
Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Lernen Sie die Grundlagen von Apache Hadoop und seine Rolle in der Big-Data-Architektur kennen, einschließlich seiner Komponenten, Vorteile und Einsatzstrategien. Erfahren Sie, wie es in moderne Datenökosysteme passt und die Verarbeitung großer Datenmengen erleichtert.

Das Hadoop Distributed File System (HDFS) ist eine der grundlegenden Komponenten des Apache Hadoop Frameworks. Es ist ein verteiltes, fehlertolerantes und skalierbares Dateisystem, das für die Verwaltung großer Datenmengen in großen Clustern von Rechenknoten optimiert ist. HDFS wurde für die Verarbeitung von Stapeldaten entwickelt und ist für große Lesevorgänge im Streaming-Verfahren optimiert, was es ideal für den Einsatz in Big-Data-Architekturen macht.
HDFS speichert Daten auf mehreren Knoten in einem Cluster, wobei die Datenreplikation eine wichtige Funktion ist, um Fehlertoleranz und hohe Verfügbarkeit zu gewährleisten. Der Standardreplikationsfaktor beträgt 3, kann aber an die Anforderungen der jeweiligen Datenspeicherung und Zuverlässigkeit angepasst werden. Die Daten werden in Blöcke aufgeteilt (standardmäßig 128 MB groß) und über den Cluster verteilt. Dadurch wird sichergestellt, dass die Daten so nah wie möglich an ihrer Quelle gespeichert und verarbeitet werden, was die Netzwerklatenz verringert und die Leistung verbessert.
Es gibt zwei Hauptkomponenten von HDFS:
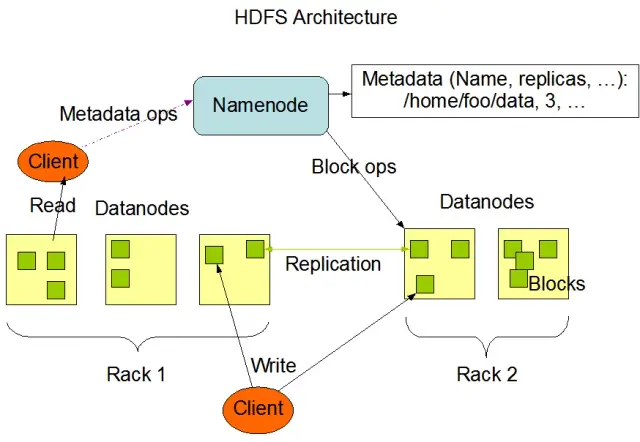
Bildquelle: Apache Hadoop
HDFS bietet verschiedene Dateioperationen und unterstützt herkömmliche Dateisystemfunktionen wie das Erstellen, Löschen und Umbenennen von Dateien und Verzeichnissen. Zu den wichtigsten Operationen gehören:
Clients können mit HDFS über die Hadoop-Befehlszeilenschnittstelle, Java-APIs oder webbasierte HDFS-Browser interagieren.
MapReduce ist ein Programmiermodell und eine Kernkomponente von Apache Hadoop für die groß angelegte, verteilte Datenverarbeitung. Es ermöglicht Entwicklern, Programme zu schreiben, die große Datenmengen parallel über eine große Anzahl von Knoten verarbeiten können. Das MapReduce-Modell basiert auf zwei Schlüsseloperationen: Map und Reduce.
In der Map-Phase werden die Eingabedaten in Chunks unterteilt, und die Map-Funktion verarbeitet jeden Chunk parallel. Die Funktion nimmt Schlüssel-Wert-Paare als Eingabe und erzeugt Zwischen-Schlüssel-Wert-Paare als Ausgabe. Die Ausgabepaare werden nach Schlüsseln sortiert, um sie für die Reduce-Phase vorzubereiten.
In der Reduce-Phase werden die von der Map-Funktion erzeugten Schlüssel-Wert-Zwischenpaare aggregiert und weiter verarbeitet, um die endgültige Ausgabe zu erzeugen. Die Reduce-Funktion wird auf jede Gruppe von Werten angewendet, die denselben Schlüssel haben. Die Ausgabe der Reduce-Funktion wird je nach Anwendungsfall in das HDFS oder ein anderes Speichersystem zurückgeschrieben.
Betrachten wir ein einfaches Beispiel für die Berechnung der Worthäufigkeit mit MapReduce. Bei einem großen Datensatz mit Textdokumenten verarbeitet die Map-Funktion jedes Dokument einzeln, zählt die Vorkommen jedes Worts und gibt die Wort-Häufigkeits-Paare aus. In der Reduce-Phase werden die von der Map-Funktion erzeugten Key-Value-Zwischenpaare nach Wörtern aggregiert und die Gesamtworthäufigkeiten berechnet, wodurch die endgültige Ausgabe entsteht.
MapReduce verfügt außerdem über einen eingebauten Fehlertoleranzmechanismus, der fehlgeschlagene Aufgaben automatisch auf anderen verfügbaren Knoten neu starten kann, so dass die Verarbeitung trotz des Ausfalls einzelner Knoten fortgesetzt werden kann.
