
تطبيق حجز المعدات: امنع التعارضات وتتبع الإرجاعات
خطط لتطبيق لحجز المعدات يمنع الحجوزات المزدوجة، ويسجل الإرجاعات والأضرار، ويضع العناصر المعطلة قيد الصيانة.
استكشف أساسيات Apache Hadoop ودورها في بنية البيانات الضخمة ، بما في ذلك مكوناتها وفوائدها واستراتيجيات النشر. تعرف على كيفية ملاءمتها للنظم البيئية الحديثة للبيانات وتسهيل المعالجة على نطاق واسع. </ h2>

يعد نظام الملفات الموزعة Hadoop (HDFS) أحد المكونات الأساسية لإطار عمل Apache Hadoop. إنه نظام ملفات موزع ومتحمل للأخطاء وقابل للتطوير محسّن لإدارة كميات كبيرة من البيانات عبر مجموعات كبيرة من عقد الحوسبة. تم تصميم HDFS لاستيعاب مهام معالجة البيانات المجمعة وهو مُحسّن للغاية لعمليات القراءة الكبيرة المتدفقة ، مما يجعله مثاليًا للاستخدام في هندسة البيانات الضخمة.
يخزن HDFS البيانات عبر عقد متعددة في مجموعة ، مع تكرار البيانات كميزة رئيسية لضمان التسامح مع الخطأ والتوافر العالي. عامل النسخ الافتراضي هو 3 ، ولكن يمكن تعديله لتلبية احتياجات تخزين البيانات المحددة ومتطلبات الموثوقية. يتم تقسيم البيانات إلى كتل (افتراضيًا ، حجمها 128 ميجابايت) وتوزيعها عبر الكتلة. يضمن ذلك تخزين البيانات ومعالجتها في أقرب مكان ممكن من مصدرها ، مما يقلل من زمن انتقال الشبكة ويحسن الأداء.
هناك نوعان من المكونات الأساسية لـ HDFS:
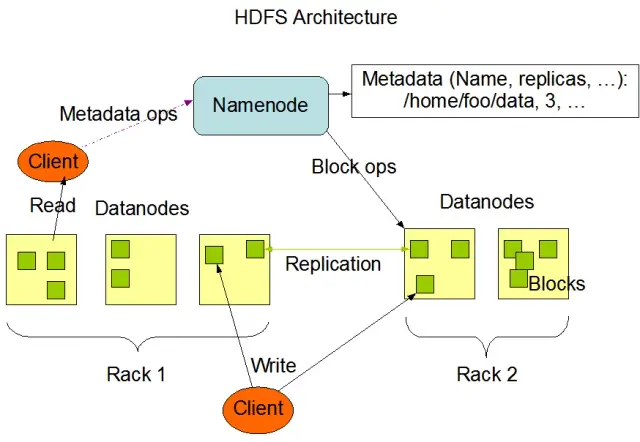
مصدر الصورة: اباتشي هادوب
يوفر HDFS عمليات ملفات متنوعة ويدعم ميزات نظام الملفات التقليدية ، مثل إنشاء الملفات والدلائل وحذفها وإعادة تسميتها. تشمل العمليات الأولية ما يلي:
يمكن للعملاء التفاعل مع HDFS باستخدام واجهة سطر أوامر Hadoop أو Java APIs أو متصفحات HDFS القائمة على الويب.
MapReduce هو نموذج برمجة ومكون أساسي في Apache Hadoop يستخدم لمعالجة البيانات الموزعة على نطاق واسع. يسمح للمطورين بكتابة برامج يمكنها معالجة كميات هائلة من البيانات بالتوازي عبر عدد كبير من العقد. يعتمد نموذج MapReduce على عمليتين أساسيتين: Map و Reduce.
في مرحلة الخريطة ، يتم تقسيم بيانات الإدخال إلى أجزاء ، وتعالج وظيفة الخريطة كل جزء على التوازي. تأخذ الوظيفة أزواج المفتاح والقيمة كمدخلات وتولد أزواجًا وسيطة من المفاتيح والقيمة كمخرجات. يتم فرز أزواج الإخراج حسب المفتاح لإعدادهم لمرحلة التخفيض.
