
App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Ontdek de basisprincipes van Apache Hadoop en de rol ervan in big data-architectuur, waaronder de componenten, voordelen en implementatiestrategieën. Leer hoe Hadoop past in moderne data-ecosystemen en grootschalige verwerking mogelijk maakt.

Het Hadoop Distributed File System (HDFS) is een van de fundamentele onderdelen van het Apache Hadoop framework. Het is een gedistribueerd, fouttolerant en schaalbaar bestandssysteem dat is geoptimaliseerd voor het beheren van grote hoeveelheden gegevens op grote clusters van rekenknooppunten. HDFS is ontworpen voor batchverwerkingstaken en is sterk geoptimaliseerd voor grote, streaming leesbewerkingen, waardoor het ideaal is voor gebruik in big data-architecturen.
HDFS slaat gegevens op op meerdere knooppunten in een cluster, met datareplicatie als een belangrijke functie om fouttolerantie en hoge beschikbaarheid te garanderen. De standaard replicatiefactor is 3, maar kan worden aangepast aan de behoeften van de specifieke gegevensopslag en betrouwbaarheidseisen. Gegevens worden verdeeld in blokken (standaard 128 MB groot) en verdeeld over het cluster. Dit zorgt ervoor dat de gegevens zo dicht mogelijk bij de bron worden opgeslagen en verwerkt, waardoor de netwerklatentie afneemt en de prestaties verbeteren.
Er zijn twee hoofdonderdelen van HDFS:
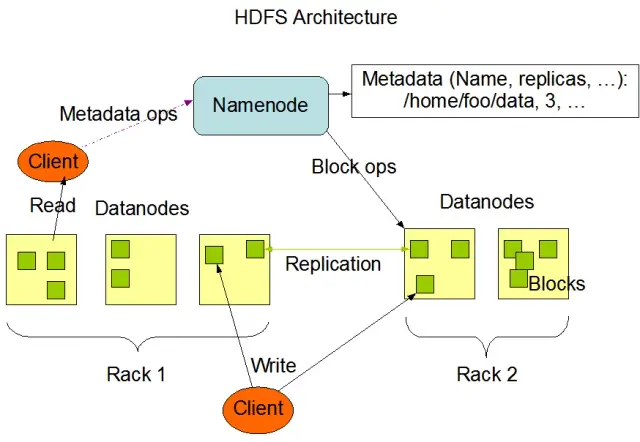
Bron afbeelding: Apache Hadoop
HDFS biedt verschillende bestandsoperaties en ondersteunt traditionele bestandssysteemfuncties, zoals het maken, verwijderen en hernoemen van bestanden en mappen. De primaire bewerkingen zijn
Klanten kunnen communiceren met HDFS via de Hadoop command-line interface, Java API's of webgebaseerde HDFS browsers.
MapReduce is een programmeermodel en een kernonderdeel van Apache Hadoop dat wordt gebruikt voor grootschalige, gedistribueerde gegevensverwerking. Het stelt ontwikkelaars in staat om programma's te schrijven die enorme hoeveelheden gegevens parallel kunnen verwerken op een groot aantal knooppunten. Het MapReduce-model is gebaseerd op twee belangrijke bewerkingen: Map en Reduce.
In de Map-fase worden de invoergegevens opgedeeld in chunks en de Map-functie verwerkt elke chunk parallel. De functie neemt sleutelwaardeparen als invoer en genereert tussenliggende sleutelwaardeparen als uitvoer. De uitvoerparen worden gesorteerd op sleutel om ze voor te bereiden op de Reduce-fase.
De reductiefase voegt de tussenliggende sleutelwaardeparen samen die door de mapfunctie zijn gegenereerd en verwerkt ze verder om de uiteindelijke uitvoer te produceren. De Reduce-functie wordt toegepast op elke groep waarden die dezelfde sleutel delen. De uitvoer van de Reduce-functie wordt teruggeschreven naar HDFS of een ander opslagsysteem, afhankelijk van het specifieke gebruik.
Laten we eens kijken naar een eenvoudig voorbeeld van het berekenen van woordfrequentie met MapReduce. Gegeven een grote dataset met tekstdocumenten, verwerkt de Map-functie elk document afzonderlijk, telt de voorkomens van elk woord en stuurt de woord-frequentieparen. In de Reduce-fase worden de tussenliggende sleutelwaardeparen die door de Map-functie zijn gegenereerd, samengevoegd per woord en worden de totale woordfrequenties berekend, wat de uiteindelijke uitvoer oplevert.
