
Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Khám phá các nguyên tắc cơ bản của Apache Hadoop và vai trò của nó trong kiến trúc dữ liệu lớn, bao gồm các thành phần, lợi ích và chiến lược triển khai của nó. Tìm hiểu cách nó phù hợp với hệ sinh thái dữ liệu hiện đại và hỗ trợ quá trình xử lý quy mô lớn.

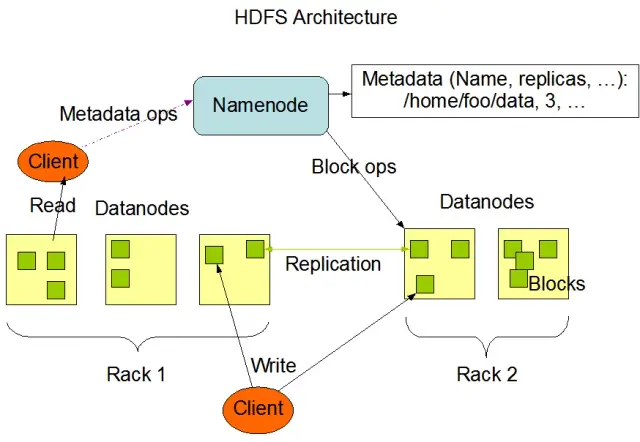
Hệ thống tệp phân tán Hadoop (HDFS) là một trong những thành phần cơ bản của khung Apache Hadoop. Đây là một hệ thống tệp phân tán, có khả năng chịu lỗi và có thể mở rộng được tối ưu hóa để quản lý khối lượng dữ liệu lớn trên các cụm nút tính toán lớn. HDFS được thiết kế để đáp ứng các tác vụ xử lý dữ liệu hàng loạt và được tối ưu hóa cao cho các hoạt động đọc trực tuyến, dung lượng lớn, khiến nó trở nên lý tưởng để sử dụng trong kiến trúc dữ liệu lớn.
HDFS lưu trữ dữ liệu trên nhiều nút trong một cụm, với tính năng chính là sao chép dữ liệu để đảm bảo khả năng chịu lỗi và tính sẵn sàng cao. Hệ số sao chép mặc định là 3, nhưng nó có thể được điều chỉnh để đáp ứng nhu cầu của các yêu cầu về độ tin cậy và lưu trữ dữ liệu cụ thể. Dữ liệu được chia thành các khối (theo mặc định, kích thước 128 MB) và được phân phối trên toàn cụm. Điều này đảm bảo dữ liệu được lưu trữ và xử lý càng gần nguồn càng tốt, giảm độ trễ mạng và cải thiện hiệu suất.
Có hai thành phần chính của HDFS:
Nguồn hình ảnh: Apache Hadoop
HDFS cung cấp các thao tác tệp khác nhau và hỗ trợ các tính năng của hệ thống tệp truyền thống, chẳng hạn như tạo, xóa và đổi tên tệp và thư mục. Các hoạt động chính bao gồm:
Khách hàng có thể tương tác với HDFS bằng giao diện dòng lệnh Hadoop, API Java hoặc trình duyệt HDFS dựa trên web.
MapReduce là một mô hình lập trình và là thành phần cốt lõi của Apache Hadoop được sử dụng để xử lý dữ liệu phân tán, quy mô lớn. Nó cho phép các nhà phát triển viết các chương trình có thể xử lý song song một lượng lớn dữ liệu trên một số lượng lớn các nút. Mô hình MapReduce dựa trên hai hoạt động chính: Bản đồ và Giảm.
Trong giai đoạn Bản đồ, dữ liệu đầu vào được chia thành các phần và chức năng Bản đồ xử lý song song từng phần. Hàm lấy các cặp khóa-giá trị làm đầu vào và tạo các cặp khóa-giá trị trung gian làm đầu ra. Các cặp đầu ra được sắp xếp theo khóa để chuẩn bị cho giai đoạn Giảm.