AppMaster.io, eine leistungsstarke No-Code-Plattform für die Entwicklung von Backend-, Web- und mobilen Anwendungen, kann Hadoop-basierte Big-Data-Lösungen ergänzen. Mit AppMaster.io können Sie Web- und mobile Anwendungen erstellen, die sich nahtlos in Hadoop-Komponenten wie HDFS und MapReduce integrieren lassen, um die von Ihrer Big-Data-Architektur erzeugten und gespeicherten Daten zu verarbeiten und zu analysieren.
Durch die Nutzung der Vorteile von Hadoop und AppMaster.io können Unternehmen leistungsstarke Big-Data-Anwendungen erstellen, die die Skalierbarkeit und Effizienz von Hadoop mit der Geschwindigkeit und Kosteneffizienz der Anwendungsentwicklung von no-code kombinieren. AppMaster Die intuitive Drag-and-Drop-Benutzeroberfläche und der visuelle Geschäftsprozessdesigner von .io ermöglichen die schnelle Erstellung von Anwendungen ohne tiefgreifende Programmierkenntnisse, was zu einer schnelleren Markteinführung und geringeren Entwicklungskosten führt.
Da AppMaster.io echte Anwendungen generiert, die vor Ort oder in der Cloud bereitgestellt werden können, behalten Sie außerdem die volle Kontrolle über Ihre Daten und Anwendungsinfrastruktur. Diese Flexibilität ermöglicht es Ihnen, eine umfassende Big-Data-Lösung zu erstellen, die auf Ihre spezifischen Bedürfnisse zugeschnitten ist, unabhängig von der Größe Ihres Unternehmens oder Ihrer Branche.
Die Verwendung von AppMaster.io in Verbindung mit Hadoop für Big-Data-Architekturen kann zahlreiche Vorteile bieten, darunter eine schnellere Anwendungsentwicklung, geringere Entwicklungskosten und eine höhere Effizienz bei der Verarbeitung und Analyse großer Datensätze. Durch die Nutzung der Stärken beider Plattformen können Unternehmen skalierbare Big-Data-Anwendungen erstellen, die das Wachstum fördern und wertvolle Erkenntnisse liefern.
Die Wahl der richtigen Bereitstellungsstrategie für Hadoop-Cluster ist entscheidend für eine optimale Leistung und Verwaltung Ihrer Big-Data-Infrastruktur. Bei der Einrichtung von Hadoop-Clustern können Sie zwischen drei primären Bereitstellungsmodellen wählen:
Bei einer Vor-Ort-Bereitstellung werden Hadoop-Cluster intern eingerichtet und verwaltet, wobei die eigenen Rechenzentren Ihres Unternehmens genutzt werden. Dieser Ansatz bietet mehrere Vorteile, z. B. die Kontrolle über die physische Sicherheit, die Datenhoheit und eine bekannte Umgebung für die Einhaltung von Vorschriften. Dennoch können Implementierungen vor Ort ressourcenintensiv sein und erfordern höhere Vorabinvestitionen in Hardware, Wartung und IT-Personal. Auch die Skalierung von Ressourcen kann eine Herausforderung sein, wenn man sich nur auf die physische Infrastruktur verlässt.
Die Cloud-basierte Bereitstellung von Hadoop-Clustern nutzt die Skalierbarkeit, Flexibilität und Kosteneffizienz von Cloud-Plattformen wie Amazon Web Services (AWS), Google Cloud Platform (GCP) und Microsoft Azure. Der Cloud-Service-Anbieter übernimmt die Verantwortung für das Infrastrukturmanagement, sodass sich Ihr Team auf die Datenverarbeitung und -analyse konzentrieren kann. Cloud-basierte Bereitstellungen bieten Pay-as-you-go-Preismodelle, d. h. Sie zahlen nur für die Ressourcen, die Sie verbrauchen. Einige Unternehmen haben jedoch Bedenken hinsichtlich der Datensicherheit und der Einhaltung von Vorschriften, wenn sie ihre Daten Drittanbietern anvertrauen.
Eine hybride Bereitstellungsstrategie kombiniert die Stärken von lokalen und cloudbasierten Bereitstellungen. Bei diesem Modell können sensible Daten und regulierte Arbeitslasten vor Ort verbleiben, während andere Arbeitslasten und Daten aus Gründen der Kosteneffizienz und Skalierbarkeit in die Cloud verlagert werden können. Eine hybride Bereitstellung ermöglicht es Unternehmen, ihren Bedarf an Kontrolle, Sicherheit und Flexibilität zu decken und gleichzeitig die Vorteile des Cloud Computing zu nutzen.
Jedes Bereitstellungsmodell hat seine Vor- und Nachteile. Daher ist es wichtig, bei der Wahl der am besten geeigneten Strategie für Ihren Hadoop-Cluster Kosten, Skalierbarkeit, Wartung, Sicherheit und Compliance-Anforderungen zu berücksichtigen.
