
Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj podstawy Apache Hadoop i jego rolę w architekturze Big Data, w tym jego komponenty, korzyści i strategie wdrażania. Dowiedz się, jak pasuje do nowoczesnych ekosystemów danych i ułatwia przetwarzanie na dużą skalę.

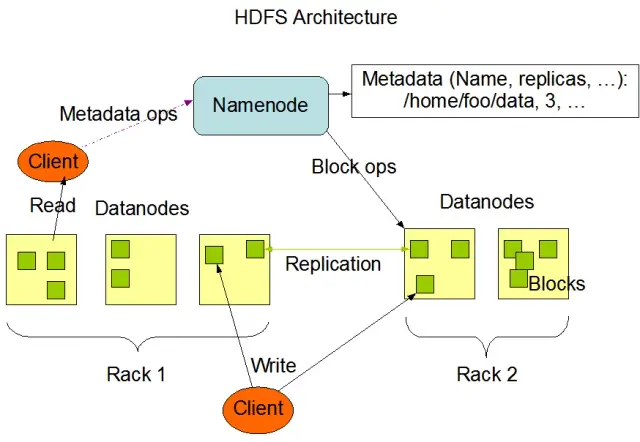
Rozproszony system plików Hadoop (HDFS) jest jednym z podstawowych elementów frameworka Apache Hadoop. Jest to rozproszony, odporny na błędy i skalowalny system plików zoptymalizowany do zarządzania dużymi ilościami danych w dużych klastrach węzłów obliczeniowych. HDFS został zaprojektowany z myślą o zadaniach przetwarzania danych wsadowych i jest wysoce zoptymalizowany pod kątem dużych, strumieniowych operacji odczytu, dzięki czemu idealnie nadaje się do stosowania w architekturze big data.
HDFS przechowuje dane na wielu węzłach w klastrze, z replikacją danych jako kluczową funkcją zapewniającą odporność na błędy i wysoką dostępność. Domyślny współczynnik replikacji wynosi 3, ale można go dostosować do potrzeb konkretnego przechowywania danych i wymagań niezawodności. Dane są dzielone na bloki (domyślnie o rozmiarze 128 MB) i dystrybuowane w klastrze. Zapewnia to przechowywanie i przetwarzanie danych jak najbliżej ich źródła, zmniejszając opóźnienia sieciowe i poprawiając wydajność.
Istnieją dwa podstawowe składniki HDFS:
Źródło obrazu: Apache Hadoop
HDFS zapewnia różne operacje na plikach i obsługuje tradycyjne funkcje systemu plików, takie jak tworzenie, usuwanie i zmiana nazw plików i katalogów. Podstawowe operacje obejmują:
Klienci mogą wchodzić w interakcje z HDFS za pomocą interfejsu wiersza poleceń Hadoop, interfejsów API Java lub internetowych przeglądarek HDFS.
MapReduce to model programowania i podstawowy komponent Apache Hadoop wykorzystywany do rozproszonego przetwarzania danych na dużą skalę. Pozwala on programistom na pisanie programów, które mogą przetwarzać ogromne ilości danych równolegle na dużej liczbie węzłów. Model MapReduce opiera się na dwóch kluczowych operacjach: Map i Reduce.
Na etapie Map dane wejściowe są dzielone na fragmenty, a funkcja Map przetwarza każdy fragment równolegle. Funkcja pobiera pary klucz-wartość jako dane wejściowe i generuje pośrednie pary klucz-wartość jako dane wyjściowe. Pary wyjściowe są sortowane według klucza, aby przygotować je do etapu Reduce.
Etap Reduce agreguje pośrednie pary klucz-wartość wygenerowane przez funkcję Map, przetwarzając je dalej w celu uzyskania ostatecznego wyniku. Funkcja Reduce jest stosowana do każdej grupy wartości o tym samym kluczu. Dane wyjściowe funkcji Reduce są zapisywane z powrotem w HDFS lub innym systemie pamięci masowej, w zależności od konkretnego przypadku użycia.
Rozważmy prosty przykład obliczania częstotliwości występowania słów przy użyciu MapReduce. Biorąc pod uwagę duży zbiór danych zawierający dokumenty tekstowe, funkcja Map przetwarza każdy dokument indywidualnie, zliczając wystąpienia każdego słowa i emitując pary słowo-częstotliwość. Na etapie Reduce pośrednie pary klucz-wartość wygenerowane przez funkcję Map są agregowane według słów i obliczane są całkowite częstotliwości słów, tworząc ostateczne dane wyjściowe.
