
App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Esplorate i fondamenti di Apache Hadoop e il suo ruolo nell'architettura dei big data, compresi i suoi componenti, i vantaggi e le strategie di distribuzione. Scoprite come si inserisce nei moderni ecosistemi di dati e come facilita l'elaborazione su larga scala.

L'Hadoop Distributed File System (HDFS) è uno dei componenti fondamentali del framework Apache Hadoop. È un file system distribuito, tollerante agli errori e scalabile, ottimizzato per la gestione di grandi volumi di dati su grandi cluster di nodi di calcolo. HDFS è stato progettato per gestire le attività di elaborazione dei dati in batch ed è altamente ottimizzato per le operazioni di lettura in streaming di grandi dimensioni, il che lo rende ideale per l'utilizzo nell'architettura dei big data.
HDFS archivia i dati su più nodi di un cluster e la replica dei dati è una caratteristica fondamentale per garantire la tolleranza agli errori e l'alta disponibilità. Il fattore di replica predefinito è 3, ma può essere regolato per soddisfare le esigenze specifiche di archiviazione e affidabilità dei dati. I dati vengono suddivisi in blocchi (per impostazione predefinita, di 128 MB) e distribuiti nel cluster. In questo modo i dati vengono archiviati ed elaborati il più vicino possibile alla loro origine, riducendo la latenza di rete e migliorando le prestazioni.
I componenti principali di HDFS sono due:
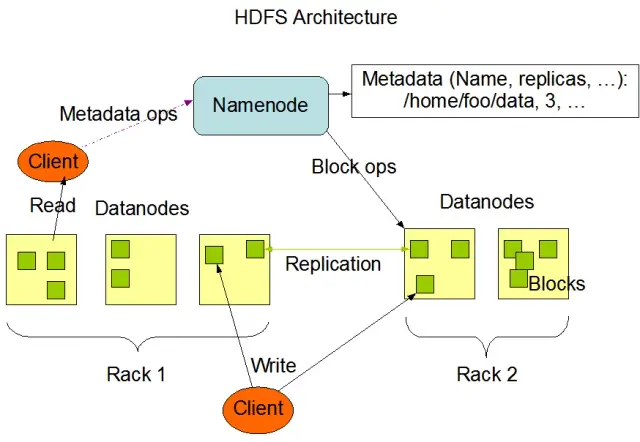
Fonte dell'immagine: Apache Hadoop
HDFS fornisce diverse operazioni sui file e supporta le funzioni tradizionali del file system, come la creazione, l'eliminazione e la ridenominazione di file e directory. Le operazioni principali includono:
I client possono interagire con HDFS utilizzando l'interfaccia a riga di comando di Hadoop, le API Java o i browser HDFS basati sul web.
MapReduce è un modello di programmazione e un componente fondamentale di Apache Hadoop utilizzato per l'elaborazione di dati distribuiti su larga scala. Consente agli sviluppatori di scrivere programmi in grado di elaborare grandi quantità di dati in parallelo su un gran numero di nodi. Il modello MapReduce si basa su due operazioni chiave: Map e Reduce.
Nella fase di Map, i dati in ingresso vengono suddivisi in pezzi e la funzione Map elabora ogni pezzo in parallelo. La funzione prende in ingresso coppie chiave-valore e genera coppie intermedie chiave-valore in uscita. Le coppie in uscita vengono ordinate per chiave per prepararle alla fase Reduce.
Lo stadio Reduce aggrega le coppie chiave-valore intermedie generate dalla funzione Map, elaborandole ulteriormente per produrre l'output finale. La funzione Reduce viene applicata a ogni gruppo di valori che condividono la stessa chiave. L'output della funzione Reduce viene scritto su HDFS o su un altro sistema di archiviazione, a seconda del caso d'uso specifico.
Consideriamo un semplice esempio di calcolo della frequenza delle parole utilizzando MapReduce. Dato un grande set di dati contenente documenti di testo, la funzione Map elabora ogni documento individualmente, contando le occorrenze di ogni parola ed emettendo le coppie parola-frequenza. Nella fase Reduce, le coppie chiave-valore intermedie generate dalla funzione Map vengono aggregate per parola e le frequenze totali delle parole vengono calcolate, producendo l'output finale.
