Dans le domaine du développement web, l'interface frontale recueille une part importante de l'attention en raison de son attrait visuel et de son interaction directe avec les utilisateurs. Cependant, c'est l'architecture web dorsale qui forme l'épine dorsale de toute plateforme en ligne, garantissant des performances sans faille et un traitement efficace des données. En tant que pierre angulaire du développement web moderne, un système back-end robuste est indispensable pour répondre aux exigences de sites web et d'applications de plus en plus sophistiqués.
Cet article de blog approfondi vise à examiner en détail l'architecture web back-end, ses composants intégraux et les technologies avancées employées pour la construire et la maintenir. Nous nous pencherons sur les différents éléments, tels que les langages de programmation côté serveur, les bases de données, les configurations de serveur et les mécanismes de mise en cache, qui contribuent à une infrastructure back-end bien orchestrée. En outre, nous discuterons des pratiques et des méthodologies de pointe pour optimiser les performances du système, maintenir la sécurité des données et assurer l'évolutivité.
Destiné aux développeurs expérimentés, aux professionnels de l'informatique et à tous ceux qui s'intéressent de près aux aspects techniques du développement web, cet article offre une compréhension complète des rouages complexes de l'architecture web dorsale. En mettant l'accent à la fois sur les concepts fondamentaux et les tendances émergentes, nous visons à fournir des informations précieuses et des connaissances pratiques qui peuvent être appliquées à des scénarios du monde réel. Rejoignez-nous pour disséquer les rouages de l'architecture web back-end et explorer la puissante force qui régit les performances des plateformes en ligne modernes.
Quels sont les clients ?
Dans le domaine du développement logiciel, les clients jouent un rôle essentiel car ils représentent la couche utilisateur qui interagit avec l'architecture web back-end. Les clients sont généralement des navigateurs web, des applications mobiles ou d'autres applications logicielles qui facilitent la communication avec un serveur.
Ces clients transmettent des demandes au serveur par l'intermédiaire du protocole de transfert hypertexte (HTTP), qui traite ensuite la demande et renvoie une réponse correspondante. Un aspect essentiel du développement côté client est la mise en œuvre d'une interface utilisateur (UI) et d'une expérience utilisateur (UX) transparentes, garantissant que les utilisateurs peuvent effectivement s'engager dans les caractéristiques et les fonctionnalités de l'application.
Il est important de noter que les clients varient en complexité et en forme, allant de simples pages HTML avec CSS et JavaScript de base à des applications monopages complexes (SPA) construites avec des frameworks frontaux modernes comme React, Angular ou Vue.js. Ces frameworks permettent aux développeurs de créer des interfaces utilisateur hautement interactives et dynamiques, contribuant ainsi au succès global de l'application web.
Un client bien conçu améliore l'expérience de l'utilisateur et assure une communication efficace avec l'architecture dorsale. Pour ce faire, il utilise des interfaces de programmation d'applications (API) pour envoyer et recevoir des données, qui peuvent se présenter sous la forme d'un transfert d'état représentationnel (REST) ou de GraphQL API, entre autres.
Qu'est-ce qu'un back-end ?
Le back-end, également appelé côté serveur, est le moteur caché de toute application web. Il englobe la logique, le stockage des données et les fonctions de sécurité nécessaires au bon fonctionnement et à la fiabilité de l'application. Le back-end est chargé de traiter les demandes des clients, d'interagir avec les bases de données et de générer les réponses appropriées à renvoyer au client.
Dans une architecture web back-end typique, les développeurs utilisent des langages côté serveur tels que Python, Golang, Java, PHP ou Node.js, qui permettent la création d'une logique et de fonctionnalités personnalisées. Associés à des cadres côté serveur tels que Django, Ruby on Rails, Spring, Laravel ou Express.js, ces langages rationalisent le processus de développement et facilitent la mise en œuvre d'applications web efficaces, évolutives et faciles à maintenir.
La base de données, qui stocke et gère les données au sein de l'application, est un composant essentiel du back-end. Les bases de données peuvent être relationnelles, comme MySQL, PostgreSQL ou Microsoft SQL Server, ou non relationnelles (NoSQL), comme MongoDB, Cassandra ou Couchbase. Le choix d'une base de données dépend des exigences de l'application, de la structure des données et des besoins d'évolutivité.
