Понятие распределенной файловой системы Hadoop (HDFS)
Распределенная файловая система Hadoop (HDFS) является одним из основополагающих компонентов фреймворка Apache Hadoop. Это распределенная, отказоустойчивая и масштабируемая файловая система, оптимизированная для управления большими объемами данных на крупных кластерах вычислительных узлов. HDFS предназначена для выполнения задач пакетной обработки данных и оптимизирована для больших потоковых операций чтения, что делает ее идеальной для использования в архитектуре больших данных.
HDFS хранит данные на нескольких узлах кластера, а репликация данных является ключевой функцией, обеспечивающей отказоустойчивость и высокую доступность. По умолчанию коэффициент репликации равен 3, но он может быть изменен в зависимости от конкретных требований к хранению и надежности данных. Данные делятся на блоки (по умолчанию размером 128 МБ) и распределяются по кластеру. Это позволяет хранить и обрабатывать данные как можно ближе к их источнику, уменьшая сетевые задержки и повышая производительность.
Основные компоненты HDFS
HDFS состоит из двух основных компонентов:
- NameNode: NameNode - это главный сервер HDFS, отвечающий за управление пространством имен, метаданными и состоянием файловой системы. Он поддерживает дерево файловой системы и метаданные для всех файлов и каталогов, а также обеспечивает правильную репликацию данных и ребалансировку блоков данных, когда это необходимо.
- DataNode: DataNode - это рабочие узлы в архитектуре HDFS, отвечающие за хранение и управление блоками данных на своих локальных устройствах хранения. DataNode взаимодействуют с NameNode для управления задачами хранения и репликации. Данные, хранящиеся на этих DataNode, обычно распределены по нескольким дискам, что обеспечивает высокий параллелизм в операциях с данными.
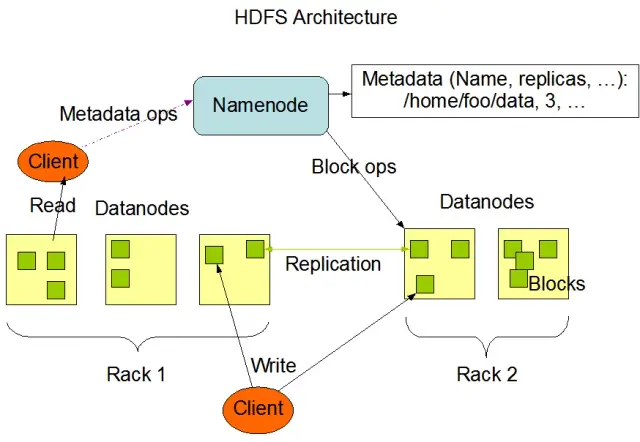
Источник изображения: Apache Hadoop
Операции HDFS
HDFS предоставляет различные файловые операции и поддерживает традиционные функции файловой системы, такие как создание, удаление и переименование файлов и каталогов. К основным операциям относятся:
- запись, чтение и удаление файлов
- создание и удаление каталогов
- Получение метаданных (таких как размер файла, расположение блоков и время доступа).
- Установка и извлечение пользовательских прав и квот.
Клиенты могут взаимодействовать с HDFS с помощью интерфейса командной строки Hadoop, Java API или веб-браузеров HDFS.
MapReduce: Механизм обработки Hadoop
MapReduce - это модель программирования и основной компонент Apache Hadoop, используемый для крупномасштабной распределенной обработки данных. Она позволяет разработчикам писать программы, способные параллельно обрабатывать огромные объемы данных на большом количестве узлов. Модель MapReduce основана на двух ключевых операциях: Map и Reduce.
Функция Map
На этапе Map входные данные разбиваются на фрагменты, и функция Map параллельно обрабатывает каждый фрагмент. Функция принимает пары ключ-значение на вход и генерирует промежуточные пары ключ-значение на выходе. Выходные пары сортируются по ключам, чтобы подготовить их к этапу Reduce.
