
Aplikasi pemesanan peralatan: cegah konflik dan lacak pengembalian
Rencanakan aplikasi pemesanan peralatan yang mencegah pemesanan ganda, mencatat pengembalian dan kerusakan, serta menahan item bermasalah untuk pemeliharaan.
Jelajahi dasar-dasar Apache Hadoop dan perannya dalam arsitektur big data, termasuk komponen, manfaat, dan strategi penerapannya. Pelajari bagaimana ini sesuai dengan ekosistem data modern dan memfasilitasi pemrosesan skala besar.

Hadoop Distributed File System (HDFS) adalah salah satu komponen fundamental dari framework Apache Hadoop. Ini adalah sistem file yang terdistribusi, toleran terhadap kesalahan, dan dapat diskalakan yang dioptimalkan untuk mengelola volume data yang besar di seluruh kelompok besar node komputasi. HDFS dirancang untuk mengakomodasi tugas pemrosesan data batch dan sangat dioptimalkan untuk operasi baca streaming yang besar, menjadikannya ideal untuk digunakan dalam arsitektur data besar.
HDFS menyimpan data di beberapa node dalam sebuah cluster, dengan replikasi data sebagai fitur utama untuk memastikan toleransi kesalahan dan ketersediaan yang tinggi. Faktor replikasi default adalah 3, tetapi dapat disesuaikan untuk memenuhi kebutuhan penyimpanan data spesifik dan persyaratan keandalan. Data dibagi menjadi beberapa blok (secara default, berukuran 128 MB) dan didistribusikan ke seluruh cluster. Ini memastikan data disimpan dan diproses sedekat mungkin dengan sumbernya, mengurangi latensi jaringan dan meningkatkan kinerja.
Ada dua komponen utama HDFS:
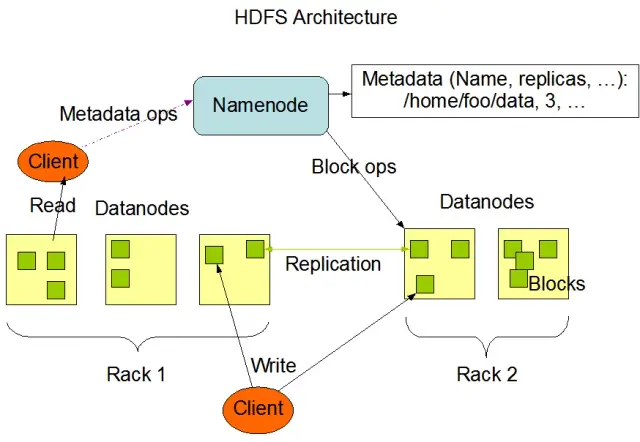
Sumber gambar: Apache Hadoop
HDFS menyediakan berbagai operasi file dan mendukung fitur sistem file tradisional, seperti membuat, menghapus, dan mengganti nama file dan direktori. Operasi utama meliputi:
Klien dapat berinteraksi dengan HDFS menggunakan antarmuka baris perintah Hadoop, API Java, atau browser HDFS berbasis web.
MapReduce adalah model pemrograman dan komponen inti dari Apache Hadoop yang digunakan untuk pemrosesan data terdistribusi berskala besar. Ini memungkinkan pengembang untuk menulis program yang dapat memproses sejumlah besar data secara paralel di sejumlah besar node. Model MapReduce didasarkan pada dua operasi utama: Map dan Reduce.
Pada tahap Peta, data input dibagi menjadi potongan-potongan, dan fungsi Peta memproses setiap potongan secara paralel. Fungsi mengambil pasangan nilai kunci sebagai masukan dan menghasilkan pasangan nilai kunci perantara sebagai keluaran. Pasangan output diurutkan berdasarkan kunci untuk menyiapkannya pada tahap Reduce.
Tahap Pengurangan menggabungkan pasangan nilai kunci menengah yang dihasilkan oleh fungsi Peta, memprosesnya lebih lanjut untuk menghasilkan hasil akhir. Fungsi Reduce diterapkan ke setiap grup nilai yang berbagi kunci yang sama. Output dari fungsi Reduce ditulis kembali ke HDFS atau sistem penyimpanan lain, tergantung pada kasus penggunaan tertentu.
Mari pertimbangkan contoh sederhana menghitung frekuensi kata menggunakan MapReduce. Mengingat kumpulan data besar yang berisi dokumen teks, fungsi Peta memproses setiap dokumen secara individual, menghitung kemunculan setiap kata dan menampilkan pasangan frekuensi kata. Pada tahap Reduce, pasangan kunci-nilai antara yang dihasilkan oleh fungsi Map diagregasikan berdasarkan kata, dan total frekuensi kata dihitung, menghasilkan keluaran akhir.
