



Equipment reservation app: prevent conflicts and track returns
Plan an equipment reservation app that prevents double bookings, records returns and damage, and places faulty items on maintenance hold.
Explore the fundamentals of Apache Hadoop and its role in big data architecture, including its components, benefits, and deployment strategies. Learn how it fits into modern data ecosystems and facilitates large-scale processing.

The Hadoop Distributed File System (HDFS) is one of the fundamental components of the Apache Hadoop framework. It is a distributed, fault-tolerant, and scalable file system optimized for managing large volumes of data across large clusters of compute nodes. HDFS is designed to accommodate batch-data processing tasks and is highly optimized for large, streaming read operations, making it ideal for use in big data architecture.
HDFS stores data across multiple nodes in a cluster, with data replication as a key feature to ensure fault tolerance and high availability. The default replication factor is 3, but it can be adjusted to meet the needs of the specific data storage and reliability requirements. Data is divided into blocks (by default, 128 MB in size) and distributed across the cluster. This ensures the data is stored and processed as close to its source as possible, reducing network latency and improving performance.
There are two primary components of HDFS:
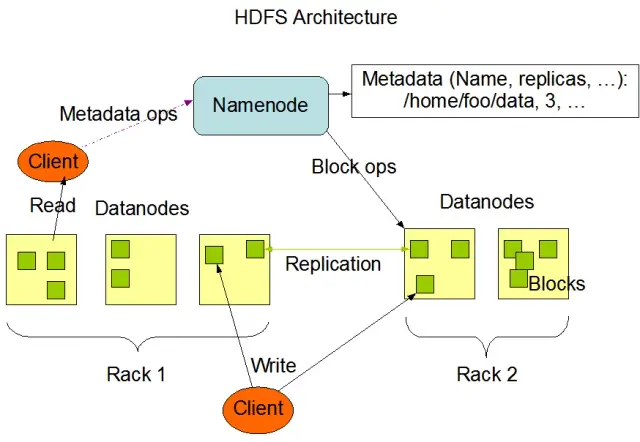
Image source: Apache Hadoop
HDFS provides various file operations and supports traditional file system features, such as creating, deleting, and renaming files and directories. The primary operations include:
Clients can interact with HDFS using the Hadoop command-line interface, Java APIs, or web-based HDFS browsers.
MapReduce is a programming model and a core component of Apache Hadoop used for large-scale, distributed data processing. It allows developers to write programs that can process vast amounts of data in parallel across a large number of nodes. The MapReduce model is based on two key operations: Map and Reduce.
In the Map stage, the input data is divided into chunks, and the Map function processes each chunk in parallel. The function takes key-value pairs as input and generates intermediate key-value pairs as output. The output pairs are sorted by key to prepare them for the Reduce stage.
The Reduce stage aggregates the intermediate key-value pairs generated by the Map function, processing them further to produce the final output. The Reduce function is applied to each group of values sharing the same key. The output of the Reduce function is written back to HDFS or another storage system, depending on the specific use case.
Let's consider a simple example of calculating word frequency using MapReduce. Given a large dataset containing text documents, the Map function processes each document individually, counting the occurrences of each word and emitting the word-frequency pairs. In the Reduce stage, the intermediate key-value pairs generated by the Map function are aggregated by word, and the total word frequencies are computed, producing the final output.
MapReduce also has a built-in fault tolerance mechanism that can automatically restart failed tasks on other available nodes, ensuring the processing continues despite the failure of individual nodes.
AppMaster.io, a powerful no-code platform for developing backend, web, and mobile applications, can complement Hadoop-based big data solutions. With AppMaster.io, you can build web and mobile applications that seamlessly integrate with Hadoop components, such as HDFS and MapReduce, to process and analyze the data generated and stored by your big data architecture.
By leveraging the benefits of both Hadoop and AppMaster.io, businesses can create powerful big data applications that combine the scalability and efficiency of Hadoop with the speed and cost-effectiveness of no-code application development. AppMaster.io's intuitive drag-and-drop interface and visual business process designer allow you to build applications quickly without needing in-depth coding expertise, resulting in faster time-to-market and reduced development costs.
Moreover, since AppMaster.io generates real applications that can be deployed on-premises or in the cloud, you can maintain full control over your data and application infrastructure. This flexibility allows you to create a comprehensive big data solution tailored to your specific needs, regardless of your organization's size or industry sector.
