

设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
探索 Apache Hadoop 的基本原理及其在大数据架构中的作用,包括其组件、优势和部署策略。了解它如何融入现代数据生态系统并促进大规模处理。

Hadoop 分布式文件系统(HDFS)是 Apache Hadoop 框架的基本组件之一。它是一个分布式、容错和可扩展的文件系统,针对跨大型计算节点集群管理大量数据进行了优化。HDFS 设计用于批量数据处理任务,并针对大型流式读取操作进行了高度优化,因此非常适合在大数据架构中使用。
HDFS 跨集群中的多个节点存储数据,数据复制是确保容错和高可用性的关键功能。默认复制因子为 3,但可根据具体的数据存储和可靠性要求进行调整。数据被划分成块(默认大小为 128 MB)并分布在集群中。这可确保数据的存储和处理尽可能靠近数据源,从而减少网络延迟并提高性能。
HDFS 有两个主要组件:
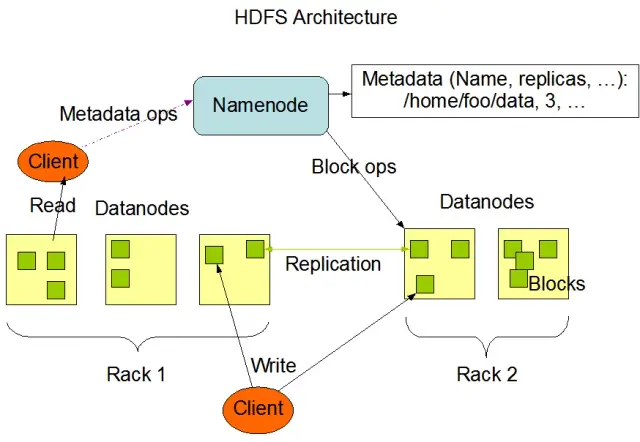
图片来源:Apache Hadoop阿帕奇 Hadoop
HDFS 提供各种文件操作,并支持传统的文件系统功能,如创建、删除和重命名文件和目录。主要操作包括
客户端可使用 Hadoop 命令行界面、Java API 或基于 Web 的 HDFS 浏览器与 HDFS 交互。
MapReduce 是一种编程模型,也是 Apache Hadoop 的核心组件,用于大规模分布式数据处理。它允许开发人员编写可在大量节点上并行处理海量数据的程序。MapReduce 模型基于两个关键操作:Map 和 Reduce。
在 Map 阶段,输入数据被分成若干块,Map 函数并行处理每个块。该函数将键值对作为输入,并生成中间键值对作为输出。输出对按键排序,为 Reduce 阶段做准备。
Reduce 阶段汇总 Map 功能生成的中间键值对,并进一步处理它们以生成最终输出。Reduce 函数适用于共享相同键值的每一组值。Reduce 函数的输出会写回 HDFS 或其他存储系统,具体取决于具体的使用情况。
让我们来看一个使用 MapReduce 计算词频的简单示例。给定一个包含文本文档的大型数据集,Map 函数会单独处理每个文档,计算每个词的出现次数,并输出词频对。在 Reduce 阶段,将 Map 函数生成的中间键值对按词进行汇总,计算总词频,得出最终输出结果。
MapReduce 还具有内置容错机制,可以在其他可用节点上自动重新启动失败的任务,确保在个别节点发生故障时仍能继续处理。
AppMaster.io 是一个功能强大的 无代码 平台,用于开发后端、Web 和移动应用程序,可与基于 Hadoop 的大数据解决方案相辅相成。利用AppMaster.io,您可以构建与 HDFS 和 MapReduce 等 Hadoop 组件无缝集成的 Web 和移动应用程序,以处理和分析由大数据架构生成和存储的数据。
通过利用 Hadoop 和AppMaster.io 的优势,企业可以创建强大的大数据应用程序,将 Hadoop 的可扩展性和效率与no-code 应用程序开发的速度和成本效益结合起来。AppMaster.io 的直观 拖放 界面和可视化业务流程设计器使您无需深入的编码专业知识即可快速构建应用程序,从而 加快产品上市 速度并降低开发成本。
此外,由于AppMaster.io 生成的真实应用程序可以部署在企业内部或云中,因此您可以保持对数据和应用程序基础设施的完全控制。无论您的组织规模或行业领域如何,这种灵活性都能让您根据自己的具体需求创建全面的大数据解决方案。
将AppMaster.io 与 Hadoop 结合使用以实现大数据架构可带来众多优势,包括加快应用程序开发、 降低开发成本 以及提高处理和分析大规模数据集的效率。通过利用这两个平台的优势,企业可以构建可扩展的大数据应用程序,从而推动增长并提供有价值的见解。
为 Hadoop 集群选择正确的部署策略对于确保大数据基础设施的最佳性能和管理至关重要。在建立 Hadoop 集群时,有三种主要部署模式可供选择:
