
সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
Apache Hadoop এর মৌলিক বিষয়গুলি এবং এর উপাদান, সুবিধা এবং স্থাপনার কৌশল সহ বড় ডেটা আর্কিটেকচারে এর ভূমিকা অন্বেষণ করুন। শিখুন কিভাবে এটি আধুনিক ডেটা ইকোসিস্টেমের সাথে ফিট করে এবং বড় আকারের প্রক্রিয়াকরণের সুবিধা দেয়৷

Hadoop ডিস্ট্রিবিউটেড ফাইল সিস্টেম (HDFS) হল Apache Hadoop ফ্রেমওয়ার্কের মৌলিক উপাদানগুলির মধ্যে একটি। এটি একটি বিতরণ করা, ত্রুটি-সহনশীল, এবং স্কেলযোগ্য ফাইল সিস্টেম যা কম্পিউট নোডের বড় ক্লাস্টার জুড়ে প্রচুর পরিমাণে ডেটা পরিচালনা করার জন্য অপ্টিমাইজ করা হয়েছে। HDFS ব্যাচ-ডেটা প্রসেসিং কাজগুলিকে মিটমাট করার জন্য ডিজাইন করা হয়েছে এবং বড়, স্ট্রিমিং রিড অপারেশনের জন্য অত্যন্ত অপ্টিমাইজ করা হয়েছে, এটিকে বড় ডেটা আর্কিটেকচারে ব্যবহারের জন্য আদর্শ করে তুলেছে।
HDFS একটি ক্লাস্টারে একাধিক নোড জুড়ে ডেটা সঞ্চয় করে, ত্রুটি সহনশীলতা এবং উচ্চ প্রাপ্যতা নিশ্চিত করার জন্য একটি মূল বৈশিষ্ট্য হিসাবে ডেটা প্রতিলিপি সহ। ডিফল্ট রেপ্লিকেশন ফ্যাক্টর হল 3, তবে এটি নির্দিষ্ট ডেটা স্টোরেজ এবং নির্ভরযোগ্যতার প্রয়োজনীয়তা মেটাতে সামঞ্জস্য করা যেতে পারে। ডেটা ব্লকে বিভক্ত (ডিফল্টরূপে, 128 এমবি আকারে) এবং ক্লাস্টার জুড়ে বিতরণ করা হয়। এটি নিশ্চিত করে যে ডেটা যতটা সম্ভব তার উত্সের কাছাকাছি সংরক্ষিত এবং প্রক্রিয়া করা হয়েছে, নেটওয়ার্ক লেটেন্সি হ্রাস করে এবং কর্মক্ষমতা উন্নত করে।
HDFS এর দুটি প্রাথমিক উপাদান রয়েছে:
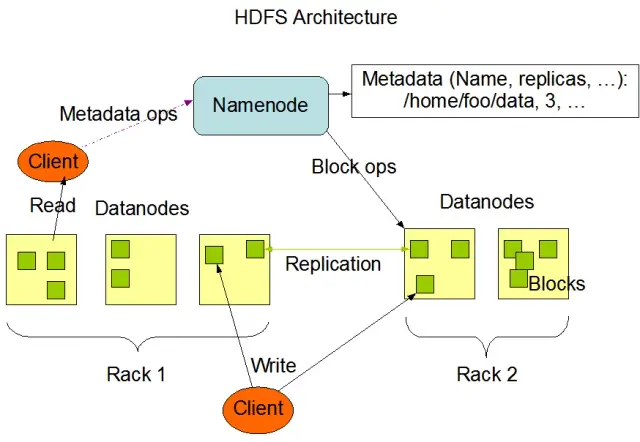
ছবির উৎস: Apache Hadoop
HDFS বিভিন্ন ফাইল অপারেশন প্রদান করে এবং প্রথাগত ফাইল সিস্টেম বৈশিষ্ট্যগুলিকে সমর্থন করে, যেমন ফাইল এবং ডিরেক্টরি তৈরি করা, মুছে ফেলা এবং পুনঃনামকরণ করা। প্রাথমিক অপারেশন অন্তর্ভুক্ত:
ক্লায়েন্টরা Hadoop কমান্ড-লাইন ইন্টারফেস, Java API , বা ওয়েব-ভিত্তিক HDFS ব্রাউজার ব্যবহার করে HDFS-এর সাথে যোগাযোগ করতে পারে।