MapReduce ha anche un meccanismo di tolleranza agli errori incorporato che può riavviare automaticamente i task falliti su altri nodi disponibili, assicurando che l'elaborazione continui nonostante il fallimento dei singoli nodi.
AppMaster.io, una potente piattaforma no-code per lo sviluppo di applicazioni backend, web e mobili, può integrare le soluzioni big data basate su Hadoop. Con AppMaster.io, è possibile creare applicazioni web e mobili che si integrano perfettamente con i componenti Hadoop, come HDFS e MapReduce, per elaborare e analizzare i dati generati e archiviati dalla vostra architettura di big data.
Sfruttando i vantaggi di Hadoop e di AppMaster.io, le aziende possono creare potenti applicazioni di big data che combinano la scalabilità e l'efficienza di Hadoop con la velocità e l'economicità dello sviluppo di applicazioni no-code. AppMaster L'interfaccia intuitiva drag-and-drop e il designer visuale dei processi aziendali di .io consentono di creare rapidamente applicazioni senza bisogno di competenze approfondite in materia di codifica, con conseguente accelerazione del time-to-market e riduzione dei costi di sviluppo.
Inoltre, poiché AppMaster.io genera applicazioni reali che possono essere distribuite on-premises o nel cloud, è possibile mantenere il pieno controllo sui dati e sull'infrastruttura applicativa. Questa flessibilità vi permette di creare una soluzione completa per i big data su misura per le vostre esigenze specifiche, indipendentemente dalle dimensioni o dal settore industriale della vostra organizzazione.
L'utilizzo di AppMaster.io in combinazione con Hadoop per l'architettura dei big data può offrire numerosi vantaggi, tra cui uno sviluppo più rapido delle applicazioni, una riduzione dei costi di sviluppo e una maggiore efficienza nell'elaborazione e nell'analisi di set di dati su larga scala. Sfruttando i punti di forza di entrambe le piattaforme, le aziende possono creare applicazioni scalabili per i big data che favoriscono la crescita e forniscono informazioni preziose.
La scelta della giusta strategia di distribuzione per i cluster Hadoop è fondamentale per garantire prestazioni e gestione ottimali dell'infrastruttura di big data. Per la creazione di cluster Hadoop è possibile scegliere tra tre modelli di distribuzione principali:
In una distribuzione on-premises, i cluster Hadoop sono configurati e gestiti internamente, utilizzando i data center dell'organizzazione. Questo approccio offre diversi vantaggi, come il controllo sulla sicurezza fisica, la sovranità dei dati e un ambiente noto per la conformità. Tuttavia, l'implementazione on-premise può richiedere un notevole dispendio di risorse, con maggiori investimenti iniziali in hardware, manutenzione e personale IT. Inoltre, la scalabilità delle risorse può essere difficile quando ci si affida alla sola infrastruttura fisica.
La distribuzione di cluster Hadoop basata sul cloud sfrutta la scalabilità, la flessibilità e l'efficienza economica delle piattaforme cloud, come Amazon Web Services (AWS), Google Cloud Platform (GCP) e Microsoft Azure. Il fornitore di servizi cloud si assume la responsabilità della gestione dell'infrastruttura, consentendo al team di concentrarsi sull'elaborazione e sull'analisi dei dati. Le implementazioni basate sul cloud offrono modelli di prezzo pay-as-you-go, il che significa che si paga solo per le risorse consumate. Tuttavia, alcune organizzazioni potrebbero avere dei dubbi sulla sicurezza dei dati e sulla conformità quando affidano i loro dati a provider cloud di terze parti.
Una strategia di distribuzione ibrida combina i punti di forza delle distribuzioni on-premise e di quelle basate sul cloud. In questo modello, i dati sensibili e i carichi di lavoro regolamentati possono rimanere on-premise, mentre altri carichi di lavoro e dati possono essere scaricati sul cloud per ottenere efficienza e scalabilità dei costi. Un'implementazione ibrida consente alle organizzazioni di bilanciare le proprie esigenze di controllo, sicurezza e flessibilità, sfruttando al contempo i vantaggi offerti dal cloud computing.