在内部部署中,Hadoop 集群是利用企业自己的数据中心在内部建立和管理的。这种方法具有多种优势,如物理安全控制、数据主权和已知的合规环境。不过,内部部署可能是资源密集型的,需要在硬件、维护和 IT 人员方面进行更多的前期投资。此外,仅依靠物理基础设施来扩展资源也具有挑战性。
基于云的 Hadoop 集群部署利用了 亚马逊网络服务(AWS)、谷歌云平台(GCP)和 微软 Azure 等云平台的可扩展性、灵活性和成本效益。云服务提供商负责基础设施管理,让您的团队专注于数据处理和分析。基于云的部署提供 "即用即付 "的定价模式,这意味着您只需为所消耗的资源付费。不过,有些组织在将数据委托给第三方云服务提供商时,可能会担心数据的安全性和合规性。
混合部署战略结合了内部部署和云部署的优势。在这种模式下,敏感数据和受监管的工作负载可以留在企业内部,而其他工作负载和数据则可以卸载到云中,以实现成本效益和可扩展性。混合部署使企业能够平衡对控制、安全性和灵活性的需求,同时利用云计算提供的优势。
每种部署模式都有利有弊,因此在为 Hadoop 集群选择最合适的策略时,必须考虑成本、可扩展性、维护、安全性和合规性要求。
Apache Hadoop 广泛应用于各行各业,以应对各种大数据挑战,分析大量结构化和非结构化数据,从而提取有价值的见解。以下是 Hadoop 在现实生活中的一些常见应用:
Apache Hadoop 是一种功能强大、用途广泛的解决方案,可用于应对各行各业的大数据挑战。对于希望采用该技术进行大规模数据存储和处理的企业来说,了解其组件、优势、部署策略和用例至关重要。
将 Hadoop 与其他现代开发方法(如no-codeAppMaster 平台)相结合,可为企业提供一个全面、可扩展且高效的数据处理生态系统。有了正确的战略和部署模式,您的企业就能利用 Hadoop 的强大功能,发挥大数据的潜力,推动更好的决策、优化和创新。
西奥多-莱维特(Theodore Levitt)说过的一句话很有道理: "创新就像火花,给生活带来变化、改善和进步"。 当我们将 Hadoop 和AppMaster 结合在一起时,就像捕捉到了火花。这对充满活力的组合推动企业做出重大决策,更聪明地工作,并提出新的想法。在您规划自己的发展道路时,请记住大数据就像一个宝库,蕴藏着发展的无限可能。有了正确的工具,您就打开了通往进步和美好时代的大门。
Apache Hadoop 是一个开源框架,旨在有效地存储、处理和分析海量数据。它由多个组件组成,共同处理大数据的各个方面,如用于存储的 Hadoop 分布式文件系统(HDFS)和用于处理的 MapReduce。在大数据架构中,Hadoop 起着基石的作用,为管理海量数据集和从中获取洞察力提供了基础设施。
Apache Hadoop 通过其分布式并行处理能力应对大数据挑战。它将数据分解成较小的块,然后在相互连接的机器集群中并行处理。这种方法增强了可扩展性、容错性和性能,使处理大规模数据处理和分析任务变得可行。
Apache Hadoop 采用 Hadoop 分布式文件系统(HDFS)来管理整个机器集群的数据存储。HDFS 将数据分割成块,进行容错复制,并将其分布在整个集群中。这种分布式存储架构可确保高可用性和可靠性。
MapReduce 是 Hadoop 中的一种编程模型和处理引擎,可实现分布式数据处理。它将任务分为两个阶段:"map "阶段用于数据处理,"reduce "阶段用于聚合和汇总。MapReduce 允许开发人员编写可在大量节点上扩展的代码,因此适用于大数据的并行处理。
整合 Apache Hadoop 需要建立一个 Hadoop 集群,该集群由多个负责数据存储和处理的节点组成。企业可将 Hadoop 与现有系统和工具一起部署,使用连接器和 API 来促进数据交换。此外,Hadoop 还支持各种数据摄取方法,使其与各种来源的数据兼容。
随着大数据技术的进步,Apache Hadoop 也在不断发展。虽然出现了更新的工具和框架,但 Hadoop 仍然是许多大数据生态系统的基本组成部分。它的稳健性、灵活性和处理各种数据类型的能力使其能够很好地应对大数据世界中的未来用例和挑战。