MapReduce হল একটি প্রোগ্রামিং মডেল এবং Apache Hadoop-এর একটি মূল উপাদান যা বৃহৎ আকারের, বিতরণ করা ডেটা প্রক্রিয়াকরণের জন্য ব্যবহৃত হয়। এটি বিকাশকারীদের এমন প্রোগ্রামগুলি লেখার অনুমতি দেয় যা বিপুল সংখ্যক নোড জুড়ে সমান্তরালভাবে বিপুল পরিমাণ ডেটা প্রক্রিয়া করতে পারে। MapReduce মডেলটি দুটি মূল ক্রিয়াকলাপের উপর ভিত্তি করে তৈরি করা হয়েছে: Map এবং Reduce।
মানচিত্র পর্যায়ে, ইনপুট ডেটা খণ্ডে ভাগ করা হয় এবং মানচিত্র ফাংশন প্রতিটি খণ্ডকে সমান্তরালভাবে প্রক্রিয়া করে। ফাংশন ইনপুট হিসাবে কী-মান জোড়া নেয় এবং আউটপুট হিসাবে মধ্যবর্তী কী-মান জোড়া তৈরি করে। আউটপুট জোড়া কি দ্বারা বাছাই করা হয় তাদের Reduce পর্যায়ে প্রস্তুত করতে।
হ্রাস পর্যায় মানচিত্র ফাংশন দ্বারা উত্পন্ন মধ্যবর্তী কী-মানের জোড়াগুলিকে একত্রিত করে, চূড়ান্ত আউটপুট তৈরি করতে তাদের আরও প্রক্রিয়াকরণ করে। হ্রাস ফাংশন একই কী ভাগ করে নেওয়া মানগুলির প্রতিটি গ্রুপে প্রয়োগ করা হয়। Reduce ফাংশনের আউটপুট HDFS বা অন্য স্টোরেজ সিস্টেমে লেখা হয়, নির্দিষ্ট ব্যবহারের ক্ষেত্রে নির্ভর করে।
MapReduce ব্যবহার করে শব্দ ফ্রিকোয়েন্সি গণনা করার একটি সহজ উদাহরণ বিবেচনা করা যাক। পাঠ্য নথি সমন্বিত একটি বড় ডেটাসেট দেওয়া হলে, মানচিত্র ফাংশন প্রতিটি নথিকে পৃথকভাবে প্রক্রিয়া করে, প্রতিটি শব্দের উপস্থিতি গণনা করে এবং শব্দ-ফ্রিকোয়েন্সি জোড়া নির্গত করে। হ্রাস পর্যায়ে, মানচিত্র ফাংশন দ্বারা উত্পন্ন মধ্যবর্তী কী-মানের জোড়াগুলি শব্দ দ্বারা একত্রিত হয়, এবং মোট শব্দ ফ্রিকোয়েন্সি গণনা করা হয়, চূড়ান্ত আউটপুট তৈরি করে।
MapReduce-এর একটি বিল্ট-ইন ফল্ট টলারেন্স মেকানিজমও রয়েছে যা স্বয়ংক্রিয়ভাবে অন্যান্য উপলব্ধ নোডগুলিতে ব্যর্থ কাজগুলি পুনরায় চালু করতে পারে, পৃথক নোডগুলির ব্যর্থতা সত্ত্বেও প্রক্রিয়াকরণ অব্যাহত থাকে তা নিশ্চিত করে।
AppMaster.io , ব্যাকএন্ড, ওয়েব এবং মোবাইল অ্যাপ্লিকেশনগুলি বিকাশের জন্য একটি শক্তিশালী নো-কোড প্ল্যাটফর্ম, Hadoop-ভিত্তিক বিগ ডেটা সমাধানের পরিপূরক হতে পারে। AppMaster.io-এর সাহায্যে, আপনি ওয়েব এবং মোবাইল অ্যাপ্লিকেশন তৈরি করতে পারেন যা আপনার বড় ডেটা আর্কিটেকচারের দ্বারা উৎপন্ন ও সংরক্ষিত ডেটা প্রক্রিয়াকরণ এবং বিশ্লেষণ করতে HDFS এবং MapReduce-এর মতো Hadoop উপাদানগুলির সাথে নির্বিঘ্নে একত্রিত হয়।