En outre, les développeurs du back-end doivent mettre en œuvre des mesures de sécurité appropriées pour protéger les données sensibles et se prémunir contre les vulnérabilités telles que l'injection SQL ou les attaques de type cross-site scripting (XSS). Ces mesures comprennent l'authentification de l'utilisateur, l'autorisation et le cryptage des données pendant la transmission et le stockage.
Qu'est-ce qu'un serveur ?
Dans le contexte de l'architecture web back-end, un serveur est une machine physique ou virtuelle chargée d'héberger, de traiter et de gérer les ressources nécessaires à l'exécution d'une application web. Les serveurs reçoivent les demandes des clients, exécutent la logique nécessaire et renvoient les réponses par le biais d'un protocole de communication, généralement HTTP.
Les serveurs peuvent être sur site, dans un centre de données, ou hébergés sur des plateformes en nuage comme Amazon Web Services (AWS), Microsoft Azure ou Google Cloud Platform (GCP). Les solutions basées sur le cloud offrent une flexibilité, une évolutivité et une rentabilité accrues en permettant aux développeurs d'utiliser un modèle de paiement à l'utilisation et d'allouer dynamiquement les ressources en fonction de la demande.
Les serveurs web, tels qu'Apache, Nginx ou Microsoft Internet Information Services (IIS), jouent un rôle crucial dans le traitement des requêtes et des réponses HTTP. Ces serveurs web peuvent être configurés pour fonctionner avec des langages et des cadres côté serveur afin de rationaliser le traitement des demandes des clients.
Un autre élément clé de l'architecture du serveur est l'utilisation d'équilibreurs de charge et de mécanismes de mise en cache pour optimiser les performances et garantir que l'application reste réactive en cas de forte charge de trafic. Les équilibreurs de charge répartissent le trafic entrant entre plusieurs serveurs, évitant ainsi qu'un seul serveur ne soit submergé et garantissant une haute disponibilité. Parmi les exemples d'équilibreurs de charge figurent HAProxy, Amazon Elastic Load Balancing (ELB) et Google Cloud Load Balancing.
Les mécanismes de mise en cache stockent temporairement les données fréquemment consultées, réduisant ainsi le temps nécessaire pour récupérer les données et la charge sur le serveur. Les différentes stratégies de mise en cache comprennent la mise en cache en mémoire, les réseaux de diffusion de contenu (CDN) et la mise en cache par proxy inverse. Les outils de mise en cache les plus répandus sont Memcached, Rediset Varnish.
Le serveur est l'épine dorsale de l'architecture web dorsale, fournissant l'infrastructure nécessaire au traitement des demandes des clients, à l'exécution de la logique d'application et à la gestion du stockage des données. En incorporant des langages côté serveur efficaces, des bases de données, des mesures de sécurité et des techniques d'optimisation des performances, les développeurs peuvent créer des applications web robustes et évolutives qui répondent aux exigences du paysage numérique d'aujourd'hui.
Exploration des caractéristiques essentielles d'une application
Interface conviviale
Une interface conviviale est essentielle au succès de toute application. Elle implique la création d'une présentation visuellement attrayante, intuitive et facile à naviguer, qui améliore l'expérience de l'utilisateur (UX). L'interface doit être conçue en fonction du public cible, afin que les utilisateurs puissent comprendre et accéder rapidement aux caractéristiques et fonctionnalités de l'application. L'utilisation de principes de conception établis, tels que la cohérence, le retour d'information et l'accessibilité, contribuera à une expérience utilisateur transparente et agréable.
Avec la prolifération des appareils et des plateformes, les applications doivent être réactives et compatibles avec différentes tailles d'écran, systèmes d'exploitation et navigateurs. Une conception réactive garantit que la présentation et les éléments de l'application s'adaptent à la taille de l'écran de l'appareil, offrant ainsi une expérience utilisateur cohérente. La compatibilité multiplateforme garantit que l'application fonctionne de manière optimale sur différentes plateformes, telles que Windows, macOS, iOS et Android.
