
उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
Apache Hadoop के मूल सिद्धांतों और इसके घटकों, लाभों और परिनियोजन रणनीतियों सहित बड़े डेटा आर्किटेक्चर में इसकी भूमिका का अन्वेषण करें। जानें कि यह आधुनिक डेटा पारिस्थितिकी तंत्र में कैसे फिट बैठता है और बड़े पैमाने पर प्रसंस्करण की सुविधा देता है।

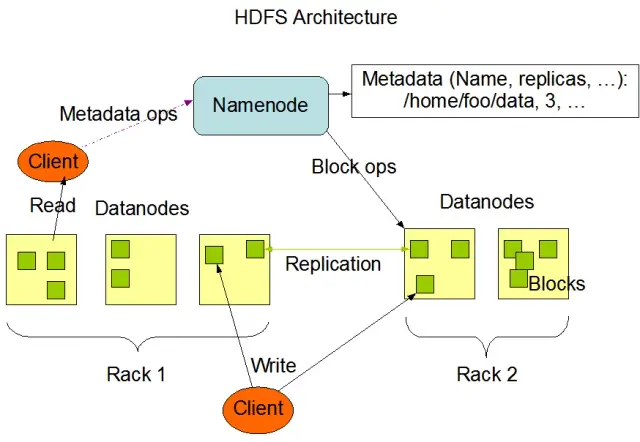
Hadoop डिस्ट्रिब्यूटेड फ़ाइल सिस्टम (HDFS) Apache Hadoop ढांचे के मूलभूत घटकों में से एक है। यह एक वितरित, दोष-सहिष्णु और स्केलेबल फ़ाइल सिस्टम है जो कंप्यूट नोड्स के बड़े समूहों में बड़ी मात्रा में डेटा के प्रबंधन के लिए अनुकूलित है। एचडीएफएस को बैच-डेटा प्रोसेसिंग कार्यों को समायोजित करने के लिए डिज़ाइन किया गया है और इसे बड़े, स्ट्रीमिंग रीड ऑपरेशंस के लिए अत्यधिक अनुकूलित किया गया है, जो इसे बड़े डेटा आर्किटेक्चर में उपयोग के लिए आदर्श बनाता है।
एचडीएफएस एक क्लस्टर में कई नोड्स में डेटा संग्रहीत करता है, जिसमें दोष सहनशीलता और उच्च उपलब्धता सुनिश्चित करने के लिए डेटा प्रतिकृति एक प्रमुख विशेषता है। डिफ़ॉल्ट प्रतिकृति कारक 3 है, लेकिन इसे विशिष्ट डेटा भंडारण और विश्वसनीयता आवश्यकताओं को पूरा करने के लिए समायोजित किया जा सकता है। डेटा को ब्लॉकों में विभाजित किया जाता है (डिफ़ॉल्ट रूप से, आकार में 128 एमबी) और क्लस्टर में वितरित किया जाता है। यह सुनिश्चित करता है कि डेटा को यथासंभव उसके स्रोत के करीब संग्रहीत और संसाधित किया जाए, जिससे नेटवर्क विलंबता कम हो और प्रदर्शन में सुधार हो।
एचडीएफएस के दो प्राथमिक घटक हैं:
छवि स्रोत: अपाचे Hadoop
एचडीएफएस विभिन्न फ़ाइल संचालन प्रदान करता है और पारंपरिक फ़ाइल सिस्टम सुविधाओं का समर्थन करता है, जैसे फ़ाइलें बनाना, हटाना और नाम बदलना। प्राथमिक परिचालनों में शामिल हैं:
ग्राहक Hadoop कमांड-लाइन इंटरफ़ेस, जावा एपीआई या वेब-आधारित HDFS ब्राउज़र का उपयोग करके HDFS के साथ इंटरैक्ट कर सकते हैं।
MapReduce एक प्रोग्रामिंग मॉडल और Apache Hadoop का मुख्य घटक है जिसका उपयोग बड़े पैमाने पर, वितरित डेटा प्रोसेसिंग के लिए किया जाता है। यह डेवलपर्स को प्रोग्राम लिखने की अनुमति देता है जो बड़ी संख्या में नोड्स में समानांतर में बड़ी मात्रा में डेटा संसाधित कर सकता है। MapReduce मॉडल दो प्रमुख ऑपरेशनों पर आधारित है: मैप और रिड्यूस।