Hadoop এবং AppMaster.io উভয়ের সুবিধাগুলি ব্যবহার করে, ব্যবসাগুলি শক্তিশালী বড় ডেটা অ্যাপ্লিকেশন তৈরি করতে পারে যা no-code অ্যাপ্লিকেশন ডেভেলপমেন্টের গতি এবং খরচ-কার্যকারিতার সাথে Hadoop-এর মাপযোগ্যতা এবং দক্ষতাকে একত্রিত করে। AppMaster.io-এর স্বজ্ঞাত ড্র্যাগ-এন্ড-ড্রপ ইন্টারফেস এবং ভিজ্যুয়াল বিজনেস প্রসেস ডিজাইনার আপনাকে গভীরভাবে কোডিং দক্ষতার প্রয়োজন ছাড়াই দ্রুত অ্যাপ্লিকেশন তৈরি করতে দেয়, যার ফলে দ্রুত সময়ে-টু-বাজার হয় এবং উন্নয়ন খরচ কম হয়।
অধিকন্তু, যেহেতু AppMaster.io বাস্তব অ্যাপ্লিকেশন তৈরি করে যা প্রাঙ্গনে বা ক্লাউডে স্থাপন করা যেতে পারে, তাই আপনি আপনার ডেটা এবং অ্যাপ্লিকেশন পরিকাঠামোর উপর সম্পূর্ণ নিয়ন্ত্রণ বজায় রাখতে পারেন। এই নমনীয়তা আপনাকে আপনার প্রতিষ্ঠানের আকার বা শিল্প খাত নির্বিশেষে আপনার নির্দিষ্ট প্রয়োজনের জন্য তৈরি একটি ব্যাপক বড় ডেটা সমাধান তৈরি করতে দেয়।
বড় ডেটা আর্কিটেকচারের জন্য Hadoop-এর সাথে AppMaster.io ব্যবহার করে দ্রুত অ্যাপ্লিকেশন ডেভেলপমেন্ট, কম ডেভেলপমেন্ট খরচ এবং বড় আকারের ডেটাসেট প্রক্রিয়াকরণ ও বিশ্লেষণে দক্ষতা বৃদ্ধি সহ অসংখ্য সুবিধা প্রদান করতে পারে। উভয় প্ল্যাটফর্মের শক্তির ব্যবহার করে, ব্যবসাগুলি স্কেলযোগ্য বড় ডেটা অ্যাপ্লিকেশন তৈরি করতে পারে যা বৃদ্ধিকে চালিত করে এবং মূল্যবান অন্তর্দৃষ্টি প্রদান করে।
আপনার বড় ডেটা পরিকাঠামোর সর্বোত্তম কর্মক্ষমতা এবং ব্যবস্থাপনা নিশ্চিত করার জন্য Hadoop ক্লাস্টারগুলির জন্য সঠিক স্থাপনার কৌশল নির্বাচন করা অত্যন্ত গুরুত্বপূর্ণ। Hadoop ক্লাস্টার সেট আপ করার সময় বেছে নেওয়ার জন্য তিনটি প্রাথমিক স্থাপনার মডেল রয়েছে:
একটি অন-প্রিমিসেস স্থাপনায়, Hadoop ক্লাস্টারগুলি আপনার প্রতিষ্ঠানের নিজস্ব ডেটা সেন্টারগুলি ব্যবহার করে ইন-হাউস সেট আপ এবং পরিচালনা করা হয়। এই পদ্ধতিটি বিভিন্ন সুবিধা প্রদান করে, যেমন শারীরিক নিরাপত্তার উপর নিয়ন্ত্রণ, ডেটা সার্বভৌমত্ব এবং সম্মতির জন্য একটি পরিচিত পরিবেশ। তবুও, অন-প্রাঙ্গনে স্থাপনা সম্পদ-নিবিড় হতে পারে, যার জন্য হার্ডওয়্যার, রক্ষণাবেক্ষণ এবং আইটি কর্মীদের আরও অগ্রিম বিনিয়োগ প্রয়োজন। এছাড়াও, শুধুমাত্র ভৌত অবকাঠামোর উপর নির্ভর করার সময় সম্পদ স্কেলিং করা চ্যালেঞ্জিং হতে পারে।
Hadoop ক্লাস্টারগুলির ক্লাউড-ভিত্তিক স্থাপনা ক্লাউড প্ল্যাটফর্মগুলির স্কেলেবিলিটি, নমনীয়তা এবং খরচ-দক্ষতা লাভ করে, যেমন Amazon Web Services (AWS) , Google Cloud Platform (GCP), এবং Microsoft Azure । ক্লাউড পরিষেবা প্রদানকারী অবকাঠামো পরিচালনার দায়িত্ব নেয়, আপনার দলকে ডেটা প্রক্রিয়াকরণ এবং বিশ্লেষণে ফোকাস করার অনুমতি দেয়। ক্লাউড-ভিত্তিক স্থাপনাগুলি পে-অ্যাজ-ইউ-গো মূল্যের মডেলগুলি অফার করে, যার অর্থ আপনি শুধুমাত্র আপনার ব্যবহার করা সংস্থানগুলির জন্য অর্থ প্রদান করেন। তবুও, কিছু সংস্থার ডেটা সুরক্ষা এবং সম্মতি নিয়ে উদ্বেগ থাকতে পারে যখন তাদের ডেটা তৃতীয় পক্ষের ক্লাউড সরবরাহকারীদের কাছে অর্পণ করা হয়।
একটি হাইব্রিড স্থাপনার কৌশল অন-প্রাঙ্গনে এবং ক্লাউড-ভিত্তিক স্থাপনার উভয়ের শক্তিকে একত্রিত করে। এই মডেলে, সংবেদনশীল ডেটা এবং নিয়ন্ত্রিত ওয়ার্কলোডগুলি প্রাঙ্গনে থাকতে পারে, যখন অন্যান্য কাজের চাপ এবং ডেটা খরচ-দক্ষতা এবং মাপযোগ্যতার জন্য ক্লাউডে অফলোড করা যেতে পারে। একটি হাইব্রিড স্থাপনা সংস্থাগুলিকে ক্লাউড কম্পিউটিং দ্বারা প্রদত্ত সুবিধাগুলির সুবিধা গ্রহণের সময় নিয়ন্ত্রণ, সুরক্ষা এবং নমনীয়তার জন্য তাদের চাহিদার ভারসাম্য বজায় রাখতে সক্ষম করে৷
প্রতিটি স্থাপনার মডেলের সুবিধা এবং অসুবিধা রয়েছে, তাই আপনার Hadoop ক্লাস্টারের জন্য সবচেয়ে উপযুক্ত কৌশল বেছে নেওয়ার সময় ব্যয়, পরিমাপযোগ্যতা, রক্ষণাবেক্ষণ, নিরাপত্তা এবং সম্মতির প্রয়োজনীয়তাগুলি বিবেচনা করা অপরিহার্য।
Apache Hadoop বিভিন্ন বড় ডেটা চ্যালেঞ্জ মোকাবেলা করার জন্য শিল্প জুড়ে ব্যাপকভাবে ব্যবহৃত হয়, মূল্যবান অন্তর্দৃষ্টি বের করার জন্য বিশাল পরিমাণের কাঠামোগত এবং অসংগঠিত ডেটা বিশ্লেষণ করে। এখানে Hadoop-এর কিছু সাধারণ বাস্তব-জীবনের অ্যাপ্লিকেশন রয়েছে:
Apache Hadoop বিভিন্ন শিল্পে বড় ডেটা চ্যালেঞ্জ মোকাবেলার জন্য একটি শক্তিশালী এবং বহুমুখী সমাধান। বৃহৎ আকারের ডেটা স্টোরেজ এবং প্রক্রিয়াকরণের জন্য এই প্রযুক্তি গ্রহণ করতে চাওয়া সংস্থাগুলির জন্য এর উপাদান, সুবিধা, স্থাপনার কৌশল এবং ব্যবহারের ক্ষেত্রে বোঝা অপরিহার্য।
no-codeAppMaster প্ল্যাটফর্মের মতো অন্যান্য আধুনিক উন্নয়ন পদ্ধতির সাথে হাডুপকে একত্রিত করা, ব্যবসাগুলিকে একটি ব্যাপক, মাপযোগ্য, এবং দক্ষ ডেটা প্রক্রিয়াকরণ ইকোসিস্টেম অফার করে। সঠিক কৌশল এবং স্থাপনার মডেলের সাথে, আপনার সংস্থা Hadoop-এর শক্তিকে কাজে লাগাতে পারে এবং আরও ভাল সিদ্ধান্ত গ্রহণ, অপ্টিমাইজেশান এবং উদ্ভাবনের জন্য বড় ডেটার সম্ভাবনাকে পুঁজি করতে পারে।
থিওডোর লেভিটের উক্তিটি অনেক সত্য ধারণ করে: "উদ্ভাবন হল স্ফুলিঙ্গের মতো যা জীবনে পরিবর্তন, উন্নতি এবং অগ্রগতি নিয়ে আসে।" যখন আমরা Hadoop এবং AppMaster একত্রিত করি, তখন এটি সেই স্পার্ক ক্যাপচার করার মতো। এই গতিশীল জুটি সংস্থাগুলিকে বড় সিদ্ধান্ত নিতে, আরও স্মার্টভাবে কাজ করতে এবং নতুন ধারনা নিয়ে আসতে চাপ দেয়। আপনি আপনার পথের পরিকল্পনা করার সময়, মনে রাখবেন যে বড় ডেটা বৃদ্ধির জন্য সম্ভাবনার ভান্ডারের মতো। এবং সঠিক সরঞ্জামগুলির সাহায্যে, আপনি উন্নতির এবং আরও ভাল সময়ের দরজা খুলছেন।
Apache Hadoop হল একটি ওপেন সোর্স ফ্রেমওয়ার্ক যা দক্ষতার সাথে সঞ্চয়, প্রক্রিয়াকরণ এবং বিপুল পরিমাণ ডেটা বিশ্লেষণ করার জন্য ডিজাইন করা হয়েছে। এটিতে একাধিক উপাদান রয়েছে যা বিগ ডেটার বিভিন্ন দিক পরিচালনা করতে একসাথে কাজ করে, যেমন স্টোরেজের জন্য Hadoop ডিস্ট্রিবিউটেড ফাইল সিস্টেম (HDFS) এবং প্রক্রিয়াকরণের জন্য MapReduce। বিগ ডেটা আর্কিটেকচারে, Hadoop একটি ভিত্তিপ্রস্তর হিসাবে কাজ করে, বিশাল ডেটাসেটগুলি থেকে অন্তর্দৃষ্টিগুলি পরিচালনা এবং আহরণ করার জন্য পরিকাঠামো প্রদান করে।