MapReduce juga memiliki mekanisme toleransi kesalahan bawaan yang dapat secara otomatis memulai ulang tugas yang gagal pada node lain yang tersedia, memastikan pemrosesan terus berlanjut meskipun ada kegagalan pada masing-masing node.
AppMaster.io , platform tanpa kode yang andal untuk mengembangkan aplikasi backend, web, dan seluler, dapat melengkapi solusi big data berbasis Hadoop. Dengan AppMaster.io, Anda dapat membuat aplikasi web dan seluler yang terintegrasi secara mulus dengan komponen Hadoop, seperti HDFS dan MapReduce, untuk memproses dan menganalisis data yang dihasilkan dan disimpan oleh arsitektur big data Anda.
Dengan memanfaatkan keunggulan Hadoop dan AppMaster.io, bisnis dapat membuat aplikasi data besar yang kuat yang menggabungkan skalabilitas dan efisiensi Hadoop dengan kecepatan dan efektivitas biaya pengembangan aplikasi no-code. Antarmuka drag-and-drop AppMaster.io yang intuitif dan perancang proses bisnis visual memungkinkan Anda membangun aplikasi dengan cepat tanpa memerlukan keahlian pengkodean yang mendalam, menghasilkan waktu pemasaran yang lebih cepat dan biaya pengembangan yang lebih rendah.
Selain itu, karena AppMaster.io menghasilkan aplikasi nyata yang dapat diterapkan di tempat atau di cloud, Anda dapat mempertahankan kontrol penuh atas data dan infrastruktur aplikasi Anda. Fleksibilitas ini memungkinkan Anda membuat solusi data besar yang komprehensif yang disesuaikan dengan kebutuhan khusus Anda, terlepas dari ukuran organisasi atau sektor industri Anda.
Menggunakan AppMaster.io bersama dengan Hadoop untuk arsitektur data besar dapat memberikan banyak keuntungan, termasuk pengembangan aplikasi yang lebih cepat, pengurangan biaya pengembangan , dan peningkatan efisiensi dalam pemrosesan dan analisis kumpulan data berskala besar. Dengan memanfaatkan kekuatan kedua platform, bisnis dapat membangun aplikasi data besar yang dapat diskalakan yang mendorong pertumbuhan dan memberikan wawasan yang berharga.
Memilih strategi penerapan yang tepat untuk klaster Hadoop sangat penting untuk memastikan performa optimal dan pengelolaan infrastruktur big data Anda. Ada tiga model penerapan utama yang dapat dipilih saat menyiapkan klaster Hadoop:
Dalam penerapan di lokasi, klaster Hadoop disiapkan dan dikelola secara internal, memanfaatkan pusat data organisasi Anda sendiri. Pendekatan ini menawarkan beberapa keunggulan, seperti kontrol atas keamanan fisik, kedaulatan data, dan lingkungan yang dikenal untuk kepatuhan. Namun, penerapan di lokasi dapat menjadi padat sumber daya, membutuhkan lebih banyak investasi di muka untuk perangkat keras, pemeliharaan, dan personel TI. Selain itu, penskalaan sumber daya dapat menjadi tantangan jika hanya mengandalkan infrastruktur fisik.
Penerapan klaster Hadoop berbasis cloud memanfaatkan skalabilitas, fleksibilitas, dan efisiensi biaya platform cloud, seperti Amazon Web Services (AWS) , Google Cloud Platform (GCP), dan Microsoft Azure . Penyedia layanan cloud bertanggung jawab atas manajemen infrastruktur, memungkinkan tim Anda untuk fokus pada pemrosesan dan analisis data. Penyebaran berbasis cloud menawarkan model penetapan harga sesuai penggunaan, artinya Anda hanya membayar untuk sumber daya yang Anda konsumsi. Namun, beberapa organisasi mungkin memiliki kekhawatiran atas keamanan dan kepatuhan data saat mempercayakan data mereka ke penyedia cloud pihak ketiga.
Strategi penerapan hybrid menggabungkan kekuatan penerapan lokal dan berbasis cloud. Dalam model ini, data sensitif dan beban kerja yang diatur dapat tetap berada di lokasi, sementara beban kerja dan data lainnya dapat dipindahkan ke cloud untuk efisiensi biaya dan skalabilitas. Penerapan hybrid memungkinkan organisasi untuk menyeimbangkan kebutuhan mereka akan kontrol, keamanan, dan fleksibilitas sambil memanfaatkan manfaat yang ditawarkan oleh komputasi awan.
Setiap model penerapan memiliki pro dan kontra, jadi penting untuk mempertimbangkan persyaratan biaya, skalabilitas, pemeliharaan, keamanan, dan kepatuhan saat memilih strategi yang paling cocok untuk klaster Hadoop Anda.