Функция Reduce
На этапе Reduce происходит агрегирование промежуточных пар ключ-значение, сгенерированных функцией Map, и их дальнейшая обработка для получения конечного результата. Функция Reduce применяется к каждой группе значений с одинаковым ключом. Выходные данные функции Reduce записываются в HDFS или другую систему хранения, в зависимости от конкретного случая использования.
Пример MapReduce
Рассмотрим простой пример вычисления частоты слов с помощью MapReduce. При наличии большого набора данных, содержащего текстовые документы, функция Map обрабатывает каждый документ по отдельности, подсчитывает количество вхождений каждого слова и выдает пары "слово-частота". На этапе Reduce промежуточные пары ключ-значение, сформированные функцией Map, агрегируются по словам и вычисляются суммарные частоты слов, что позволяет получить конечный результат.
MapReduce также имеет встроенный механизм отказоустойчивости, который может автоматически перезапускать отказавшие задачи на других доступных узлах, обеспечивая продолжение обработки, несмотря на отказ отдельных узлов.
Как AppMaster.io дополняет решения Hadoop для работы с большими данными
AppMaster.io, мощная no-code платформа для разработки backend-, web- и мобильных приложений, может дополнить решения для работы с большими данными на базе Hadoop. С помощью AppMaster.io можно создавать веб- и мобильные приложения, которые легко интегрируются с компонентами Hadoop, такими как HDFS и MapReduce, для обработки и анализа данных, генерируемых и хранимых в архитектуре больших данных.
Используя преимущества Hadoop и AppMaster.io, компании могут создавать мощные приложения для работы с большими данными, сочетающие масштабируемость и эффективность Hadoop со скоростью и экономичностью разработки приложений на сайте no-code. Интуитивно понятный drag-and-drop интерфейс AppMaster.io и визуальный конструктор бизнес-процессов позволяют быстро создавать приложения, не требуя глубоких знаний в области кодирования, что приводит к сокращению времени выхода на рынок и снижению стоимости разработки.

Кроме того, поскольку на сайте AppMaster.io создаются реальные приложения, которые могут быть развернуты как в локальной сети, так и в облаке, вы можете полностью контролировать свои данные и инфраструктуру приложений. Такая гибкость позволяет создать комплексное решение для работы с большими данными, отвечающее конкретным потребностям организации, независимо от ее размера и отраслевой принадлежности.
Использование AppMaster.io в сочетании с Hadoop для архитектуры больших данных дает множество преимуществ, включая ускорение разработки приложений, снижение стоимости разработки и повышение эффективности обработки и анализа больших массивов данных. Используя сильные стороны обеих платформ, компании могут создавать масштабируемые приложения для работы с большими данными, которые способствуют росту и позволяют получать ценные сведения.
Стратегии развертывания кластеров Hadoop
Выбор правильной стратегии развертывания кластеров Hadoop имеет решающее значение для обеспечения оптимальной производительности и управления инфраструктурой больших данных. При создании кластеров Hadoop можно выбрать одну из трех основных моделей развертывания:
Развертывание в локальной сети
При локальном развертывании кластеры Hadoop создаются и управляются собственными силами, используя собственные центры обработки данных. Такой подход дает ряд преимуществ, таких как контроль над физической безопасностью, суверенитет данных и известная среда для соблюдения нормативных требований. Тем не менее, локальное развертывание может быть ресурсоемким, требующим больших первоначальных инвестиций в оборудование, обслуживание и ИТ-персонал. Кроме того, масштабирование ресурсов может быть затруднено, если опираться только на физическую инфраструктуру.
Облачное развертывание
Облачное развертывание кластеров Hadoop использует масштабируемость, гибкость и экономическую эффективность облачных платформ, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Поставщик облачных услуг берет на себя ответственность за управление инфраструктурой, позволяя вашим сотрудникам сосредоточиться на обработке и анализе данных. Облачные системы предлагают модели ценообразования с оплатой по факту использования, то есть вы платите только за потребляемые ресурсы. Тем не менее, некоторые организации могут испытывать опасения по поводу безопасности данных и соблюдения нормативных требований при передаче своих данных сторонним поставщикам облачных услуг.