MapReduce ma również wbudowany mechanizm odporności na błędy, który może automatycznie ponownie uruchamiać nieudane zadania na innych dostępnych węzłach, zapewniając kontynuację przetwarzania pomimo awarii poszczególnych węzłów.
AppMaster. io, potężna platforma no-code do tworzenia aplikacji backendowych, internetowych i mobilnych, może uzupełniać rozwiązania big data oparte na Hadoop. Dzięki AppMaster.io można tworzyć aplikacje internetowe i mobilne, które płynnie integrują się z komponentami Hadoop, takimi jak HDFS i MapReduce, w celu przetwarzania i analizowania danych generowanych i przechowywanych przez architekturę big data.
Wykorzystując zalety zarówno Hadoop, jak i AppMaster.io, firmy mogą tworzyć potężne aplikacje big data, które łączą skalowalność i wydajność Hadoop z szybkością i opłacalnością tworzenia aplikacji no-code. AppMaster Intuicyjny interfejs .io typu " przeciągnij i upuść " oraz wizualny projektant procesów biznesowych pozwalają na szybkie tworzenie aplikacji bez konieczności posiadania dogłębnej wiedzy w zakresie kodowania, co skutkuje szybszym wprowadzeniem na rynek i obniżeniem kosztów rozwoju.
Co więcej, ponieważ AppMaster.io generuje rzeczywiste aplikacje, które można wdrażać lokalnie lub w chmurze, można zachować pełną kontrolę nad danymi i infrastrukturą aplikacji. Ta elastyczność pozwala na stworzenie kompleksowego rozwiązania big data dostosowanego do konkretnych potrzeb, niezależnie od wielkości organizacji czy sektora przemysłu.
Korzystanie z AppMaster.io w połączeniu z Hadoop dla architektury big data może zapewnić liczne korzyści, w tym szybsze tworzenie aplikacji, niższe koszty rozwoju i większą wydajność w przetwarzaniu i analizowaniu dużych zbiorów danych. Wykorzystując mocne strony obu platform, firmy mogą tworzyć skalowalne aplikacje big data, które napędzają wzrost i dostarczają cennych informacji.
Wybór odpowiedniej strategii wdrażania klastrów Hadoop ma kluczowe znaczenie dla zapewnienia optymalnej wydajności i zarządzania infrastrukturą Big Data. Istnieją trzy podstawowe modele wdrażania do wyboru podczas konfigurowania klastrów Hadoop:
We wdrożeniu lokalnym klastry Hadoop są konfigurowane i zarządzane wewnętrznie, z wykorzystaniem własnych centrów danych organizacji. Takie podejście oferuje szereg korzyści, takich jak kontrola nad bezpieczeństwem fizycznym, suwerenność danych i znane środowisko zgodności. Wdrożenia lokalne mogą być jednak zasobochłonne, wymagając większych początkowych inwestycji w sprzęt, konserwację i personel IT. Ponadto skalowanie zasobów może być trudne, gdy opiera się wyłącznie na infrastrukturze fizycznej.
Wdrażanie klastrów Hadoop w chmurze wykorzystuje skalowalność, elastyczność i opłacalność platform chmurowych, takich jak Amazon Web Services (AWS), Google Cloud Platform (GCP) i Microsoft Azure. Dostawca usług w chmurze przejmuje odpowiedzialność za zarządzanie infrastrukturą, pozwalając zespołowi skupić się na przetwarzaniu i analizie danych. Wdrożenia oparte na chmurze oferują modele cenowe pay-as-you-go, co oznacza, że płacisz tylko za zużyte zasoby. Mimo to niektóre organizacje mogą mieć obawy dotyczące bezpieczeństwa danych i zgodności z przepisami, powierzając swoje dane zewnętrznym dostawcom usług w chmurze.
Strategia wdrożeń hybrydowych łączy w sobie mocne strony wdrożeń lokalnych i chmurowych. W tym modelu wrażliwe dane i regulowane obciążenia mogą pozostać w środowisku lokalnym, podczas gdy inne obciążenia i dane mogą zostać przeniesione do chmury w celu zapewnienia opłacalności i skalowalności. Wdrożenie hybrydowe umożliwia organizacjom zrównoważenie potrzeb w zakresie kontroli, bezpieczeństwa i elastyczności przy jednoczesnym wykorzystaniu korzyści oferowanych przez chmurę obliczeniową.
Każdy model wdrożenia ma swoje plusy i minusy, więc przy wyborze najbardziej odpowiedniej strategii dla klastra Hadoop należy wziąć pod uwagę koszty, skalowalność, konserwację, bezpieczeństwo i wymagania dotyczące zgodności.
