications rapidement sans avoir besoin d'une expertise approfondie en matière de codage, ce qui se traduit par une mise sur le marché plus rapide et des coûts de développement réduits.

De plus, comme AppMaster.io génère des applications réelles qui peuvent être déployées sur site ou dans le nuage, vous pouvez garder le contrôle total de vos données et de votre infrastructure d'application. Cette flexibilité vous permet de créer une solution big data complète adaptée à vos besoins spécifiques, indépendamment de la taille de votre organisation ou de votre secteur d'activité.
L'utilisation de AppMaster.io en conjonction avec Hadoop pour l'architecture big data peut offrir de nombreux avantages, notamment un développement d'applications plus rapide, des coûts de développement réduits et une efficacité accrue dans le traitement et l'analyse d'ensembles de données à grande échelle. En tirant parti des atouts des deux plateformes, les entreprises peuvent créer des applications big data évolutives qui stimulent la croissance et fournissent des informations précieuses.
Stratégies de déploiement des clusters Hadoop
Le choix de la bonne stratégie de déploiement pour les clusters Hadoop est crucial pour garantir des performances et une gestion optimales de votre infrastructure big data. Il existe trois principaux modèles de déploiement pour la mise en place de clusters Hadoop :
Déploiement sur site
Dans le cadre d'un déploiement sur site, les clusters Hadoop sont configurés et gérés en interne, en utilisant les centres de données de votre entreprise. Cette approche offre plusieurs avantages, tels que le contrôle de la sécurité physique, la souveraineté des données et un environnement connu pour la conformité. Toutefois, les déploiements sur site peuvent être gourmands en ressources, car ils nécessitent un investissement initial plus important en termes de matériel, de maintenance et de personnel informatique. En outre, l'extension des ressources peut être difficile à réaliser si l'on s'appuie uniquement sur l'infrastructure physique.
Déploiement dans le nuage
Le déploiement de clusters Hadoop dans le nuage tire parti de l'évolutivité, de la flexibilité et de la rentabilité des plateformes en nuage, telles qu' Amazon Web Services (AWS), Google Cloud Platform (GCP) et Microsoft Azure. Le fournisseur de services en nuage prend en charge la gestion de l'infrastructure, ce qui permet à votre équipe de se concentrer sur le traitement et l'analyse des données. Les déploiements basés sur le cloud offrent des modèles de tarification "pay-as-you-go", ce qui signifie que vous ne payez que pour les ressources que vous consommez. Toutefois, certaines organisations peuvent s'inquiéter de la sécurité et de la conformité des données lorsqu'elles les confient à des fournisseurs de services en nuage tiers.
Déploiement hybride
Une stratégie de déploiement hybride combine les points forts des déploiements sur site et dans le nuage. Dans ce modèle, les données sensibles et les charges de travail réglementées peuvent rester sur site, tandis que d'autres charges de travail et données peuvent être transférées dans le nuage pour des raisons de rentabilité et d'évolutivité. Un déploiement hybride permet aux entreprises d'équilibrer leurs besoins en matière de contrôle, de sécurité et de flexibilité tout en profitant des avantages offerts par l'informatique en nuage.
Chaque modèle de déploiement présente des avantages et des inconvénients. Il est donc essentiel de tenir compte des coûts, de l'évolutivité, de la maintenance, de la sécurité et des exigences de conformité lors du choix de la stratégie la plus adaptée à votre cluster Hadoop.
Cas d'utilisation : Hadoop dans les applications réelles
Apache Hadoop est largement utilisé dans tous les secteurs d'activité pour relever divers défis liés au big data, en analysant de grands volumes de données structurées et non structurées afin d'en extraire des informations précieuses. Voici quelques applications courantes d'Hadoop dans la vie réelle :
- Analyse des logs et des flux de clics : Hadoop peut traiter de grands volumes de logs de serveurs et d'applications, ainsi que des données de flux de clics générées par les utilisateurs de sites web. L'analyse de ces données peut aider les entreprises à comprendre le comportement des utilisateurs, à optimiser leur expérience et à résoudre les problèmes de performance.
- Moteurs de recommandation : Les plateformes de commerce électronique et les fournisseurs de contenu utilisent Hadoop pour analyser les habitudes de navigation et d'achat des clients afin de générer des recommandations personnalisées de produits, de services ou de contenus. La capacité d'Hadoop à traiter des ensembles massifs de données et à effectuer des calculs complexes en fait une solution idéale pour les moteurs de recommandation.
- Détection des fraudes : Les services financiers et les compagnies d'assurance s'appuient sur Hadoop pour analyser les données de transaction et détecter les schémas anormaux indiquant une fraude. Les capacités de traitement parallèle et évolutif d'Hadoop permettent aux entreprises d'identifier et d'atténuer rapidement les risques de fraude potentiels.
- Analyse des réseaux sociaux : Hadoop peut traiter de grands volumes de données de médias sociaux, y compris les profils d'utilisateurs, les interactions et le partage de contenu, afin de dévoiler des tendances et des informations sur le comportement humain, l'analyse des sentiments et les stratégies de marketing.
- Apprentissage automatique et analyse prédictive : Hadoop accélère l'apprentissage automatique et l'analyse prédictive en parallélisant les algorithmes coûteux en calcul sur de grands ensembles de données. Les entreprises peuvent utiliser les capacités d'Hadoop pour développer des modèles prédictifs afin de prévoir la demande, le taux de désabonnement des clients et d'autres mesures critiques.
- Augmentation de l'entrepôt de données : Hadoop peut être intégré aux systèmes traditionnels d'entrepôt de données, ce qui permet de décharger certaines charges de travail, telles que les processus d'extraction, de transformation et de chargement (ETL), et d'améliorer les performances. Cette approche peut aider les entreprises à réduire les coûts, à alléger la charge sur l'infrastructure existante et à améliorer leurs capacités d'analyse.
Conclusion
Apache Hadoop est une solution puissante et polyvalente pour relever les défis du big data dans divers secteurs d'activité. La compréhension de ses composants, de ses avantages, de ses stratégies de déploiement et de ses cas d'utilisation est essentielle pour les organisations qui souhaitent adopter cette technologie pour le stockage et le traitement de données à grande échelle.
La combinaison d'Hadoop avec d'autres approches de développement modernes, comme la plateforme no-codeAppMaster, offre aux entreprises un écosystème de traitement des données complet, évolutif et efficace. Avec la bonne stratégie et le bon modèle de déploiement, votre organisation peut exploiter la puissance de Hadoop et capitaliser sur le potentiel du big data pour améliorer la prise de décision, l'optimisation et l'innovation.
Le dicton de Theodore Levitt est très juste : "L'innovation est comme l'étincelle qui donne vie au changement, à l'amélioration et au progrès". Lorsque nous combinons Hadoop et AppMaster, c'est comme si nous capturions cette étincelle. Ce duo dynamique pousse les organisations à prendre des décisions importantes, à travailler plus intelligemment et à trouver de nouvelles idées. Lorsque vous planifiez votre parcours, n'oubliez pas que le big data est un véritable coffre aux trésors qui offre de nombreuses possibilités de croissance. Et avec les bons outils, vous ouvrez la porte au progrès et à des temps meilleurs.