La performance est un aspect essentiel de toute application, car elle a un impact direct sur la satisfaction et la fidélisation des utilisateurs. Une application doit être conçue pour se charger rapidement, répondre rapidement aux interactions de l'utilisateur et minimiser les temps de latence. L'utilisation de techniques d'optimisation, telles que la mise en cache, la minification du code et la compression d'images, peut améliorer considérablement les performances.
L'évolutivité fait référence à la capacité d'une application à gérer un nombre croissant d'utilisateurs et de demandes sans compromettre les performances. La conception d'une application évolutive implique
-
le choix d'une architecture dorsale adaptée
-
Mettre en œuvre l'équilibrage de la charge
-
l'utilisation de solutions basées sur l'informatique en nuage pour allouer les ressources de manière dynamique en fonction de la demande.
Sécurité et confidentialité
La sécurité est une priorité absolue pour toute application, en particulier celles qui traitent des données sensibles ou des transactions financières. La mise en œuvre de mesures de sécurité solides, telles que le cryptage, l' authentification sécurisée et l'autorisation, peut contribuer à protéger les données des utilisateurs et à minimiser le risque d'atteinte à la protection des données. Il est également essentiel de mettre régulièrement à jour et de corriger les dépendances logicielles pour atténuer les vulnérabilités en matière de sécurité.
La protection de la vie privée est un autre aspect essentiel du développement d'applications, et les développeurs doivent s'assurer que les données des utilisateurs sont collectées, stockées et traitées conformément aux réglementations pertinentes en matière de protection des données, telles que le Règlement général sur la protection des données (RGPD) ou la loi californienne sur la protection de la vie privée des consommateurs (CCPA).
Accessibilité
L'accessibilité fait référence à la conception d'une application qui peut être facilement utilisée par des personnes souffrant de handicaps, tels que des déficiences visuelles, auditives, cognitives ou motrices. En adhérant aux normes d'accessibilité, telles que les Web Content Accessibility Guidelines (WCAG), les développeurs peuvent créer des applications inclusives qui s'adressent à une base d'utilisateurs plus large. L'intégration de fonctionnalités telles que la navigation au clavier, la compatibilité avec les lecteurs d'écran et l'ajustement de la taille des textes peut améliorer considérablement l'accessibilité d'une application.
Gestion et signalement efficaces des erreurs
Les erreurs sont inévitables dans toute application, mais la manière dont elles sont gérées et signalées peut avoir un impact significatif sur l'expérience de l'utilisateur. La mise en œuvre de mécanismes efficaces de gestion des erreurs peut empêcher l'application de tomber en panne et aider les utilisateurs à se remettre des erreurs avec élégance. Des messages d'erreur clairs et informatifs, ainsi que des conseils pour résoudre le problème, peuvent améliorer la satisfaction de l'utilisateur et minimiser sa frustration.
Pour développer une application réussie, il faut mettre l'accent sur l'expérience utilisateur, les performances, la sécurité et l'accessibilité. En prenant soigneusement en compte ces caractéristiques essentielles au cours du processus de conception et de développement, les développeurs peuvent créer des applications qui répondent aux besoins et aux attentes de leurs utilisateurs, garantissant ainsi un succès à long terme.
Quels types de réponses un serveur peut-il envoyer ?
Un serveur peut envoyer différents types de réponses aux requêtes des clients, principalement déterminées par les codes d'état HTTP et les données associées. Ces réponses peuvent être classées dans les grandes catégories suivantes :
Réponses positives (codes d'état 2xx): Ces réponses indiquent que le serveur a traité avec succès la demande du client. Les codes d'état les plus courants sont les suivants
-
200 OK : La demande a été traitée avec succès et le serveur a renvoyé les données demandées.
-
201 Created (Créé) : La demande a été traitée avec succès et le serveur a créé une nouvelle ressource.
-
204 No Content (Pas de contenu) : La demande a abouti, mais il n'y a pas de données à renvoyer (souvent utilisé pour les demandes DELETE).
Réponses de redirection (codes d'état 3xx): Ces réponses informent le client qu'une action supplémentaire est nécessaire pour compléter la demande, ce qui implique généralement une modification de l'URL demandée. Les codes d'état de redirection les plus courants sont les suivants
-
301 Moved Permanently (Déplacement permanent) : La ressource demandée a été déplacée de manière permanente vers une nouvelle URL, et le client doit utiliser cette URL pour ses futures demandes.
