Entendiendo el Sistema de Archivos Distribuido Hadoop (HDFS)
El Sistema de Archivos Distribuidos Hadoop (HDFS) es uno de los componentes fundamentales del framework Apache Hadoop. Es un sistema de archivos distribuido, tolerante a fallos y escalable, optimizado para gestionar grandes volúmenes de datos en grandes clusters de nodos de computación. HDFS está diseñado para acomodar tareas de procesamiento de datos por lotes y está altamente optimizado para grandes operaciones de lectura en flujo, lo que lo hace ideal para su uso en la arquitectura de big data.
HDFS almacena datos en varios nodos de un clúster, con la replicación de datos como característica clave para garantizar la tolerancia a fallos y la alta disponibilidad. El factor de replicación por defecto es 3, pero puede ajustarse para satisfacer las necesidades de los requisitos específicos de almacenamiento y fiabilidad de los datos. Los datos se dividen en bloques (por defecto, de 128 MB de tamaño) y se distribuyen por todo el clúster. Esto garantiza que los datos se almacenen y procesen lo más cerca posible de su origen, reduciendo la latencia de la red y mejorando el rendimiento.
Componentes clave de HDFS
Hay dos componentes principales de HDFS:
- NameNode: El NameNode es el servidor maestro de HDFS, responsable de gestionar el espacio de nombres, los metadatos y la salud del sistema de archivos. Mantiene el árbol del sistema de archivos y los metadatos de todos los archivos y directorios, y garantiza la correcta replicación de los datos y el reequilibrio de los bloques de datos cuando es necesario.
- Nodo de datos: Los DataNodes son nodos de trabajo dentro de la arquitectura HDFS, responsables de almacenar y gestionar los bloques de datos en sus dispositivos de almacenamiento local. Los DataNodes se comunican con el NameNode para gestionar las tareas de almacenamiento y replicación. Los datos almacenados en estos DataNodes suelen estar repartidos en varios discos, lo que permite un alto paralelismo en las operaciones de datos.
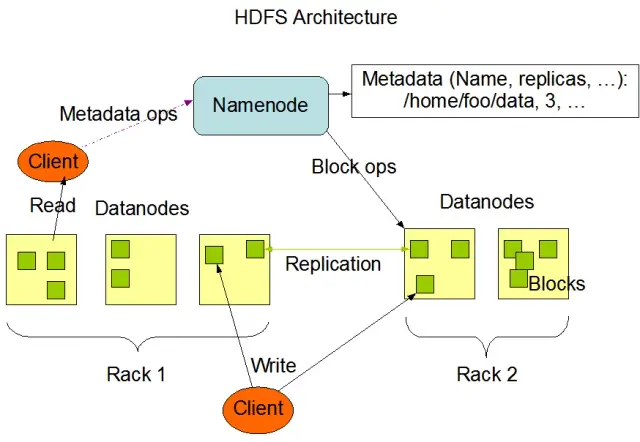
Fuente de la imagen: Apache Hadoop
Operaciones HDFS
HDFS proporciona varias operaciones de archivo y soporta las características tradicionales del sistema de archivos, como crear, eliminar y renombrar archivos y directorios. Las operaciones principales son
- Escribir, leer y borrar archivos
- Crear y eliminar directorios
- Recuperar metadatos (como tamaño de archivo, ubicación de bloques y tiempos de acceso)
- Establecer y recuperar permisos de usuario y cuotas
Los clientes pueden interactuar con HDFS mediante la interfaz de línea de comandos de Hadoop, las API de Java o los navegadores HDFS basados en web.
MapReduce: El motor de procesamiento de Hadoop
MapReduce es un modelo de programación y un componente central de Apache Hadoop utilizado para el procesamiento de datos distribuidos a gran escala. Permite a los desarrolladores escribir programas que pueden procesar grandes cantidades de datos en paralelo a través de un gran número de nodos. El modelo MapReduce se basa en dos operaciones clave: Map y Reduce.
Función Map
En la etapa Map, los datos de entrada se dividen en trozos, y la función Map procesa cada trozo en paralelo. La función toma pares clave-valor como entrada y genera pares clave-valor intermedios como salida. Los pares de salida se ordenan por clave para prepararlos para la etapa de reducción.