Using AppMaster.io in conjunction with Hadoop for big data architecture can provide numerous advantages, including faster application development, reduced development costs, and increased efficiency in processing and analyzing large-scale datasets. By leveraging the strengths of both platforms, businesses can build scalable big data applications that drive growth and deliver valuable insights.
Selecting the right deployment strategy for Hadoop clusters is crucial to ensuring optimal performance and management of your big data infrastructure. There are three primary deployment models to choose from when setting up Hadoop clusters:
In an on-premises deployment, Hadoop clusters are set up and managed in-house, utilizing your organization's own data centers. This approach offers several advantages, such as control over physical security, data sovereignty, and a known environment for compliance. Still, on-premises deployments can be resource-intensive, requiring more upfront investment in hardware, maintenance, and IT personnel. Also, scaling resources can be challenging when relying on physical infrastructure alone.
Cloud-based deployment of Hadoop clusters leverages the scalability, flexibility, and cost-efficiency of cloud platforms, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. The cloud service provider takes responsibility for infrastructure management, allowing your team to focus on data processing and analysis. Cloud-based deployments offer pay-as-you-go pricing models, meaning you only pay for the resources you consume. Still, some organizations may have concerns over data security and compliance when entrusting their data to third-party cloud providers.
A hybrid deployment strategy combines the strengths of both on-premises and cloud-based deployments. In this model, sensitive data and regulated workloads can remain on-premises, while other workloads and data can be offloaded to the cloud for cost-efficiency and scalability. A hybrid deployment enables organizations to balance their needs for control, security, and flexibility while taking advantage of the benefits offered by cloud computing.
Each deployment model has pros and cons, so it's essential to consider cost, scalability, maintenance, security, and compliance requirements when choosing the most suitable strategy for your Hadoop cluster.
Apache Hadoop is widely used across industries to address various big data challenges, analyzing large volumes of structured and unstructured data to extract valuable insights. Here are some common real-life applications of Hadoop:
Apache Hadoop is a powerful and versatile solution for addressing big data challenges in various industries. Understanding its components, benefits, deployment strategies, and use cases is essential for organizations seeking to adopt this technology for large-scale data storage and processing.
Combining Hadoop with other modern development approaches, like the no-codeAppMaster platform, offers businesses a comprehensive, scalable, and efficient data processing ecosystem. With the right strategy and deployment model, your organization can harness the power of Hadoop and capitalize on the potential of big data to drive better decision-making, optimization, and innovation.
The saying from Theodore Levitt holds a lot of truth: "Innovation is like the spark that brings change, improvement, and progress to life." When we combine Hadoop and AppMaster, it's like capturing that spark. This dynamic duo pushes organizations to make big decisions, work smarter, and come up with fresh ideas. As you plan your path, remember that big data is like a treasure chest of possibilities for growth. And with the right tools, you're opening the door to progress and better times.
Apache Hadoop is an open-source framework designed to efficiently store, process, and analyze large volumes of data. It comprises multiple components that work together to handle various aspects of big data, such as Hadoop Distributed File System (HDFS) for storage and MapReduce for processing. In big data architecture, Hadoop acts as a cornerstone, providing the infrastructure to manage and derive insights from massive datasets.
Apache Hadoop addresses big data challenges through its distributed and parallel processing capabilities. It breaks down data into smaller chunks, which are processed in parallel across a cluster of interconnected machines. This approach enhances scalability, fault tolerance, and performance, making it feasible to handle large-scale data processing and analysis tasks.
Apache Hadoop employs the Hadoop Distributed File System (HDFS) to manage data storage across a cluster of machines. HDFS breaks data into blocks, replicates them for fault tolerance, and distributes them across the cluster. This distributed storage architecture ensures high availability and reliability.
MapReduce is a programming model and processing engine within Hadoop that enables distributed data processing. It divides tasks into two phases: the "map" phase for data processing and the "reduce" phase for aggregation and summarization. MapReduce allows developers to write code that scales across a large number of nodes, making it suitable for parallel processing of big data.
Integrating Apache Hadoop involves setting up a Hadoop cluster, which comprises multiple nodes responsible for data storage and processing. Organizations can deploy Hadoop alongside existing systems and tools, using connectors and APIs to facilitate data exchange. Additionally, Hadoop supports various data ingestion methods, making it compatible with data from various sources.
Apache Hadoop continues to evolve alongside advancements in big data technologies. While newer tools and frameworks have emerged, Hadoop remains a fundamental component of many big data ecosystems. Its robustness, flexibility, and ability to handle diverse data types position it well for future use cases and challenges in the world of big data.
Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