-
302 Found (Redirection temporaire) : La ressource demandée est temporairement disponible à une autre URL, mais le client doit continuer à utiliser l'URL d'origine pour ses futures demandes.
-
304 Non modifié : La ressource demandée n'a pas été modifiée depuis la dernière demande, et le client peut utiliser sa version en cache.
Réponses d'erreur du client (codes d'état 4xx): Ces réponses indiquent qu'il y a eu un problème avec la demande du client, par exemple une syntaxe incorrecte ou une ressource non valide. Les codes d'état d'erreur client les plus courants sont les suivants
-
400 Bad Request (mauvaise requête) : Le serveur n'a pas pu comprendre la demande en raison d'une syntaxe mal formée ou d'une entrée non valide.
-
401 Non autorisé : La demande nécessite une authentification et le client n'a pas fourni d'informations d'identification valides.
-
403 Interdit : Le client n'a pas la permission d'accéder à la ressource demandée.
-
404 Non trouvé : La ressource demandée n'a pas été trouvée sur le serveur.
-
429 Too Many Requests (Trop de demandes) : Le client a envoyé trop de demandes dans un laps de temps donné, et le serveur limite le nombre de demandes.
Réponses d'erreur du serveur (codes d'état 5xx): Ces réponses indiquent que le serveur a rencontré une erreur lors du traitement de la demande. Les codes d'état d'erreur de serveur les plus courants sont les suivants
-
500 Internal Server Error (erreur interne du serveur) : Message d'erreur générique indiquant que le serveur a rencontré une situation inattendue qui l'a empêché de répondre à la demande.
-
502 Mauvaise passerelle : Le serveur, qui agit en tant que passerelle ou proxy, a reçu une réponse non valide d'un serveur en amont.
-
503 Service Unavailable (Service indisponible) : Le serveur est temporairement incapable de traiter la demande en raison d'une maintenance, d'une charge élevée ou d'autres problèmes.
-
504 Gateway Timeout (Délai d'attente de la passerelle) : Le serveur, qui agit en tant que passerelle ou proxy, n'a pas reçu de réponse en temps voulu de la part d'un serveur en amont.
Outre les codes d'état, les serveurs peuvent également envoyer des données dans différents formats, tels que HTML, XML, JSON ou du texte brut. La réponse peut inclure des en-têtes qui fournissent des informations supplémentaires sur la réponse, telles que le type de contenu, la longueur du contenu et les politiques de mise en cache.
Qu'est-ce qu'une base de données et pourquoi devons-nous l'utiliser ?
Une base de données est une collection organisée de données structurées qui permet de stocker, d'extraire, de modifier et de gérer efficacement des informations. Les bases de données sont un composant essentiel des applications logicielles, en particulier des applications web, car elles fournissent un moyen systématique et fiable de stocker et de manipuler les données générées par les utilisateurs ou nécessaires à la fonctionnalité de l'application.

Il y a plusieurs raisons pour lesquelles les bases de données sont cruciales dans le développement de logiciels :
-
Persistance des données: Les bases de données permettent un stockage persistant des données, ce qui garantit que les informations ne sont pas perdues lorsqu'une application est fermée ou que le serveur est redémarré. Cela est particulièrement important pour les applications qui gèrent des comptes d'utilisateurs, des transactions ou toute autre donnée qui doit être conservée au fil du temps.
-
Gestion efficace des données: Les bases de données sont conçues pour gérer de grands volumes de données et fournir des mécanismes efficaces d'insertion, de mise à jour, de suppression et de récupération des informations. Les systèmes de gestion de bases de données (SGBD) offrent diverses possibilités d'interrogation et d'indexation qui permettent aux développeurs d'accéder aux données et de les manipuler rapidement et facilement.
-
Intégrité et cohérence des données: Les bases de données aident à maintenir l'intégrité et la cohérence des données en appliquant des contraintes, des relations et des règles de validation. Par exemple, une base de données relationnelle peut définir des contraintes de clé étrangère pour garantir le maintien des relations entre les tables ou des contraintes d'unicité pour éviter les entrées en double.