Гибридное развертывание
Стратегия гибридного развертывания сочетает в себе сильные стороны локальных и облачных систем. В этой модели конфиденциальные данные и регулируемые рабочие нагрузки могут оставаться в локальной сети, а другие рабочие нагрузки и данные могут быть перенесены в "облако", что обеспечивает экономическую эффективность и масштабируемость. Гибридное развертывание позволяет организациям сбалансировать свои потребности в контроле, безопасности и гибкости, используя при этом преимущества облачных вычислений.
Каждая модель развертывания имеет свои плюсы и минусы, поэтому при выборе наиболее подходящей стратегии для кластера Hadoop необходимо учитывать стоимость, масштабируемость, требования к обслуживанию, безопасности и соответствию нормативным требованиям.
Примеры использования: Hadoop в реальных приложениях
Apache Hadoop широко используется в различных отраслях промышленности для решения различных задач, связанных с большими данными, анализируя большие объемы структурированных и неструктурированных данных для извлечения ценной информации. Вот несколько распространенных реальных применений Hadoop:
- Анализ журналов и потоков кликов: Hadoop может обрабатывать большие объемы журналов серверов и приложений, а также потоки кликов, генерируемые пользователями веб-сайтов. Анализ этих данных может помочь компаниям понять поведение пользователей, оптимизировать их работу и устранить проблемы с производительностью.
- Рекомендательные движки: Платформы электронной коммерции и поставщики контента используют Hadoop для анализа моделей просмотра и покупок клиентов с целью создания персонализированных рекомендаций по продуктам, услугам или контенту. Способность Hadoop обрабатывать огромные массивы данных и выполнять сложные вычисления делает его идеальным решением для рекомендательных систем.
- Обнаружение мошенничества: Финансовые и страховые компании используют Hadoop для анализа данных о транзакциях и выявления аномальных закономерностей, свидетельствующих о мошенничестве. Масштабируемые возможности параллельной обработки данных Hadoop позволяют организациям быстро выявлять и снижать потенциальные риски мошенничества.
- Анализ социальных сетей: Hadoop может обрабатывать большие объемы данных социальных сетей, включая профили пользователей, их взаимодействие и обмен контентом, что позволяет выявить тенденции и понять поведение людей, провести анализ настроений и разработать маркетинговые стратегии.
- Машинное обучение и предиктивная аналитика: Hadoop ускоряет машинное обучение и предиктивную аналитику за счет распараллеливания дорогостоящих алгоритмов на больших массивах данных. Предприятия могут использовать возможности Hadoop для разработки предиктивных моделей для прогнозирования спроса, оттока клиентов и других важных показателей.
- Расширение хранилища данных: Hadoop может быть интегрирован с традиционными системами хранения данных, что позволяет разгрузить некоторые рабочие нагрузки, например процессы извлечения, преобразования и загрузки данных (ETL), и повысить производительность. Такой подход позволяет компаниям сократить расходы, снизить нагрузку на существующую инфраструктуру и расширить аналитические возможности.
Заключение
Apache Hadoop - это мощное и универсальное решение для решения задач, связанных с большими данными, в различных отраслях. Понимание его компонентов, преимуществ, стратегий развертывания и вариантов использования необходимо организациям, стремящимся внедрить эту технологию для хранения и обработки крупномасштабных данных.
Сочетание Hadoop с другими современными подходами к разработке, например с платформой no-codeAppMaster, дает предприятиям комплексную, масштабируемую и эффективную экосистему обработки данных. При правильной стратегии и модели развертывания ваша организация сможет воспользоваться мощью Hadoop и использовать потенциал больших данных для принятия решений, оптимизации и инноваций.
В высказывании Теодора Левитта есть доля истины: "Инновации - это как искра, которая вызывает к жизни перемены, улучшения и прогресс". Когда мы объединяем Hadoop и AppMaster, мы словно улавливаем эту искру. Этот динамичный дуэт подталкивает организации к принятию важных решений, более умной работе и появлению свежих идей. Планируя свой путь, помните, что большие данные - это как сундук с сокровищами для роста. Правильно подобранные инструменты открывают дверь к прогрессу.