Giai đoạn Giảm tổng hợp các cặp khóa-giá trị trung gian do hàm Bản đồ tạo ra, xử lý thêm chúng để tạo ra kết quả cuối cùng. Hàm Giảm được áp dụng cho từng nhóm giá trị chia sẻ cùng một khóa. Đầu ra của chức năng Giảm được ghi trở lại HDFS hoặc hệ thống lưu trữ khác, tùy thuộc vào trường hợp sử dụng cụ thể.
Hãy xem xét một ví dụ đơn giản về tính toán tần số từ bằng MapReduce. Với một tập dữ liệu lớn chứa các tài liệu văn bản, hàm Map xử lý từng tài liệu riêng lẻ, đếm số lần xuất hiện của từng từ và đưa ra các cặp từ-tần suất. Trong giai đoạn Giảm, các cặp khóa-giá trị trung gian do hàm Bản đồ tạo ra được tổng hợp theo từ và tổng tần số từ được tính toán, tạo ra kết quả cuối cùng.
MapReduce cũng có một cơ chế chịu lỗi tích hợp có thể tự động khởi động lại các tác vụ không thành công trên các nút có sẵn khác, đảm bảo quá trình xử lý vẫn tiếp tục bất chấp lỗi của các nút riêng lẻ.
AppMaster.io , một nền tảng không cần mã mạnh mẽ để phát triển các ứng dụng phụ trợ, web và di động, có thể bổ sung cho các giải pháp dữ liệu lớn dựa trên Hadoop. Với AppMaster.io, bạn có thể xây dựng các ứng dụng web và di động tích hợp liền mạch với các thành phần Hadoop, chẳng hạn như HDFS và MapReduce, để xử lý và phân tích dữ liệu do kiến trúc dữ liệu lớn của bạn tạo và lưu trữ.
Bằng cách tận dụng các lợi ích của cả Hadoop và AppMaster.io, các doanh nghiệp có thể tạo các ứng dụng dữ liệu lớn mạnh mẽ kết hợp khả năng mở rộng và hiệu quả của Hadoop với tốc độ và hiệu quả chi phí của việc phát triển ứng dụng no-code. Giao diện kéo và thả trực quan của AppMaster.io và trình thiết kế quy trình kinh doanh trực quan cho phép bạn xây dựng các ứng dụng một cách nhanh chóng mà không cần kiến thức chuyên sâu về mã hóa, dẫn đến thời gian đưa ra thị trường nhanh hơn và giảm chi phí phát triển.
Hơn nữa, do AppMaster.io tạo ra các ứng dụng thực có thể được triển khai tại chỗ hoặc trên đám mây, nên bạn có thể duy trì toàn quyền kiểm soát dữ liệu và cơ sở hạ tầng ứng dụng của mình. Tính linh hoạt này cho phép bạn tạo giải pháp dữ liệu lớn toàn diện phù hợp với nhu cầu cụ thể của mình, bất kể quy mô tổ chức hoặc lĩnh vực công nghiệp của bạn.
Việc sử dụng AppMaster.io kết hợp với Hadoop cho kiến trúc dữ liệu lớn có thể mang lại nhiều lợi ích, bao gồm phát triển ứng dụng nhanh hơn, giảm chi phí phát triển và tăng hiệu quả trong việc xử lý và phân tích các bộ dữ liệu quy mô lớn. Bằng cách tận dụng điểm mạnh của cả hai nền tảng, các doanh nghiệp có thể xây dựng các ứng dụng dữ liệu lớn có thể mở rộng để thúc đẩy tăng trưởng và cung cấp thông tin chi tiết có giá trị.