-
Contrôle de la simultanéité: Les bases de données permettent à plusieurs utilisateurs ou applications d'accéder aux données et de les modifier simultanément, tout en garantissant la cohérence des données et en évitant les conflits. Les systèmes de gestion de bases de données utilisent divers mécanismes de contrôle de la concurrence, tels que le verrouillage ou le contrôle optimiste de la concurrence, pour gérer les accès simultanés et maintenir l'intégrité des données.
-
Sécurité des données: Les bases de données intègrent des fonctions de sécurité qui permettent de protéger les données sensibles contre les accès ou les modifications non autorisés. Ces fonctions comprennent l'authentification des utilisateurs, le contrôle d'accès basé sur les rôles et le cryptage des données, qui peuvent être configurés pour restreindre l'accès et protéger les données.
-
Évolutivité: Les bases de données sont conçues pour évoluer verticalement (en ajoutant des ressources à un seul serveur) et horizontalement (en répartissant les données sur plusieurs serveurs) afin de s'adapter à l'augmentation des volumes de données et du nombre d'utilisateurs. Cela permet aux applications de maintenir leurs performances et leur disponibilité à mesure que leur base d'utilisateurs et leurs besoins en matière de stockage de données augmentent.
Il existe différents types de bases de données, telles que les bases de données relationnelles (par exemple, MySQL, PostgreSQL, Microsoft SQL Server) et les bases de données non relationnelles (NoSQL) (par exemple, MongoDB, Cassandra, Couchbase). Le choix d'une base de données dépend de facteurs tels que la structure des données de l'application, les exigences en matière de requêtes et les besoins d'évolutivité. En exploitant les bases de données, les développeurs peuvent créer des applications logicielles efficaces et fiables qui gèrent et manipulent efficacement les données.
Qu'est-ce qu'une API web ?
Une API web (interface de programmation d'applications) est un ensemble de règles et de protocoles qui permet à différentes applications logicielles de communiquer entre elles sur l'internet. Les API web servent d'interface entre les applications clientes (par exemple, les navigateurs web, les applications mobiles) et les ressources ou services côté serveur, permettant aux développeurs d'accéder et d'échanger des données ou des fonctionnalités d'une manière standardisée.
Les API Web utilisent généralement le protocole HTTP (Hypertext Transfer Protocol) comme principal protocole de communication et traitent les demandes des clients par le biais de diverses méthodes HTTP, telles que GET, POST, PUT, DELETE et PATCH. Ces méthodes correspondent à des opérations standard, telles que la lecture, la création, la mise à jour et la suppression de données.
Les données échangées par l'intermédiaire des API Web sont généralement formatées en JSON (JavaScript Object Notation) ou en XML (eXtensible Markup Language), car elles sont à la fois légères, lisibles par l'homme et facilement analysées par la plupart des langages de programmation.
Il existe plusieurs styles architecturaux et principes de conception utilisés pour créer des API Web, dont certains sont les suivants :
-
REST (Representational State Transfer) : REST est un style architectural qui met l'accent sur une approche sans état, orientée ressources et évolutive de la conception des API. Les API RESTful utilisent des méthodes et des codes d'état HTTP standard, adhèrent à une structure URL cohérente et exploitent des mécanismes de mise en cache pour améliorer les performances. Les API RESTful utilisent souvent JSON comme principal format d'échange de données.
-
GraphQL : GraphQL est un langage de requête et un moteur d'exécution pour les API développés par Facebook. Il permet aux clients de demander uniquement les données dont ils ont besoin et au serveur de consolider plusieurs requêtes en une seule réponse. Les API GraphQL constituent un moyen souple et efficace de récupérer et de mettre à jour des données, en particulier pour les applications ayant des structures de données complexes ou des besoins évolutifs.
-
SOAP (Simple Object Access Protocol) : SOAP est un protocole basé sur XML pour l'échange d'informations structurées dans la mise en œuvre de services web. SOAP s'appuie sur des contrats prédéfinis (documents WSDL) qui décrivent les opérations de l'API, les types de données et les modèles de communication. Bien que SOAP soit plus rigide et verbeux que REST ou GraphQL, il offre une gestion intégrée des erreurs, des fonctions de sécurité et la prise en charge de types de données complexes.