मानचित्र चरण में, इनपुट डेटा को टुकड़ों में विभाजित किया जाता है, और मानचित्र फ़ंक्शन प्रत्येक टुकड़े को समानांतर में संसाधित करता है। फ़ंक्शन इनपुट के रूप में कुंजी-मूल्य जोड़े लेता है और आउटपुट के रूप में मध्यवर्ती कुंजी-मूल्य जोड़े उत्पन्न करता है। आउटपुट जोड़े को रिड्यूस चरण के लिए तैयार करने के लिए कुंजी द्वारा क्रमबद्ध किया जाता है।
रिड्यूस चरण मैप फ़ंक्शन द्वारा उत्पन्न मध्यवर्ती कुंजी-मूल्य जोड़े को एकत्रित करता है, अंतिम आउटपुट उत्पन्न करने के लिए उन्हें आगे संसाधित करता है। रिड्यूस फ़ंक्शन समान कुंजी साझा करने वाले मानों के प्रत्येक समूह पर लागू होता है। विशिष्ट उपयोग के मामले के आधार पर, रिड्यूस फ़ंक्शन का आउटपुट एचडीएफएस या किसी अन्य स्टोरेज सिस्टम पर वापस लिखा जाता है।
आइए MapReduce का उपयोग करके शब्द आवृत्ति की गणना के एक सरल उदाहरण पर विचार करें। टेक्स्ट दस्तावेज़ों वाले एक बड़े डेटासेट को देखते हुए, मैप फ़ंक्शन प्रत्येक दस्तावेज़ को व्यक्तिगत रूप से संसाधित करता है, प्रत्येक शब्द की घटनाओं की गणना करता है और शब्द-आवृत्ति जोड़े उत्सर्जित करता है। रिड्यूस चरण में, मैप फ़ंक्शन द्वारा उत्पन्न मध्यवर्ती कुंजी-मूल्य जोड़े को शब्द द्वारा एकत्रित किया जाता है, और कुल शब्द आवृत्तियों की गणना की जाती है, जिससे अंतिम आउटपुट उत्पन्न होता है।
MapReduce में एक अंतर्निहित दोष सहिष्णुता तंत्र भी है जो अन्य उपलब्ध नोड्स पर विफल कार्यों को स्वचालित रूप से पुनरारंभ कर सकता है, यह सुनिश्चित करता है कि व्यक्तिगत नोड्स की विफलता के बावजूद प्रसंस्करण जारी रहे।
AppMaster.io , बैकएंड, वेब और मोबाइल एप्लिकेशन विकसित करने के लिए एक शक्तिशाली नो-कोड प्लेटफ़ॉर्म, Hadoop-आधारित बड़े डेटा समाधानों का पूरक हो सकता है। AppMaster.io के साथ, आप वेब और मोबाइल एप्लिकेशन बना सकते हैं जो आपके बड़े डेटा आर्किटेक्चर द्वारा उत्पन्न और संग्रहीत डेटा को संसाधित और विश्लेषण करने के लिए HDFS और MapReduce जैसे Hadoop घटकों के साथ सहजता से एकीकृत होते हैं।
Hadoop और AppMaster.io दोनों के लाभों का लाभ उठाकर, व्यवसाय शक्तिशाली बड़े डेटा एप्लिकेशन बना सकते हैं जो Hadoop की स्केलेबिलिटी और दक्षता को no-code एप्लिकेशन डेवलपमेंट की गति और लागत-प्रभावशीलता के साथ जोड़ते हैं। AppMaster.io का सहज ज्ञान युक्त ड्रैग-एंड-ड्रॉप इंटरफ़ेस और विज़ुअल बिजनेस प्रोसेस डिज़ाइनर आपको गहन कोडिंग विशेषज्ञता की आवश्यकता के बिना जल्दी से एप्लिकेशन बनाने की अनुमति देता है, जिसके परिणामस्वरूप तेजी से बाजार में पहुंचने और विकास लागत में कमी आती है।