Función de reducción
La etapa Reduce agrega los pares clave-valor intermedios generados por la función Map y los procesa para producir el resultado final. La función Reduce se aplica a cada grupo de valores que comparten la misma clave. El resultado de la función Reduce se vuelve a escribir en HDFS o en otro sistema de almacenamiento, dependiendo del caso de uso específico.
Ejemplo de MapReduce
Veamos un ejemplo sencillo de cálculo de frecuencia de palabras utilizando MapReduce. Dado un gran conjunto de datos que contiene documentos de texto, la función Map procesa cada documento individualmente, contando las ocurrencias de cada palabra y emitiendo los pares palabra-frecuencia. En la etapa Reduce, los pares clave-valor intermedios generados por la función Map se agregan por palabra, y se calculan las frecuencias totales de palabras, produciendo el resultado final.
MapReduce también cuenta con un mecanismo integrado de tolerancia a fallos que puede reiniciar automáticamente las tareas fallidas en otros nodos disponibles, garantizando que el procesamiento continúe a pesar del fallo de nodos individuales.
Cómo complementa AppMaster.io las soluciones de Big Data de Hadoop
AppMaster. io, una potente plataforma sin código para el desarrollo de aplicaciones backend, web y móviles, puede complementar las soluciones de big data basadas en Hadoop. Con AppMaster.io, puede crear aplicaciones web y móviles que se integren a la perfección con componentes Hadoop, como HDFS y MapReduce, para procesar y analizar los datos generados y almacenados por su arquitectura de big data.
Al aprovechar las ventajas tanto de Hadoop como de AppMaster.io, las empresas pueden crear potentes aplicaciones de big data que combinan la escalabilidad y eficiencia de Hadoop con la velocidad y rentabilidad del desarrollo de aplicaciones de no-code. AppMaster La intuitiva interfaz de arrastrar y soltar y el diseñador visual de procesos de negocio de .io permiten crear aplicaciones rápidamente sin necesidad de conocimientos profundos de codificación, lo que se traduce en una comercialización más rápida y en una reducción de los costes de desarrollo.

Además, dado que AppMaster.io genera aplicaciones reales que pueden desplegarse en las instalaciones o en la nube, puede mantener un control total sobre sus datos y la infraestructura de la aplicación. Esta flexibilidad le permite crear una solución integral de big data adaptada a sus necesidades específicas, independientemente del tamaño de su organización o del sector industrial al que pertenezca.
El uso de AppMaster.io junto con Hadoop para la arquitectura de big data puede proporcionar numerosas ventajas, como un desarrollo más rápido de las aplicaciones, una reducción de los costes de desarrollo y una mayor eficiencia en el procesamiento y análisis de conjuntos de datos a gran escala. Al aprovechar los puntos fuertes de ambas plataformas, las empresas pueden crear aplicaciones de big data escalables que impulsen el crecimiento y ofrezcan información valiosa.
Estrategias de despliegue para clústeres Hadoop
Seleccionar la estrategia de despliegue adecuada para los clústeres Hadoop es crucial para garantizar un rendimiento y una gestión óptimos de su infraestructura de big data. Existen tres modelos de despliegue principales entre los que elegir a la hora de configurar clústeres Hadoop:
Despliegue local
En una implementación local, los clústeres Hadoop se configuran y gestionan internamente, utilizando los propios centros de datos de su organización. Este enfoque ofrece varias ventajas, como el control de la seguridad física, la soberanía de los datos y un entorno conocido para el cumplimiento. Sin embargo, las implantaciones locales pueden requerir muchos recursos, más inversión inicial en hardware, mantenimiento y personal de TI. Además, el escalado de recursos puede resultar complicado si se depende únicamente de la infraestructura física.
Despliegue en la nube
La implantación de clusters Hadoop basada en la nube aprovecha la escalabilidad, flexibilidad y rentabilidad de las plataformas en la nube, como Amazon Web Services (AWS), Google Cloud Platform (GCP) y Microsoft Azure. El proveedor de servicios en la nube asume la responsabilidad de la gestión de la infraestructura, lo que permite a su equipo centrarse en el procesamiento y el análisis de los datos. Los despliegues basados en la nube ofrecen modelos de precios de pago por uso, lo que significa que usted sólo paga por los recursos que consume. Aun así, algunas organizaciones pueden tener dudas sobre la seguridad de los datos y el cumplimiento de la normativa cuando confían sus datos a proveedores externos de servicios en la nube.