-
gRPC: gRPC est un cadre RPC (Remote Procedure Call) haute performance et open-source développé par Google. Il utilise des tampons de protocole comme langage de définition d'interface et format de sérialisation des données, ce qui permet une communication efficace et fortement typée entre les clients et les serveurs. gRPC prend en charge le flux bidirectionnel et peut tirer parti des fonctionnalités HTTP/2 pour améliorer les performances, ce qui en fait un choix approprié pour les API à faible latence et à haut débit.
Les API web jouent un rôle essentiel dans le développement des logiciels modernes, en permettant l'intégration de divers services, sources de données et plateformes pour créer des applications riches en fonctionnalités et évolutives. En mettant en œuvre une API web bien conçue, les développeurs peuvent exposer les fonctionnalités de leur application à d'autres applications, ce qui favorise la collaboration, l'interopérabilité et la croissance de l'écosystème logiciel au sens large.
Description d'une requête
L'élaboration d'une requête type dans une application web implique de comprendre les différentes étapes et les différents composants impliqués dans le traitement de la requête d'un client et dans le renvoi d'une réponse appropriée. Voici une vue d'ensemble du processus :
Action de l'utilisateur
L'utilisateur interagit avec l'application cliente, par exemple en cliquant sur un bouton ou en soumettant un formulaire, ce qui déclenche une requête au serveur. Cette demande peut être initiée à l'aide de JavaScript (par exemple, AJAX, Fetch API) dans un navigateur web ou par l'intermédiaire d'un client HTTP dans une application mobile.
Demande HTTP
L'application cliente envoie une requête HTTP au serveur avec les informations requises, y compris la méthode de requête (GET, POST, PUT, DELETE, etc.), l'URL cible ou le point de terminaison de l' API, les en-têtes (par exemple, le type de contenu, les jetons d'authentification), et toutes les données (payload) si nécessaire.
Résolution DNS
Le client résout le nom de domaine du serveur en adresse IP à l'aide du système de noms de domaine (DNS). Cette étape consiste à interroger un ou plusieurs serveurs DNS pour obtenir l'adresse IP associée au domaine demandé.
Traitement du serveur
La demande parvient au serveur web, qui la transmet à l'application ou au service d'arrière-plan approprié. Selon l'architecture de l'application, il peut s'agir d'acheminer la demande par l'intermédiaire d'un proxy inverse ou d'un équilibreur de charge.
Traitement de l'application
L'application dorsale traite la demande, ce qui peut impliquer plusieurs étapes telles que
-
Vérifications de l'authentification et de l'autorisation pour s'assurer que le client a les permissions nécessaires pour accéder aux ressources demandées ou effectuer les actions souhaitées.
-
L'analyse et la validation de toutes les données entrantes.
-
Exécution de la logique commerciale pertinente, telle que la création, la mise à jour ou l'extraction de données d'une base de données ou l'appel à d'autres services ou API.
-
Générer une réponse appropriée, généralement sous forme de JSON, XML ou HTML.
Réponse HTTP
Le serveur renvoie la réponse HTTP au client, y compris un code d'état (par exemple, 200 OK, 404 Non trouvé) et tout en-tête supplémentaire (par exemple, type de contenu, politiques de mise en cache). Le corps de la réponse peut contenir les données demandées ou un message d'erreur, en fonction du résultat de la requête.
Rendu côté client
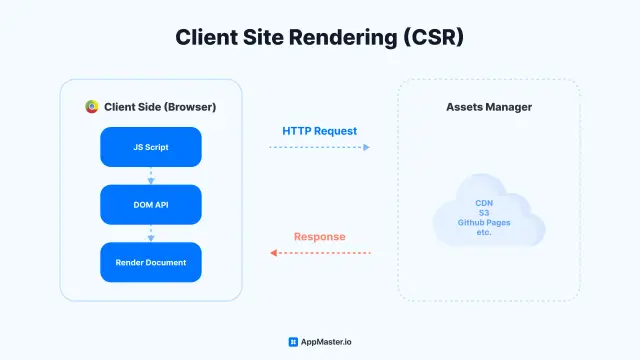
L'application cliente reçoit la réponse et met à jour l'interface utilisateur en conséquence. Pour les applications web, il peut s'agir d'un rendu HTML, d'une mise à jour des éléments DOM ou de l'affichage de données dans un tableau ou un graphique. Les applications mobiles peuvent utiliser des composants d'interface utilisateur natifs pour afficher les données.