MapReduce heeft ook een ingebouwd fouttolerantiemechanisme dat mislukte taken automatisch kan herstarten op andere beschikbare knooppunten, zodat de verwerking doorgaat ondanks het falen van individuele knooppunten.
AppMaster.io, een krachtig no-code platform voor het ontwikkelen van backend-, web- en mobiele toepassingen, kan Hadoop-gebaseerde Big Data-oplossingen aanvullen. Met AppMaster.io kunt u web- en mobiele toepassingen bouwen die naadloos integreren met Hadoop-componenten, zoals HDFS en MapReduce, om de gegevens te verwerken en te analyseren die door uw Big Data-architectuur worden gegenereerd en opgeslagen.
Door gebruik te maken van de voordelen van Hadoop en AppMaster.io kunnen bedrijven krachtige big data-applicaties maken die de schaalbaarheid en efficiëntie van Hadoop combineren met de snelheid en kosteneffectiviteit van no-code applicatieontwikkeling. AppMaster Met de intuïtieve drag-and-drop interface en visuele ontwerper van bedrijfsprocessen van .io kunt u snel toepassingen bouwen zonder diepgaande codeerexpertise, wat resulteert in een snellere time-to-market en lagere ontwikkelingskosten.
Aangezien AppMaster.io echte applicaties genereert die op locatie of in de cloud kunnen worden geïmplementeerd, behoudt u bovendien de volledige controle over uw gegevens en applicatie-infrastructuur. Dankzij deze flexibiliteit kunt u een allesomvattende big data-oplossing creëren die is afgestemd op uw specifieke behoeften, ongeacht de grootte van uw organisatie of de sector waarin u actief bent.
Het gebruik van AppMaster.io in combinatie met Hadoop voor big data-architectuur kan tal van voordelen bieden, zoals snellere applicatieontwikkeling, lagere ontwikkelingskosten en meer efficiëntie bij het verwerken en analyseren van grootschalige datasets. Door de sterke punten van beide platformen te benutten, kunnen bedrijven schaalbare big data-applicaties bouwen die groei stimuleren en waardevolle inzichten opleveren.
Het kiezen van de juiste implementatiestrategie voor Hadoop-clusters is cruciaal om optimale prestaties en beheer van uw big data-infrastructuur te garanderen. Er zijn drie primaire implementatiemodellen waaruit u kunt kiezen bij het opzetten van Hadoop-clusters:
Bij een on-premises implementatie worden Hadoop-clusters intern opgezet en beheerd, met behulp van de datacenters van uw organisatie. Deze aanpak biedt verschillende voordelen, zoals controle over fysieke beveiliging, gegevenssoevereiniteit en een bekende omgeving voor compliance. Toch kunnen on-premises implementaties veel middelen vergen, omdat er vooraf meer moet worden geïnvesteerd in hardware, onderhoud en IT-personeel. Ook het schalen van resources kan een uitdaging zijn als je alleen op fysieke infrastructuur vertrouwt.
Cloudgebaseerde implementatie van Hadoop-clusters maakt gebruik van de schaalbaarheid, flexibiliteit en kostenefficiëntie van cloudplatforms, zoals Amazon Web Services (AWS), Google Cloud Platform (GCP) en Microsoft Azure. De cloudserviceprovider neemt de verantwoordelijkheid voor het infrastructuurbeheer, zodat uw team zich kan richten op gegevensverwerking en -analyse. Cloudgebaseerde implementaties bieden pay-as-you-go prijsmodellen, wat betekent dat u alleen betaalt voor de bronnen die u gebruikt. Toch kunnen sommige organisaties zich zorgen maken over gegevensbeveiliging en compliance wanneer ze hun gegevens toevertrouwen aan externe cloudproviders.
Een hybride implementatiestrategie combineert de sterke punten van zowel on-premises als cloudgebaseerde implementaties. In dit model kunnen gevoelige gegevens en gereguleerde workloads op locatie blijven, terwijl andere workloads en gegevens kunnen worden overgeheveld naar de cloud voor kostenefficiëntie en schaalbaarheid. Een hybride implementatie stelt organisaties in staat om hun behoefte aan controle, beveiliging en flexibiliteit in balans te brengen en tegelijkertijd te profiteren van de voordelen die cloud computing biedt.
Elk implementatiemodel heeft voor- en nadelen, dus het is essentieel om rekening te houden met kosten, schaalbaarheid, onderhoud, beveiliging en compliance-eisen bij het kiezen van de meest geschikte strategie voor uw Hadoop-cluster.