تقوم مرحلة التخفيض بتجميع أزواج القيمة الرئيسية الوسيطة التي تم إنشاؤها بواسطة وظيفة الخريطة ، ومعالجتها بشكل أكبر لإنتاج الناتج النهائي. يتم تطبيق وظيفة Reduce على كل مجموعة من القيم التي تشترك في نفس المفتاح. تتم إعادة إخراج وظيفة Reduce إلى HDFS أو أي نظام تخزين آخر ، اعتمادًا على حالة الاستخدام المحددة.
لنفكر في مثال بسيط لحساب تكرار الكلمات باستخدام MapReduce. بالنظر إلى مجموعة بيانات كبيرة تحتوي على مستندات نصية ، تعالج وظيفة الخريطة كل مستند على حدة ، وتحسب تكرارات كل كلمة وتنبعث أزواج تكرار الكلمات. في مرحلة التصغير ، يتم تجميع أزواج القيمة الرئيسية الوسيطة التي تم إنشاؤها بواسطة وظيفة الخريطة بالكلمات ، ويتم حساب إجمالي تكرارات الكلمات ، مما ينتج عنه الإخراج النهائي.
يحتوي MapReduce أيضًا على آلية مضمنة للتسامح مع الخطأ يمكنها إعادة تشغيل المهام الفاشلة تلقائيًا على العقد الأخرى المتاحة ، مما يضمن استمرار المعالجة على الرغم من فشل العقد الفردية.
يمكن لـ AppMaster.io ، وهو نظام أساسي قوي لا يحتوي على تعليمات برمجية لتطوير التطبيقات الخلفية والويب والجوال ، أن يكمل حلول البيانات الضخمة المستندة إلى Hadoop. باستخدام AppMaster.io ، يمكنك إنشاء تطبيقات الويب والجوّال التي تتكامل بسلاسة مع مكونات Hadoop ، مثل HDFS و MapReduce ، لمعالجة وتحليل البيانات التي تم إنشاؤها وتخزينها بواسطة بنية البيانات الضخمة الخاصة بك.
من خلال الاستفادة من مزايا كل من Hadoop و AppMaster.io ، يمكن للشركات إنشاء تطبيقات قوية للبيانات الضخمة تجمع بين قابلية التوسع وكفاءة Hadoop مع السرعة والفعالية من حيث التكلفة لتطوير التطبيقات no-code. تتيح لك واجهة السحب والإفلات البديهية الخاصة بـ AppMaster.io ومصمم عمليات الأعمال المرئية إنشاء التطبيقات بسرعة دون الحاجة إلى خبرة ترميز متعمقة ، مما يؤدي إلى تسريع وقت التسويق وتقليل تكاليف التطوير.
علاوة على ذلك ، نظرًا لأن AppMaster.io ينشئ تطبيقات حقيقية يمكن نشرها محليًا أو في السحابة ، يمكنك الحفاظ على التحكم الكامل في البيانات والبنية الأساسية للتطبيق. تتيح لك هذه المرونة إنشاء حل شامل للبيانات الضخمة مصمم خصيصًا لاحتياجاتك الخاصة ، بغض النظر عن حجم مؤسستك أو قطاع الصناعة.
يمكن أن يوفر استخدام AppMaster.io جنبًا إلى جنب مع Hadoop لهندسة البيانات الضخمة مزايا عديدة ، بما في ذلك تطوير التطبيقات بشكل أسرع ، وتقليل تكاليف التطوير ، وزيادة الكفاءة في معالجة وتحليل مجموعات البيانات واسعة النطاق. من خلال الاستفادة من نقاط القوة في كلا النظامين الأساسيين ، يمكن للشركات إنشاء تطبيقات بيانات ضخمة قابلة للتطوير تدفع النمو وتقدم رؤى قيمة.