Rétroaction de l'utilisateur
Enfin, l'utilisateur reçoit le résultat de sa demande, qui peut être un message de confirmation, une vue actualisée ou un message d'erreur, en fonction du résultat.
Cette vue d'ensemble simplifie les nombreuses complexités et variations qui peuvent survenir au cours du cycle de vie d'une demande. Elle permet toutefois de comprendre les étapes et les composants impliqués dans le traitement d'une demande dans une application web typique.
L'architecture du back-end dans AppMaster
Le Back-end Builder d'AppMaster est un outil puissant qui permet aux utilisateurs de créer des applications mobiles et web robustes et polyvalentes en utilisant une architecture back-end. no-code, drag-and-drop et web en utilisant une approche de type "back-end". L'architecture back-end dans AppMaster est structurée pour fournir une connexion transparente entre le front-end (interface utilisateur) et le back-end (logique côté serveur et stockage de données), permettant aux développeurs de créer des applications web et mobiles qui sont interconnectées à travers un back-end commun.
L'architecture du back-end est conçue dans un souci de flexibilité, permettant aux utilisateurs d'héberger leurs applications sur des serveurs locaux, dans le nuage d'AppMaster ou chez des fournisseurs de nuages tiers tels que AWS, Azure et Google Cloud. Le backend de l'application est construit sur la base de quatre composants principaux : la conception de la base de données, la logique métier, la configuration des points d'extrémité et du middleware, et l'intégration des modules.
La conception de la base de données implique la création de modèles de données et la définition de leurs relations, tandis que la logique métier concerne la mise en place de processus pour automatiser les tâches au sein de l'application. La configuration des points d'extrémité et des intergiciels sert de pont entre les processus du serveur et le frontend, assurant un transfert de données et une interaction sans heurts. Les modules permettent aux développeurs d'ajouter des fonctionnalités supplémentaires à leurs applications, certaines étant automatiquement intégrées, comme le module Auth pour l'autorisation des utilisateurs.

Le développement du frontend, qui se concentre sur l'interface utilisateur, s'effectue via le concepteur de Web Apps ou de Mobile Apps, en fonction du type d'application souhaité. L'éditeur visuel de modèles de données d'AppMaster simplifie la conception et la gestion des bases de données, permettant aux utilisateurs de créer une application bien structurée et efficace.
En exploitant l'API d'AppMaster, les développeurs peuvent facilement intégrer leurs applications à d'autres services et ressources, tandis que la documentation automatique de l'API garantit un processus de développement rationalisé. Une fois terminées, les applications peuvent être publiées sur différentes plateformes, y compris AppMaster Cloud, des services cloud tiers et des serveurs personnels. Le Back-end Builder d'AppMaster offre une approche complète et intuitive du développement d'applications, permettant aux utilisateurs de créer des logiciels de qualité professionnelle sans avoir besoin de connaissances approfondies en matière de codage.
En conclusion
L'architecture web back-end est le héros méconnu du développement web moderne. Elle fournit l'infrastructure essentielle, la logique et la gestion des données qui alimentent les sites web et les applications sophistiqués d'aujourd'hui. Comprendre les subtilités des composants back-end, tels que les langages côté serveur, les bases de données, les serveurs et les mécanismes de mise en cache, est essentiel pour développer des plates-formes en ligne sûres et évolutives.
La technologie ne cessant de progresser, les développeurs web doivent se tenir au courant des dernières tendances et des meilleures pratiques afin de pouvoir créer des applications innovantes et performantes qui répondent aux besoins en constante évolution des utilisateurs. En explorant les caractéristiques essentielles de l'architecture back-end, les développeurs peuvent exploiter le potentiel d'outils puissants tels que le Back-end Builder d'AppMaster pour créer des solutions centrées sur l'utilisateur qui conduisent au succès dans le monde numérique.