इसके अलावा, चूंकि AppMaster.io वास्तविक एप्लिकेशन उत्पन्न करता है जिन्हें ऑन-प्रिमाइसेस या क्लाउड में तैनात किया जा सकता है, आप अपने डेटा और एप्लिकेशन इंफ्रास्ट्रक्चर पर पूर्ण नियंत्रण बनाए रख सकते हैं। यह लचीलापन आपको आपके संगठन के आकार या उद्योग क्षेत्र की परवाह किए बिना, आपकी विशिष्ट आवश्यकताओं के अनुरूप एक व्यापक बड़ा डेटा समाधान बनाने की अनुमति देता है।
बड़े डेटा आर्किटेक्चर के लिए Hadoop के साथ AppMaster.io का उपयोग करने से कई फायदे मिल सकते हैं, जिनमें तेज़ एप्लिकेशन विकास, कम विकास लागत और बड़े पैमाने पर डेटासेट के प्रसंस्करण और विश्लेषण में दक्षता में वृद्धि शामिल है। दोनों प्लेटफार्मों की ताकत का लाभ उठाकर, व्यवसाय स्केलेबल बड़े डेटा एप्लिकेशन का निर्माण कर सकते हैं जो विकास को बढ़ावा देते हैं और मूल्यवान अंतर्दृष्टि प्रदान करते हैं।
आपके बड़े डेटा बुनियादी ढांचे के इष्टतम प्रदर्शन और प्रबंधन को सुनिश्चित करने के लिए Hadoop क्लस्टर के लिए सही तैनाती रणनीति का चयन करना महत्वपूर्ण है। Hadoop क्लस्टर स्थापित करते समय चुनने के लिए तीन प्राथमिक परिनियोजन मॉडल हैं:
ऑन-प्रिमाइसेस परिनियोजन में, Hadoop क्लस्टर आपके संगठन के स्वयं के डेटा केंद्रों का उपयोग करते हुए, इन-हाउस स्थापित और प्रबंधित किए जाते हैं। यह दृष्टिकोण कई लाभ प्रदान करता है, जैसे भौतिक सुरक्षा पर नियंत्रण, डेटा संप्रभुता और अनुपालन के लिए एक ज्ञात वातावरण। फिर भी, ऑन-प्रिमाइसेस तैनाती संसाधन-गहन हो सकती है, जिसके लिए हार्डवेयर, रखरखाव और आईटी कर्मियों में अधिक अग्रिम निवेश की आवश्यकता होती है। इसके अलावा, केवल भौतिक बुनियादी ढांचे पर निर्भर रहने पर संसाधनों को बढ़ाना चुनौतीपूर्ण हो सकता है।
Hadoop क्लस्टर की क्लाउड-आधारित तैनाती अमेज़ॅन वेब सर्विसेज (AWS) , Google क्लाउड प्लेटफ़ॉर्म (GCP), और Microsoft Azure जैसे क्लाउड प्लेटफ़ॉर्म की स्केलेबिलिटी, लचीलेपन और लागत-दक्षता का लाभ उठाती है। क्लाउड सेवा प्रदाता बुनियादी ढांचे के प्रबंधन की जिम्मेदारी लेता है, जिससे आपकी टीम को डेटा प्रोसेसिंग और विश्लेषण पर ध्यान केंद्रित करने की अनुमति मिलती है। क्लाउड-आधारित परिनियोजन 'पे-एज़-यू-गो' मूल्य निर्धारण मॉडल की पेशकश करते हैं, जिसका अर्थ है कि आप केवल उन संसाधनों के लिए भुगतान करते हैं जिनका आप उपभोग करते हैं। फिर भी, कुछ संगठनों को अपना डेटा तृतीय-पक्ष क्लाउड प्रदाताओं को सौंपते समय डेटा सुरक्षा और अनुपालन को लेकर चिंता हो सकती है।