Apache Hadoop wordt veel gebruikt in verschillende sectoren om verschillende Big Data uitdagingen aan te gaan, waarbij grote hoeveelheden gestructureerde en ongestructureerde gegevens worden geanalyseerd om waardevolle inzichten te verkrijgen. Hier zijn enkele veelvoorkomende toepassingen van Hadoop:
Apache Hadoop is een krachtige en veelzijdige oplossing voor het aanpakken van big data-uitdagingen in verschillende sectoren. Inzicht in de componenten, voordelen, implementatiestrategieën en use cases is essentieel voor organisaties die deze technologie willen gebruiken voor grootschalige gegevensopslag en -verwerking.
De combinatie van Hadoop met andere moderne ontwikkelingsbenaderingen, zoals het no-codeAppMaster platform, biedt bedrijven een uitgebreid, schaalbaar en efficiënt ecosysteem voor gegevensverwerking. Met de juiste strategie en het juiste implementatiemodel kan uw organisatie de kracht van Hadoop benutten en profiteren van het potentieel van Big Data om betere besluitvorming, optimalisatie en innovatie te stimuleren.
Het gezegde van Theodore Levitt bevat veel waarheid: "Innovatie is als de vonk die verandering, verbetering en vooruitgang tot leven brengt." Wanneer we Hadoop en AppMaster combineren, is het net alsof we die vonk vangen. Dit dynamische duo zet organisaties aan om grote beslissingen te nemen, slimmer te werken en met frisse ideeën te komen. Onthoud bij het uitstippelen van je pad dat big data als een schatkist vol groeimogelijkheden is. En met de juiste tools open je de deur naar vooruitgang en betere tijden.
Apache Hadoop is een open-source framework dat is ontworpen om grote hoeveelheden gegevens efficiënt op te slaan, te verwerken en te analyseren. Het bestaat uit meerdere componenten die samenwerken om verschillende aspecten van big data te verwerken, zoals Hadoop Distributed File System (HDFS) voor opslag en MapReduce voor verwerking. In de big data-architectuur fungeert Hadoop als hoeksteen en biedt het de infrastructuur om enorme datasets te beheren en er inzichten uit af te leiden.
Apache Hadoop pakt de uitdagingen van grote gegevens aan met zijn gedistribueerde en parallelle verwerkingsmogelijkheden. Het verdeelt gegevens in kleinere brokken, die parallel worden verwerkt in een cluster van onderling verbonden machines. Deze aanpak verbetert de schaalbaarheid, fouttolerantie en prestaties, waardoor het haalbaar wordt om grootschalige gegevensverwerkings- en analysetaken uit te voeren.
Apache Hadoop gebruikt het Hadoop Distributed File System (HDFS) om gegevensopslag in een cluster van machines te beheren. HDFS verdeelt gegevens in blokken, repliceert ze voor fouttolerantie en verdeelt ze over het cluster. Deze gedistribueerde opslagarchitectuur zorgt voor een hoge beschikbaarheid en betrouwbaarheid.
MapReduce is een programmeermodel en verwerkingsengine binnen Hadoop die gedistribueerde gegevensverwerking mogelijk maakt. Het verdeelt taken in twee fasen: de "map"-fase voor gegevensverwerking en de "reduce"-fase voor aggregatie en samenvatting. Met MapReduce kunnen ontwikkelaars code schrijven die over een groot aantal nodes wordt geschaald, waardoor het geschikt is voor parallelle verwerking van grote gegevens.
De integratie van Apache Hadoop omvat het opzetten van een Hadoop-cluster, dat bestaat uit meerdere knooppunten die verantwoordelijk zijn voor de opslag en verwerking van gegevens. Organisaties kunnen Hadoop naast bestaande systemen en tools implementeren en connectoren en API's gebruiken om gegevensuitwisseling te vergemakkelijken. Bovendien ondersteunt Hadoop verschillende methoden voor gegevensinvoer, waardoor het compatibel is met gegevens uit verschillende bronnen.
Apache Hadoop blijft zich ontwikkelen naast de vooruitgang in big data-technologieën. Hoewel er nieuwere tools en frameworks zijn gekomen, blijft Hadoop een fundamenteel onderdeel van veel big data ecosystemen. De robuustheid, flexibiliteit en het vermogen om verschillende soorten gegevens te verwerken, maken Hadoop geschikt voor toekomstige gebruikssituaties en uitdagingen in de wereld van big data.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