Chọn chiến lược triển khai phù hợp cho các cụm Hadoop là rất quan trọng để đảm bảo hiệu suất và quản lý tối ưu cơ sở hạ tầng dữ liệu lớn của bạn. Có ba mô hình triển khai chính để chọn khi thiết lập cụm Hadoop:
Trong quá trình triển khai tại chỗ, các cụm Hadoop được thiết lập và quản lý nội bộ, sử dụng các trung tâm dữ liệu của chính tổ chức của bạn. Cách tiếp cận này mang lại một số lợi thế, chẳng hạn như kiểm soát bảo mật vật lý, chủ quyền dữ liệu và môi trường tuân thủ đã biết. Tuy nhiên, việc triển khai tại chỗ có thể tốn nhiều tài nguyên, đòi hỏi đầu tư nhiều hơn vào phần cứng, bảo trì và nhân sự CNTT. Ngoài ra, việc mở rộng quy mô tài nguyên có thể là một thách thức khi chỉ dựa vào cơ sở hạ tầng vật lý.
Việc triển khai các cụm Hadoop dựa trên đám mây thúc đẩy khả năng mở rộng, tính linh hoạt và hiệu quả chi phí của các nền tảng đám mây, chẳng hạn như Amazon Web Services (AWS) , Google Cloud Platform (GCP) và Microsoft Azure . Nhà cung cấp dịch vụ đám mây chịu trách nhiệm quản lý cơ sở hạ tầng, cho phép nhóm của bạn tập trung vào xử lý và phân tích dữ liệu. Việc triển khai dựa trên đám mây cung cấp các mô hình định giá trả theo mức sử dụng, nghĩa là bạn chỉ trả tiền cho những tài nguyên mà bạn sử dụng. Tuy nhiên, một số tổ chức có thể lo ngại về bảo mật dữ liệu và tuân thủ khi ủy thác dữ liệu của họ cho các nhà cung cấp đám mây bên thứ ba.
Chiến lược triển khai kết hợp kết hợp các điểm mạnh của cả triển khai tại chỗ và trên nền tảng đám mây. Trong mô hình này, dữ liệu nhạy cảm và khối lượng công việc được quản lý có thể vẫn ở tại chỗ, trong khi khối lượng công việc và dữ liệu khác có thể được chuyển sang đám mây để tiết kiệm chi phí và khả năng mở rộng. Việc triển khai kết hợp cho phép các tổ chức cân bằng nhu cầu kiểm soát, bảo mật và tính linh hoạt trong khi tận dụng các lợi ích do điện toán đám mây mang lại.
Mỗi mô hình triển khai đều có ưu và nhược điểm, do đó, điều cần thiết là phải xem xét các yêu cầu về chi phí, khả năng mở rộng, bảo trì, bảo mật và tuân thủ khi chọn chiến lược phù hợp nhất cho cụm Hadoop của bạn.
Apache Hadoop được sử dụng rộng rãi trong các ngành để giải quyết các thách thức dữ liệu lớn khác nhau, phân tích khối lượng lớn dữ liệu có cấu trúc và phi cấu trúc để trích xuất những hiểu biết có giá trị. Dưới đây là một số ứng dụng thực tế phổ biến của Hadoop:
Apache Hadoop là một giải pháp mạnh mẽ và linh hoạt để giải quyết các thách thức về dữ liệu lớn trong các ngành khác nhau. Hiểu các thành phần, lợi ích, chiến lược triển khai và trường hợp sử dụng của nó là điều cần thiết đối với các tổ chức đang tìm cách áp dụng công nghệ này để lưu trữ và xử lý dữ liệu quy mô lớn.
Kết hợp Hadoop với các phương pháp phát triển hiện đại khác, chẳng hạn như nền tảng AppMasterno-code, mang đến cho doanh nghiệp một hệ sinh thái xử lý dữ liệu toàn diện, có thể mở rộng và hiệu quả. Với mô hình triển khai và chiến lược phù hợp, tổ chức của bạn có thể khai thác sức mạnh của Hadoop và tận dụng tiềm năng của dữ liệu lớn để thúc đẩy quá trình ra quyết định, tối ưu hóa và đổi mới tốt hơn.