एक हाइब्रिड परिनियोजन रणनीति ऑन-प्रिमाइसेस और क्लाउड-आधारित परिनियोजन दोनों की शक्तियों को जोड़ती है। इस मॉडल में, संवेदनशील डेटा और विनियमित कार्यभार ऑन-प्रिमाइसेस रह सकते हैं, जबकि अन्य कार्यभार और डेटा को लागत-दक्षता और स्केलेबिलिटी के लिए क्लाउड पर अपलोड किया जा सकता है। हाइब्रिड परिनियोजन संगठनों को क्लाउड कंप्यूटिंग द्वारा दिए जाने वाले लाभों का लाभ उठाते हुए नियंत्रण, सुरक्षा और लचीलेपन की उनकी आवश्यकताओं को संतुलित करने में सक्षम बनाता है।
प्रत्येक परिनियोजन मॉडल में फायदे और नुकसान हैं, इसलिए अपने Hadoop क्लस्टर के लिए सबसे उपयुक्त रणनीति चुनते समय लागत, स्केलेबिलिटी, रखरखाव, सुरक्षा और अनुपालन आवश्यकताओं पर विचार करना आवश्यक है।
विभिन्न बड़ी डेटा चुनौतियों का समाधान करने, मूल्यवान अंतर्दृष्टि निकालने के लिए संरचित और असंरचित डेटा की बड़ी मात्रा का विश्लेषण करने के लिए Apache Hadoop का व्यापक रूप से उद्योगों में उपयोग किया जाता है। यहां Hadoop के कुछ सामान्य वास्तविक जीवन अनुप्रयोग दिए गए हैं:
Apache Hadoop विभिन्न उद्योगों में बड़ी डेटा चुनौतियों का समाधान करने के लिए एक शक्तिशाली और बहुमुखी समाधान है। बड़े पैमाने पर डेटा भंडारण और प्रसंस्करण के लिए इस तकनीक को अपनाने के इच्छुक संगठनों के लिए इसके घटकों, लाभों, तैनाती रणनीतियों और उपयोग के मामलों को समझना आवश्यक है।
no-codeAppMaster प्लेटफॉर्म जैसे अन्य आधुनिक विकास दृष्टिकोणों के साथ Hadoop का संयोजन, व्यवसायों को एक व्यापक, स्केलेबल और कुशल डेटा प्रोसेसिंग पारिस्थितिकी तंत्र प्रदान करता है। सही रणनीति और परिनियोजन मॉडल के साथ, आपका संगठन Hadoop की शक्ति का उपयोग कर सकता है और बेहतर निर्णय लेने, अनुकूलन और नवाचार को चलाने के लिए बड़े डेटा की क्षमता का लाभ उठा सकता है।
थियोडोर लेविट की यह बात काफी हद तक सच है: "नवाचार उस चिंगारी की तरह है जो जीवन में बदलाव, सुधार और प्रगति लाता है।" जब हम Hadoop और AppMaster जोड़ते हैं, तो यह उस चिंगारी को पकड़ने जैसा होता है। यह गतिशील जोड़ी संगठनों को बड़े निर्णय लेने, बेहतर तरीके से काम करने और नए विचारों के साथ आने के लिए प्रेरित करती है। जैसे ही आप अपने रास्ते की योजना बनाते हैं, याद रखें कि बड़ा डेटा विकास की संभावनाओं के खजाने की तरह है। और सही उपकरणों के साथ, आप प्रगति और बेहतर समय का द्वार खोल रहे हैं।
Apache Hadoop एक ओपन-सोर्स फ्रेमवर्क है जिसे बड़ी मात्रा में डेटा को कुशलतापूर्वक संग्रहीत, संसाधित और विश्लेषण करने के लिए डिज़ाइन किया गया है। इसमें कई घटक शामिल हैं जो बड़े डेटा के विभिन्न पहलुओं को संभालने के लिए एक साथ काम करते हैं, जैसे स्टोरेज के लिए Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम (HDFS) और प्रोसेसिंग के लिए MapReduce। बड़े डेटा आर्किटेक्चर में, Hadoop एक आधारशिला के रूप में कार्य करता है, जो बड़े पैमाने पर डेटासेट से अंतर्दृष्टि प्राप्त करने और प्रबंधित करने के लिए बुनियादी ढांचा प्रदान करता है।