يعد تحديد إستراتيجية النشر الصحيحة لمجموعات Hadoop أمرًا بالغ الأهمية لضمان الأداء الأمثل وإدارة البنية التحتية للبيانات الضخمة الخاصة بك. هناك ثلاثة نماذج نشر أساسية للاختيار من بينها عند إعداد مجموعات Hadoop:
في النشر المحلي ، يتم إعداد مجموعات Hadoop وإدارتها داخليًا ، باستخدام مراكز البيانات الخاصة بمؤسستك. يوفر هذا النهج العديد من المزايا ، مثل التحكم في الأمان المادي ، وسيادة البيانات ، وبيئة معروفة للامتثال. ومع ذلك ، يمكن أن تكون عمليات النشر في أماكن العمل كثيفة الاستخدام للموارد ، وتتطلب المزيد من الاستثمار المسبق في الأجهزة ، والصيانة ، وموظفي تكنولوجيا المعلومات. أيضًا ، يمكن أن يكون توسيع نطاق الموارد أمرًا صعبًا عند الاعتماد على البنية التحتية المادية وحدها.
يعمل نشر مجموعات Hadoop المستند إلى السحابة على زيادة قابلية التوسع والمرونة وكفاءة التكلفة للأنظمة الأساسية السحابية ، مثل Amazon Web Services (AWS) و Google Cloud Platform (GCP) و Microsoft Azure . يتحمل موفر الخدمة السحابية مسؤولية إدارة البنية التحتية ، مما يسمح لفريقك بالتركيز على معالجة البيانات وتحليلها. تقدم عمليات النشر المستندة إلى السحابة نماذج تسعير الدفع أولاً بأول ، مما يعني أنك تدفع فقط مقابل الموارد التي تستهلكها. ومع ذلك ، قد يكون لدى بعض المؤسسات مخاوف بشأن أمان البيانات والامتثال عند تكليف بياناتها بموفري الخدمات السحابية الخارجيين.
تجمع إستراتيجية النشر المختلطة بين نقاط القوة لكل من عمليات النشر المحلية والقائمة على السحابة. في هذا النموذج ، يمكن أن تظل البيانات الحساسة وأعباء العمل المنظمة في أماكن العمل ، بينما يمكن تفريغ أحمال العمل والبيانات الأخرى في السحابة لتحقيق الكفاءة من حيث التكلفة وقابلية التوسع. يتيح النشر المختلط للمؤسسات تحقيق التوازن بين احتياجاتها للتحكم والأمان والمرونة مع الاستفادة من المزايا التي توفرها الحوسبة السحابية.
يحتوي كل نموذج نشر على مزايا وعيوب ، لذلك من الضروري مراعاة متطلبات التكلفة وقابلية التوسع والصيانة والأمان والامتثال عند اختيار الإستراتيجية الأنسب لمجموعة Hadoop الخاصة بك.
يستخدم Apache Hadoop على نطاق واسع عبر الصناعات لمواجهة تحديات البيانات الضخمة المختلفة ، وتحليل كميات كبيرة من البيانات المهيكلة وغير المهيكلة لاستخراج رؤى قيمة. فيما يلي بعض التطبيقات الواقعية الشائعة لـ Hadoop:
Apache Hadoop هو حل قوي ومتعدد الاستخدامات لمواجهة تحديات البيانات الضخمة في مختلف الصناعات. يعد فهم مكوناتها وفوائدها واستراتيجيات النشر وحالات الاستخدام أمرًا ضروريًا للمؤسسات التي تسعى إلى اعتماد هذه التقنية لتخزين البيانات ومعالجتها على نطاق واسع.
يوفر الجمع بين Hadoop وأساليب التطوير الحديثة الأخرى ، مثل منصة AppMasterno-code ، للشركات نظامًا بيئيًا شاملاً وقابلًا للتطوير وفعالًا لمعالجة البيانات. مع الإستراتيجية الصحيحة ونموذج النشر ، يمكن لمؤسستك تسخير قوة Hadoop والاستفادة من إمكانات البيانات الضخمة لدفع عملية صنع القرار والتحسين والابتكار بشكل أفضل.