Ogni modello di distribuzione ha pro e contro, quindi è essenziale considerare i costi, la scalabilità, la manutenzione, la sicurezza e i requisiti di conformità quando si sceglie la strategia più adatta per il cluster Hadoop.
Apache Hadoop è ampiamente utilizzato in tutti i settori per affrontare diverse sfide legate ai big data, analizzando grandi volumi di dati strutturati e non strutturati per estrarre informazioni preziose. Ecco alcune comuni applicazioni di Hadoop nella vita reale:
Apache Hadoop è una soluzione potente e versatile per affrontare le sfide dei big data in vari settori. La comprensione dei suoi componenti, dei vantaggi, delle strategie di implementazione e dei casi d'uso è essenziale per le organizzazioni che desiderano adottare questa tecnologia per l'archiviazione e l'elaborazione dei dati su larga scala.
La combinazione di Hadoop con altri approcci di sviluppo moderni, come la piattaforma no-codeAppMaster, offre alle aziende un ecosistema di elaborazione dei dati completo, scalabile ed efficiente. Con la giusta strategia e il giusto modello di implementazione, la vostra azienda può sfruttare la potenza di Hadoop e capitalizzare il potenziale dei big data per migliorare il processo decisionale, l'ottimizzazione e l'innovazione.
L'affermazione di Theodore Levitt è molto vera: "L'innovazione è come la scintilla che dà vita al cambiamento, al miglioramento e al progresso". Quando combiniamo Hadoop e AppMaster, è come catturare quella scintilla. Questo duo dinamico spinge le organizzazioni a prendere decisioni importanti, a lavorare in modo più intelligente e a proporre idee nuove. Nel pianificare il vostro percorso, ricordate che i big data sono come uno scrigno di possibilità di crescita. E con gli strumenti giusti, aprirete la porta al progresso e a tempi migliori.
Apache Hadoop è un framework open-source progettato per archiviare, elaborare e analizzare in modo efficiente grandi volumi di dati. Comprende diversi componenti che lavorano insieme per gestire vari aspetti dei big data, come Hadoop Distributed File System (HDFS) per l'archiviazione e MapReduce per l'elaborazione. Nell'architettura dei big data, Hadoop funge da pietra angolare, fornendo l'infrastruttura per gestire e ricavare informazioni da enormi insiemi di dati.
Apache Hadoop affronta le sfide dei big data grazie alle sue capacità di elaborazione distribuita e parallela. Scompone i dati in pezzi più piccoli, che vengono elaborati in parallelo su un cluster di macchine interconnesse. Questo approccio migliora la scalabilità, la tolleranza agli errori e le prestazioni, rendendo possibile la gestione di attività di elaborazione e analisi dei dati su larga scala.
Apache Hadoop utilizza l'Hadoop Distributed File System (HDFS) per gestire l'archiviazione dei dati in un cluster di macchine. HDFS suddivide i dati in blocchi, li replica per garantire la tolleranza agli errori e li distribuisce nel cluster. Questa architettura di archiviazione distribuita garantisce un'elevata disponibilità e affidabilità.
MapReduce è un modello di programmazione e un motore di elaborazione all'interno di Hadoop che consente l'elaborazione distribuita dei dati. Divide le attività in due fasi: la fase "map" per l'elaborazione dei dati e la fase "reduce" per l'aggregazione e la sintesi. MapReduce consente agli sviluppatori di scrivere codice scalabile su un gran numero di nodi, rendendolo adatto all'elaborazione parallela dei big data.
L'integrazione di Apache Hadoop comporta la creazione di un cluster Hadoop, che comprende più nodi responsabili dell'archiviazione e dell'elaborazione dei dati. Le organizzazioni possono implementare Hadoop insieme ai sistemi e agli strumenti esistenti, utilizzando connettori e API per facilitare lo scambio di dati. Inoltre, Hadoop supporta diversi metodi di ingestione dei dati, rendendolo compatibile con i dati provenienti da varie fonti.
Apache Hadoop continua a evolversi insieme ai progressi delle tecnologie per i big data. Sebbene siano emersi nuovi strumenti e framework, Hadoop rimane un componente fondamentale di molti ecosistemi di big data. La sua robustezza, flessibilità e capacità di gestire diversi tipi di dati lo posizionano bene per i casi d'uso e le sfide future nel mondo dei big data.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