Apache Hadoop अपनी वितरित और समानांतर प्रसंस्करण क्षमताओं के माध्यम से बड़ी डेटा चुनौतियों का समाधान करता है। यह डेटा को छोटे-छोटे टुकड़ों में तोड़ देता है, जिन्हें परस्पर जुड़ी मशीनों के समूह में समानांतर रूप से संसाधित किया जाता है। यह दृष्टिकोण स्केलेबिलिटी, दोष सहनशीलता और प्रदर्शन को बढ़ाता है, जिससे बड़े पैमाने पर डेटा प्रोसेसिंग और विश्लेषण कार्यों को संभालना संभव हो जाता है।
Apache Hadoop मशीनों के एक समूह में डेटा भंडारण को प्रबंधित करने के लिए Hadoop डिस्ट्रीब्यूटेड फ़ाइल सिस्टम (HDFS) का उपयोग करता है। एचडीएफएस डेटा को ब्लॉकों में तोड़ता है, दोष सहनशीलता के लिए उनकी प्रतिकृति बनाता है, और उन्हें क्लस्टर में वितरित करता है। यह वितरित भंडारण वास्तुकला उच्च उपलब्धता और विश्वसनीयता सुनिश्चित करता है।
MapReduce Hadoop के भीतर एक प्रोग्रामिंग मॉडल और प्रोसेसिंग इंजन है जो वितरित डेटा प्रोसेसिंग को सक्षम बनाता है। यह कार्यों को दो चरणों में विभाजित करता है: डेटा प्रोसेसिंग के लिए "मानचित्र" चरण और एकत्रीकरण और संक्षेपण के लिए "कम" चरण। MapReduce डेवलपर्स को बड़ी संख्या में नोड्स में स्केल करने वाला कोड लिखने की अनुमति देता है, जो इसे बड़े डेटा के समानांतर प्रसंस्करण के लिए उपयुक्त बनाता है।
Apache Hadoop को एकीकृत करने में एक Hadoop क्लस्टर स्थापित करना शामिल है, जिसमें डेटा भंडारण और प्रसंस्करण के लिए जिम्मेदार कई नोड्स शामिल हैं। संगठन डेटा एक्सचेंज की सुविधा के लिए कनेक्टर्स और एपीआई का उपयोग करके मौजूदा सिस्टम और टूल के साथ Hadoop को तैनात कर सकते हैं। इसके अतिरिक्त, Hadoop विभिन्न डेटा अंतर्ग्रहण विधियों का समर्थन करता है, जो इसे विभिन्न स्रोतों से डेटा के साथ संगत बनाता है।
बड़ी डेटा प्रौद्योगिकियों में प्रगति के साथ-साथ Apache Hadoop का विकास जारी है। जबकि नए उपकरण और ढाँचे उभरे हैं, Hadoop कई बड़े डेटा पारिस्थितिकी तंत्रों का एक मूलभूत घटक बना हुआ है। इसकी मजबूती, लचीलापन और विविध डेटा प्रकारों को संभालने की क्षमता इसे बड़े डेटा की दुनिया में भविष्य के उपयोग के मामलों और चुनौतियों के लिए अच्छी स्थिति में रखती है।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