Apache Hadoop wird in vielen Branchen eingesetzt, um verschiedene Big-Data-Herausforderungen zu bewältigen und große Mengen strukturierter und unstrukturierter Daten zu analysieren, um wertvolle Erkenntnisse zu gewinnen. Im Folgenden finden Sie einige gängige Anwendungen von Hadoop aus der Praxis:
Apache Hadoop ist eine leistungsstarke und vielseitige Lösung für die Bewältigung von Big Data-Herausforderungen in verschiedenen Branchen. Für Unternehmen, die diese Technologie für die Speicherung und Verarbeitung großer Datenmengen einsetzen möchten, ist es wichtig, ihre Komponenten, Vorteile, Bereitstellungsstrategien und Anwendungsfälle zu verstehen.
Die Kombination von Hadoop mit anderen modernen Entwicklungsansätzen, wie der Plattform no-codeAppMaster, bietet Unternehmen ein umfassendes, skalierbares und effizientes Ökosystem für die Datenverarbeitung. Mit der richtigen Strategie und dem richtigen Bereitstellungsmodell kann Ihr Unternehmen die Leistung von Hadoop nutzen und das Potenzial von Big Data für eine bessere Entscheidungsfindung, Optimierung und Innovation ausschöpfen.
An dem Spruch von Theodore Levitt ist viel Wahres dran: "Innovation ist wie der Funke, der Veränderung, Verbesserung und Fortschritt ins Leben ruft." Wenn wir Hadoop und AppMaster kombinieren, ist das wie das Einfangen dieses Funkens. Dieses dynamische Duo zwingt Unternehmen dazu, wichtige Entscheidungen zu treffen, intelligenter zu arbeiten und neue Ideen zu entwickeln. Wenn Sie Ihren Weg planen, denken Sie daran, dass Big Data wie eine Schatztruhe voller Wachstumsmöglichkeiten ist. Und mit den richtigen Tools öffnen Sie die Tür zu Fortschritt und besseren Zeiten.
Apache Hadoop ist ein Open-Source-Framework für die effiziente Speicherung, Verarbeitung und Analyse großer Datenmengen. Es umfasst mehrere Komponenten, die zusammenarbeiten, um verschiedene Aspekte von Big Data zu handhaben, wie das Hadoop Distributed File System (HDFS) für die Speicherung und MapReduce für die Verarbeitung. In der Big-Data-Architektur fungiert Hadoop als Eckpfeiler, der die Infrastruktur für die Verwaltung und Ableitung von Erkenntnissen aus riesigen Datensätzen bereitstellt.
Apache Hadoop löst die Herausforderungen von Big Data durch seine verteilten und parallelen Verarbeitungsfunktionen. Es zerlegt Daten in kleinere Teile, die parallel in einem Cluster miteinander verbundener Maschinen verarbeitet werden. Dieser Ansatz verbessert die Skalierbarkeit, Fehlertoleranz und Leistung und macht es möglich, umfangreiche Datenverarbeitungs- und Analyseaufgaben zu bewältigen.
Apache Hadoop verwendet das Hadoop Distributed File System (HDFS), um die Datenspeicherung in einem Cluster von Rechnern zu verwalten. HDFS unterteilt die Daten in Blöcke, repliziert sie für Fehlertoleranz und verteilt sie über den Cluster. Diese verteilte Speicherarchitektur gewährleistet hohe Verfügbarkeit und Zuverlässigkeit.
MapReduce ist ein Programmiermodell und eine Verarbeitungsmaschine innerhalb von Hadoop, die eine verteilte Datenverarbeitung ermöglicht. Es unterteilt Aufgaben in zwei Phasen: die "Map"-Phase für die Datenverarbeitung und die "Reduce"-Phase für die Aggregation und Zusammenfassung. MapReduce ermöglicht es Entwicklern, Code zu schreiben, der über eine große Anzahl von Knoten skaliert werden kann, und eignet sich daher für die parallele Verarbeitung von Big Data.
Die Integration von Apache Hadoop umfasst die Einrichtung eines Hadoop-Clusters, das aus mehreren für die Datenspeicherung und -verarbeitung zuständigen Knoten besteht. Unternehmen können Hadoop neben bestehenden Systemen und Tools einsetzen und dabei Konnektoren und APIs verwenden, um den Datenaustausch zu erleichtern. Darüber hinaus unterstützt Hadoop verschiedene Methoden der Datenaufnahme, so dass es mit Daten aus unterschiedlichen Quellen kompatibel ist.
Apache Hadoop entwickelt sich parallel zu den Fortschritten bei den Big-Data-Technologien ständig weiter. Obwohl neue Tools und Frameworks entstanden sind, bleibt Hadoop eine grundlegende Komponente vieler Big-Data-Ökosysteme. Dank seiner Robustheit, Flexibilität und Fähigkeit, verschiedene Datentypen zu verarbeiten, ist es für künftige Anwendungsfälle und Herausforderungen in der Welt von Big Data bestens gerüstet.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