Despliegue híbrido
Una estrategia de implantación híbrida combina los puntos fuertes de las implantaciones locales y en la nube. En este modelo, los datos confidenciales y las cargas de trabajo reguladas pueden permanecer en las instalaciones, mientras que otras cargas de trabajo y datos pueden descargarse en la nube para obtener rentabilidad y escalabilidad. Un despliegue híbrido permite a las organizaciones equilibrar sus necesidades de control, seguridad y flexibilidad al tiempo que aprovechan las ventajas que ofrece la computación en nube.
Cada modelo de despliegue tiene sus pros y sus contras, por lo que es esencial tener en cuenta el coste, la escalabilidad, el mantenimiento, la seguridad y los requisitos de cumplimiento a la hora de elegir la estrategia más adecuada para su clúster Hadoop.
Casos de uso: Hadoop en aplicaciones reales
Apache Hadoop se utiliza ampliamente en todos los sectores para hacer frente a diversos retos de big data, analizando grandes volúmenes de datos estructurados y no estructurados para extraer información valiosa. Estas son algunas de las aplicaciones más comunes de Hadoop en la vida real:
- Análisis de registros y clics: Hadoop puede procesar grandes volúmenes de registros de servidores y aplicaciones y datos de clics generados por los usuarios de sitios web. El análisis de estos datos puede ayudar a las empresas a comprender el comportamiento de los usuarios, optimizar su experiencia y solucionar problemas de rendimiento.
- Motores de recomendación: Las plataformas de comercio electrónico y los proveedores de contenidos utilizan Hadoop para analizar los patrones de navegación y compra de los clientes y generar recomendaciones personalizadas de productos, servicios o contenidos. La capacidad de Hadoop para procesar conjuntos de datos masivos y realizar cálculos complejos lo convierte en una solución ideal para los motores de recomendación.
- Detección de fraudes: Los servicios financieros y las compañías de seguros aprovechan Hadoop para analizar datos de transacciones y detectar patrones anómalos indicativos de fraude. Las capacidades de procesamiento paralelo y escalable de Hadoop permiten a las organizaciones identificar y mitigar rápidamente los posibles riesgos de fraude.
- Análisis de redes sociales: Hadoop puede procesar grandes volúmenes de datos de redes sociales, incluidos perfiles de usuarios, interacciones y contenidos compartidos, para desvelar tendencias y conocimientos sobre comportamiento humano, análisis de opiniones y estrategias de marketing.
- Aprendizaje automático y análisis predictivo: Hadoop acelera el aprendizaje automático y el análisis predictivo paralelizando algoritmos de alto coste computacional en grandes conjuntos de datos. Las empresas pueden utilizar las capacidades de Hadoop para desarrollar modelos predictivos de previsión de la demanda, rotación de clientes y otras métricas críticas.
- Aumento del almacén de datos: Hadoop puede integrarse con los sistemas tradicionales de almacén de datos, descargando ciertas cargas de trabajo, como los procesos de extracción, transformación y carga (ETL), y mejorando el rendimiento. Este enfoque puede ayudar a las empresas a reducir costes, aliviar la carga de la infraestructura existente y mejorar sus capacidades analíticas.
Conclusión
Apache Hadoop es una solución potente y versátil para hacer frente a los retos que plantean los macrodatos en diversos sectores. Comprender sus componentes, ventajas, estrategias de despliegue y casos de uso es esencial para las organizaciones que deseen adoptar esta tecnología para el almacenamiento y procesamiento de datos a gran escala.
La combinación de Hadoop con otros enfoques de desarrollo modernos, como la plataforma no-codeAppMaster, ofrece a las empresas un ecosistema de procesamiento de datos completo, escalable y eficiente. Con la estrategia y el modelo de implantación adecuados, su organización puede aprovechar la potencia de Hadoop y capitalizar el potencial de big data para impulsar una mejor toma de decisiones, optimización e innovación.
El dicho de Theodore Levitt tiene mucho de cierto: "La innovación es como la chispa que da vida al cambio, la mejora y el progreso". Cuando combinamos Hadoop y AppMaster, es como capturar esa chispa. Este dúo dinámico empuja a las organizaciones a tomar grandes decisiones, a trabajar de forma más inteligente y a tener nuevas ideas. Cuando planifique su camino, recuerde que los macrodatos son como un cofre del tesoro de posibilidades de crecimiento. Y con las herramientas adecuadas, estarás abriendo la puerta al progreso y a tiempos mejores.