Apache Hadoop তার বিতরণ করা এবং সমান্তরাল প্রক্রিয়াকরণ ক্ষমতার মাধ্যমে বড় ডেটা চ্যালেঞ্জ মোকাবেলা করে। এটি ডেটাকে ছোট ছোট অংশে বিভক্ত করে, যা আন্তঃসংযুক্ত মেশিনগুলির একটি ক্লাস্টার জুড়ে সমান্তরালভাবে প্রক্রিয়া করা হয়। এই পদ্ধতিটি স্কেলেবিলিটি, ত্রুটি সহনশীলতা এবং কর্মক্ষমতা বাড়ায়, এটি বড় আকারের ডেটা প্রক্রিয়াকরণ এবং বিশ্লেষণের কাজগুলি পরিচালনা করা সম্ভবপর করে তোলে।
Apache Hadoop মেশিনের একটি ক্লাস্টার জুড়ে ডেটা স্টোরেজ পরিচালনা করতে Hadoop ডিস্ট্রিবিউটেড ফাইল সিস্টেম (HDFS) নিয়োগ করে। এইচডিএফএস ডেটাকে ব্লকে বিভক্ত করে, ত্রুটি সহনশীলতার জন্য তাদের প্রতিলিপি করে এবং ক্লাস্টার জুড়ে বিতরণ করে। এই বিতরণ স্টোরেজ আর্কিটেকচার উচ্চ প্রাপ্যতা এবং নির্ভরযোগ্যতা নিশ্চিত করে।
MapReduce Hadoop-এর মধ্যে একটি প্রোগ্রামিং মডেল এবং প্রসেসিং ইঞ্জিন যা বিতরণ করা ডেটা প্রসেসিং সক্ষম করে। এটি কার্যগুলিকে দুটি পর্যায়ে বিভক্ত করে: ডেটা প্রক্রিয়াকরণের জন্য "মানচিত্র" পর্যায় এবং একত্রিতকরণ এবং সংক্ষিপ্তকরণের জন্য "কমাবার" পর্যায়। MapReduce ডেভেলপারদের কোড লেখার অনুমতি দেয় যা অনেক সংখ্যক নোড জুড়ে স্কেল করে, এটিকে বড় ডেটার সমান্তরাল প্রক্রিয়াকরণের জন্য উপযুক্ত করে তোলে।
Apache Hadoop একত্রিত করার সাথে একটি Hadoop ক্লাস্টার সেট আপ করা জড়িত, যা ডেটা স্টোরেজ এবং প্রক্রিয়াকরণের জন্য দায়ী একাধিক নোড নিয়ে গঠিত। সংস্থাগুলি ডেটা আদান-প্রদানের সুবিধার্থে সংযোগকারী এবং API ব্যবহার করে বিদ্যমান সিস্টেম এবং সরঞ্জামগুলির পাশাপাশি Hadoop স্থাপন করতে পারে। উপরন্তু, Hadoop বিভিন্ন ডেটা ইনজেশন পদ্ধতি সমর্থন করে, এটি বিভিন্ন উত্স থেকে ডেটার সাথে সামঞ্জস্যপূর্ণ করে তোলে।
Apache Hadoop বড় ডেটা প্রযুক্তিতে অগ্রগতির পাশাপাশি বিকশিত হতে থাকে। যদিও নতুন টুলস এবং ফ্রেমওয়ার্ক আবির্ভূত হয়েছে, Hadoop অনেক বড় ডেটা ইকোসিস্টেমের একটি মৌলিক উপাদান হিসেবে রয়ে গেছে। এর দৃঢ়তা, নমনীয়তা, এবং বিভিন্ন ধরণের ডেটা পরিচালনা করার ক্ষমতা এটিকে ভবিষ্যতের ব্যবহারের ক্ষেত্রে এবং বড় ডেটার বিশ্বে চ্যালেঞ্জগুলির জন্য ভাল অবস্থান দেয়।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