القول المأثور من ثيودور ليفيت يحمل الكثير من الحقيقة: "الابتكار مثل الشرارة التي تجلب التغيير والتحسين والتقدم إلى الحياة". عندما نجمع بين Hadoop و AppMaster ، فإن الأمر يشبه التقاط تلك الشرارة. يدفع هذا الثنائي الديناميكي المؤسسات لاتخاذ قرارات كبيرة والعمل بذكاء والتوصل إلى أفكار جديدة. أثناء التخطيط لمسارك ، تذكر أن البيانات الضخمة مثل كنز من احتمالات النمو. وباستخدام الأدوات المناسبة ، فإنك تفتح الباب للتقدم وأوقات أفضل.
Apache Hadoop هو إطار عمل مفتوح المصدر مصمم لتخزين ومعالجة وتحليل كميات كبيرة من البيانات بكفاءة. وهو يتألف من مكونات متعددة تعمل معًا للتعامل مع جوانب مختلفة من البيانات الضخمة ، مثل نظام الملفات الموزعة Hadoop (HDFS) للتخزين و MapReduce للمعالجة. في بنية البيانات الضخمة ، يعمل Hadoop كحجر زاوية ، حيث يوفر البنية التحتية لإدارة واستخلاص الرؤى من مجموعات البيانات الضخمة.
يعالج Apache Hadoop تحديات البيانات الضخمة من خلال قدرات المعالجة الموزعة والمتوازية. يقوم بتقسيم البيانات إلى أجزاء أصغر ، والتي تتم معالجتها بالتوازي عبر مجموعة من الأجهزة المترابطة. يعمل هذا النهج على تحسين قابلية التوسع والتسامح مع الأخطاء والأداء ، مما يجعل من الممكن التعامل مع مهام معالجة البيانات وتحليلها على نطاق واسع.
يستخدم Apache Hadoop نظام الملفات الموزعة Hadoop (HDFS) لإدارة تخزين البيانات عبر مجموعة من الأجهزة. يقوم HDFS بتقسيم البيانات إلى كتل ، وتكرارها للتسامح مع الخطأ ، وتوزيعها عبر الكتلة. تضمن بنية التخزين الموزعة هذه توفرًا وموثوقية عالية.
MapReduce هو نموذج برمجة ومحرك معالجة داخل Hadoop يتيح معالجة البيانات الموزعة. يقسم المهام إلى مرحلتين: مرحلة "الخريطة" لمعالجة البيانات ومرحلة "تقليل" للتجميع والتلخيص. يسمح MapReduce للمطورين بكتابة التعليمات البرمجية التي تتدرج عبر عدد كبير من العقد ، مما يجعلها مناسبة للمعالجة المتوازية للبيانات الضخمة.
يتضمن دمج Apache Hadoop إنشاء مجموعة Hadoop ، والتي تضم عدة عقد مسؤولة عن تخزين البيانات ومعالجتها. يمكن للمؤسسات نشر Hadoop جنبًا إلى جنب مع الأنظمة والأدوات الحالية ، باستخدام الموصلات وواجهات برمجة التطبيقات لتسهيل تبادل البيانات. بالإضافة إلى ذلك ، يدعم Hadoop طرقًا مختلفة لاستيعاب البيانات ، مما يجعله متوافقًا مع البيانات من مصادر مختلفة.
يستمر Apache Hadoop في التطور جنبًا إلى جنب مع التطورات في تقنيات البيانات الضخمة. بينما ظهرت أدوات وأطر عمل أحدث ، لا يزال Hadoop مكونًا أساسيًا للعديد من أنظمة البيانات الضخمة. إن قوتها ومرونتها وقدرتها على التعامل مع أنواع البيانات المتنوعة تجعلها مناسبة لحالات الاستخدام المستقبلية والتحديات في عالم البيانات الضخمة.



تجربة مع AppMaster مع خطة مجانية.
عندما تكون جاهزًا ، يمكنك اختيار الاشتراك المناسب.