Apache Hadoop banyak digunakan di berbagai industri untuk mengatasi berbagai tantangan big data, menganalisis data terstruktur dan tidak terstruktur dalam jumlah besar untuk mendapatkan wawasan yang berharga. Berikut adalah beberapa aplikasi umum Hadoop di kehidupan nyata:
Apache Hadoop adalah solusi yang kuat dan serbaguna untuk mengatasi tantangan big data di berbagai industri. Memahami komponen, manfaat, strategi penerapan, dan kasus penggunaannya sangat penting bagi organisasi yang ingin mengadopsi teknologi ini untuk penyimpanan dan pemrosesan data berskala besar.
Menggabungkan Hadoop dengan pendekatan pengembangan modern lainnya, seperti platform AppMasterno-code, menawarkan bisnis ekosistem pemrosesan data yang komprehensif, terukur, dan efisien. Dengan strategi dan model penerapan yang tepat, organisasi Anda dapat memanfaatkan kekuatan Hadoop dan memanfaatkan potensi big data untuk mendorong pengambilan keputusan, pengoptimalan, dan inovasi yang lebih baik.
Ungkapan Theodore Levitt mengandung banyak kebenaran: "Inovasi itu seperti percikan api yang membawa perubahan, peningkatan, dan kemajuan dalam hidup." Saat kami menggabungkan Hadoop dan AppMaster, ini seperti menangkap percikan itu. Duo dinamis ini mendorong organisasi untuk membuat keputusan besar, bekerja lebih cerdas, dan memunculkan ide-ide segar. Saat Anda merencanakan jalan Anda, ingatlah bahwa data besar seperti peti harta karun kemungkinan untuk berkembang. Dan dengan alat yang tepat, Anda membuka pintu menuju kemajuan dan waktu yang lebih baik.
Apache Hadoop adalah kerangka kerja sumber terbuka yang dirancang untuk menyimpan, memproses, dan menganalisis data dalam jumlah besar secara efisien. Ini terdiri dari beberapa komponen yang bekerja sama untuk menangani berbagai aspek big data, seperti Hadoop Distributed File System (HDFS) untuk penyimpanan dan MapReduce untuk pemrosesan. Dalam arsitektur data besar, Hadoop bertindak sebagai landasan, menyediakan infrastruktur untuk mengelola dan memperoleh wawasan dari kumpulan data besar.
Apache Hadoop mengatasi tantangan big data melalui kemampuan pemrosesan terdistribusi dan paralelnya. Itu memecah data menjadi potongan-potongan kecil, yang diproses secara paralel di sekelompok mesin yang saling berhubungan. Pendekatan ini meningkatkan skalabilitas, toleransi kesalahan, dan kinerja, membuatnya layak untuk menangani pemrosesan data skala besar dan tugas analisis.
Apache Hadoop menggunakan Hadoop Distributed File System (HDFS) untuk mengelola penyimpanan data di berbagai mesin. HDFS memecah data menjadi blok, mereplikasinya untuk toleransi kesalahan, dan mendistribusikannya ke seluruh cluster. Arsitektur penyimpanan terdistribusi ini memastikan ketersediaan dan keandalan yang tinggi.
MapReduce adalah model pemrograman dan mesin pemrosesan dalam Hadoop yang memungkinkan pemrosesan data terdistribusi. Ini membagi tugas menjadi dua fase: fase "peta" untuk pemrosesan data dan fase "perkecil" untuk agregasi dan peringkasan. MapReduce memungkinkan pengembang untuk menulis kode yang menskalakan sejumlah besar node, sehingga cocok untuk pemrosesan data besar secara paralel.
Mengintegrasikan Apache Hadoop melibatkan pengaturan cluster Hadoop, yang terdiri dari beberapa node yang bertanggung jawab untuk penyimpanan dan pemrosesan data. Organisasi dapat menerapkan Hadoop bersama sistem dan alat yang ada, menggunakan konektor dan API untuk memfasilitasi pertukaran data. Selain itu, Hadoop mendukung berbagai metode penyerapan data, membuatnya kompatibel dengan data dari berbagai sumber.
Apache Hadoop terus berkembang seiring kemajuan dalam teknologi data besar. Sementara alat dan kerangka kerja yang lebih baru telah muncul, Hadoop tetap menjadi komponen fundamental dari banyak ekosistem big data. Ketangguhan, fleksibilitas, dan kemampuannya untuk menangani beragam jenis data menempatkannya dengan baik untuk kasus penggunaan dan tantangan di masa mendatang dalam dunia data besar.



Eksperimen dengan AppMaster dengan paket gratis.
Saat Anda siap, Anda dapat memilih langganan yang tepat.