Câu nói của Theodore Levitt có rất nhiều sự thật: "Đổi mới giống như tia lửa mang lại sự thay đổi, cải tiến và tiến bộ cho cuộc sống." Khi chúng tôi kết hợp Hadoop và AppMaster, nó giống như bắt được tia lửa đó. Bộ đôi năng động này thúc đẩy các tổ chức đưa ra quyết định lớn, làm việc thông minh hơn và đưa ra những ý tưởng mới. Khi bạn lên kế hoạch cho con đường của mình, hãy nhớ rằng dữ liệu lớn giống như một kho báu chứa đựng các khả năng phát triển. Và với các công cụ phù hợp, bạn đang mở ra cánh cửa để tiến bộ và có thời gian tốt đẹp hơn.
Apache Hadoop là một khung mã nguồn mở được thiết kế để lưu trữ, xử lý và phân tích khối lượng dữ liệu lớn một cách hiệu quả. Nó bao gồm nhiều thành phần hoạt động cùng nhau để xử lý các khía cạnh khác nhau của dữ liệu lớn, chẳng hạn như Hệ thống tệp phân tán Hadoop (HDFS) để lưu trữ và MapReduce để xử lý. Trong kiến trúc dữ liệu lớn, Hadoop đóng vai trò là nền tảng, cung cấp cơ sở hạ tầng để quản lý và thu thập thông tin chuyên sâu từ các bộ dữ liệu lớn.
Apache Hadoop giải quyết các thách thức về dữ liệu lớn thông qua khả năng xử lý song song và phân tán của nó. Nó chia dữ liệu thành các phần nhỏ hơn, được xử lý song song trên một cụm máy được kết nối với nhau. Cách tiếp cận này nâng cao khả năng mở rộng, khả năng chịu lỗi và hiệu suất, giúp xử lý các tác vụ phân tích và xử lý dữ liệu quy mô lớn trở nên khả thi.
Apache Hadoop sử dụng Hệ thống tệp phân tán Hadoop (HDFS) để quản lý lưu trữ dữ liệu trên một cụm máy. HDFS chia dữ liệu thành các khối, sao chép chúng để có khả năng chịu lỗi và phân phối chúng trên toàn cụm. Kiến trúc lưu trữ phân tán này đảm bảo tính khả dụng và độ tin cậy cao.
MapReduce là một mô hình lập trình và công cụ xử lý trong Hadoop cho phép xử lý dữ liệu phân tán. Nó chia các nhiệm vụ thành hai giai đoạn: giai đoạn "bản đồ" để xử lý dữ liệu và giai đoạn "rút gọn" để tổng hợp và tóm tắt. MapReduce cho phép các nhà phát triển viết mã mở rộng trên một số lượng lớn các nút, làm cho nó phù hợp để xử lý song song dữ liệu lớn.
Tích hợp Apache Hadoop liên quan đến việc thiết lập cụm Hadoop, bao gồm nhiều nút chịu trách nhiệm lưu trữ và xử lý dữ liệu. Các tổ chức có thể triển khai Hadoop cùng với các hệ thống và công cụ hiện có, sử dụng trình kết nối và API để hỗ trợ trao đổi dữ liệu. Ngoài ra, Hadoop hỗ trợ nhiều phương thức nhập dữ liệu khác nhau, làm cho nó tương thích với dữ liệu từ nhiều nguồn khác nhau.
Apache Hadoop tiếp tục phát triển cùng với những tiến bộ trong công nghệ dữ liệu lớn. Trong khi các công cụ và khuôn khổ mới hơn đã xuất hiện, Hadoop vẫn là một thành phần cơ bản của nhiều hệ sinh thái dữ liệu lớn. Tính mạnh mẽ, tính linh hoạt và khả năng xử lý các loại dữ liệu đa dạng giúp nó phù hợp với các trường hợp sử dụng và thách thức trong tương lai trong thế giới dữ liệu lớn.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