Apache Hadoop jest szeroko stosowany w różnych branżach, aby sprostać różnym wyzwaniom związanym z dużymi zbiorami danych, analizując duże ilości ustrukturyzowanych i nieustrukturyzowanych danych w celu uzyskania cennych informacji. Oto kilka typowych, rzeczywistych zastosowań Hadoop:
Apache Hadoop to potężne i wszechstronne rozwiązanie pozwalające sprostać wyzwaniom związanym z dużymi zbiorami danych w różnych branżach. Zrozumienie jego komponentów, korzyści, strategii wdrażania i przypadków użycia jest niezbędne dla organizacji, które chcą wdrożyć tę technologię do przechowywania i przetwarzania danych na dużą skalę.
Połączenie Hadoop z innymi nowoczesnymi podejściami programistycznymi, takimi jak platforma no-codeAppMaster, oferuje firmom kompleksowy, skalowalny i wydajny ekosystem przetwarzania danych. Dzięki odpowiedniej strategii i modelowi wdrażania, Twoja organizacja może wykorzystać moc Hadoop i wykorzystać potencjał dużych zbiorów danych do lepszego podejmowania decyzji, optymalizacji i innowacji.
Powiedzenie Theodore'a Levitta zawiera w sobie wiele prawdy: "Innowacja jest jak iskra, która ożywia zmiany, ulepszenia i postęp". Kiedy łączymy Hadoop i AppMaster, jest to jak uchwycenie tej iskry. Ten dynamiczny duet popycha organizacje do podejmowania ważnych decyzji, mądrzejszej pracy i wymyślania nowych pomysłów. Planując swoją drogę, pamiętaj, że duże zbiory danych są jak skarbnica możliwości rozwoju. A dzięki odpowiednim narzędziom otwierasz drzwi do postępu i lepszych czasów.
Apache Hadoop to platforma typu open-source przeznaczona do wydajnego przechowywania, przetwarzania i analizowania dużych ilości danych. Składa się z wielu komponentów, które współpracują ze sobą w celu obsługi różnych aspektów dużych zbiorów danych, takich jak Hadoop Distributed File System (HDFS) do przechowywania i MapReduce do przetwarzania. W architekturze big data, Hadoop działa jako kamień węgielny, zapewniając infrastrukturę do zarządzania i pozyskiwania informacji z ogromnych zbiorów danych.
Apache Hadoop odpowiada na wyzwania związane z dużymi zbiorami danych dzięki możliwościom przetwarzania rozproszonego i równoległego. Dzieli dane na mniejsze fragmenty, które są przetwarzane równolegle w klastrze połączonych ze sobą maszyn. Takie podejście zwiększa skalowalność, odporność na awarie i wydajność, umożliwiając obsługę zadań przetwarzania i analizy danych na dużą skalę.
Apache Hadoop wykorzystuje Hadoop Distributed File System (HDFS) do zarządzania przechowywaniem danych w klastrze maszyn. HDFS dzieli dane na bloki, replikuje je w celu zapewnienia odporności na błędy i dystrybuuje je w klastrze. Ta rozproszona architektura pamięci masowej zapewnia wysoką dostępność i niezawodność.
MapReduce to model programowania i silnik przetwarzania w Hadoop, który umożliwia rozproszone przetwarzanie danych. Dzieli on zadania na dwie fazy: fazę "map" do przetwarzania danych i fazę "reduce" do agregacji i podsumowania. MapReduce umożliwia programistom pisanie kodu, który skaluje się na dużej liczbie węzłów, dzięki czemu nadaje się do równoległego przetwarzania dużych zbiorów danych.
Integracja Apache Hadoop obejmuje utworzenie klastra Hadoop, który składa się z wielu węzłów odpowiedzialnych za przechowywanie i przetwarzanie danych. Organizacje mogą wdrożyć Hadoop wraz z istniejącymi systemami i narzędziami, wykorzystując konektory i interfejsy API w celu ułatwienia wymiany danych. Ponadto Hadoop obsługuje różne metody pozyskiwania danych, dzięki czemu jest kompatybilny z danymi z różnych źródeł.
Apache Hadoop wciąż ewoluuje wraz z rozwojem technologii Big Data. Chociaż pojawiły się nowsze narzędzia i frameworki, Hadoop pozostaje podstawowym składnikiem wielu ekosystemów big data. Jego solidność, elastyczność i zdolność do obsługi różnych typów danych sprawiają, że dobrze nadaje się do przyszłych zastosowań i wyzwań w świecie dużych zbiorów danych.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


