

设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
No-сode ETL工具帮助企业进行数据分析和战略决策,不需要繁琐的代码和开发工作。

有了关于你的客户的大量数据,唯一阻碍你利用它来获得组织利益的是CODE。如果这决定了你和你的业务,你会想学习关于ETLno-code 工具的一切。通过这种学习,专家数据工程师利用的提取、转换和加载机制对你来说将不再陌生。你将获得关于你的利益相关者的有价值的信息,类似于数据专家和数据工程师在使用数据科学和数据整合进行多年编码后所收集的信息。这听起来不是一个双赢的交易吗?让我们更深入地探讨一下 no-code ETL 工具的细节。
ETL提取、转换和加载是数据仓库的一个重要过程。在这个过程中,来自多个信息源的数据通过数据整合转换为一个,为决策者提供可依赖的有说服力的信息。
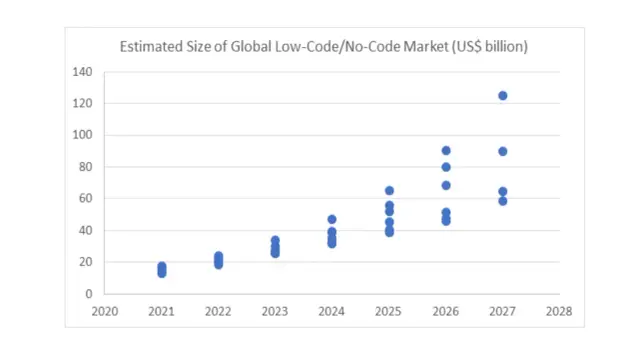
low-code 和 no-code 开发 行业预计 到2030年 将达到 1870亿美元 的创收能力。收入逐年增加的原因是企业越来越多地采用no-codeETL 技术。预计 超过75% 的企业将采用这些工具,并为数据整合行业的增长做出贡献。
no-code 行业的增长并不是专门针对IT行业的,相反,这个行业的一半增长预计来自IT行业以外的公司。
下面是关于这个过程中每个步骤的介绍。
提取数据-- 在这一步中,你的公司使用的不同数据流被访问,所有的数据被存储在一个单一的存储库中,然后使其可以在各种软件和系统之间移动,以便使用 数据科学 进一步处理。
转化- 这一步需要对数据和数据仓库进行清理,并使其有效地进一步使用。转换过程中的一些主要规则包括重复数据删除、验证、分类、标准化和数据整合。
加载- 加载涉及在较新的位置显示数据,可以随时用于接下来的流程,如报告和决策。可以有两种主要的加载机制:完全加载和增量加载。无论使用何种加载机制,其结果都是更容易进行数据分析。
No-codeETL 是指在没有任何代码的情况下进行整个提取、转换和加载过程。它构成了数据集成的后端。No-code ETL 工具被设计为最大限度地自动化,用户不需要输入任何代码行就可以有效地工作。企业可以使用这种工具,而不需要专门聘请ETL 开发人员或数据专家。
no-code ETL 工具在云中运行,通常有一个 drag-and-drop 接口,以方便非技术用户找出正确的使用方法。通过这些no-code ETL ,你的组织可以轻松地创建自己的数据集市或数据仓库,最终影响战略的形成和决策。
有四种主要类型的no-code ETL工具。我们将在本节中简要地分享每一种类型。
这些是由商业组织开发和支持的工具。作为开发no-code ETL 流程的先驱,这些公司已经推进了学习封面,并在这些工具中为用户提供了图形化的用户界面、易于使用的功能,以及其他允许更多访问和更简单使用的功能。
然而,作为对所有这些功能的回报,收取的价格往往比市场上其他no-code ETL 的解决方案要高。大型组织通常倾向于使用这类工具进行数据整合,因为有稳定的数据流入,并要求在数据管道内的数据分析中获得大量的信息。
像任何其他开源软件一样,开源ETL 工具可以免费使用。他们可以向用户提供基本功能,同时允许你的组织寻找和研究源代码。但这些工具所提供的功能和使用的方便性有很大的不同。
因此,选择手动ETL ,如果你不想只依赖基本功能,可能需要你保留一个内部开发人员来专门为你的组织调整基本代码。然而,开放源码ETL ,比其他任何 ETL 工具类型允许更高的可定制性。
随着 基于云的技术 的突出,ETL 工具也可以采用这种工作形式。通过使用云技术,你可以期待高延迟、资源的可用性和弹性。 它让计算资源扩展并满足组织需求。但云数据平台的一个问题是,它们只在云服务器的环境中工作。
最后一种类型的ETL 工具包括定制版本。它们是由大公司使用内部软件开发团队设计的。它们可以根据组织的要求进行个性化定制。一些可能有助于创建这种软件的计算机语言包括 SQL,Python, 和Java 。
这些工具的问题往往是成本和对资源的过度要求。创建、测试和维护这些工具都需要时间和不断升级的过程。因此,你必须准备好为定制的ETL 工具留出特定的预算。
在过去的几年里,使用ETL 工具的趋势很明显。最初,ETL 流程只是通过手动方式处理,数据科学家被雇用来完成整个数据整合过程。
但随着强大的软件和开发公司推出 no-code 工具,ETL 工具已经变得非常重要。预计no-code 的市场将 以 每年 40% 的速度增长,到2022年底达到 212亿美元。因此,这些no-code ETL 工具有很大的市场份额。
手工ETL ,需要数据分析师的数据科学和架构来执行这个过程。没有自动化,每个步骤都必须涉及编码和专家监督。此外,你必须期待流程中的每个步骤都有很长的工作时间。这种额外的时间不仅需要一次性的努力,而且每次都需要对所有的数据源进行处理,从而提高所涉及的整体工作。此外,数据工程师更多的工作时间意味着你的终端成本更高。
开发人员在手动提取、转换和加载数据的过程中创建管道。数据范围和数据仓库越多,需要的时间和人力资源就越多。同样地,数据整合过程需要更多的编码来使其启动和运行。
大体上,以下是手工整合数据需要执行的主要过程。
进行手工ETL 流程和使用no-code ETL 工具是非常不同的。毫无疑问,后者是一个具有挑战性和复杂的过程。本节强调了手工数据编码过程与工具使用不同的其他领域。
no-code ETL 工具所能提供的使用便利性是超出想象的。他们已经有了提取非结构化数据、执行转换过程、并将其加载到干净的存储库的固定流程。因此,除了提供数据管道的位置,你不需要做太多的事情。
然而,即使是高级数据专家,手动完成这个过程也不容易,因为它需要一个漫长的过程来掌握数据中的宝贵信息。此外,编码有可能出错,会毁掉整个数据整合过程。
手动ETL 代码的维护是具有挑战性的。你必须掌握多种计算机语言才能很好地掌握整个过程。你可能不得不聘请所有这些语言的专家,或者聘请能够利用有限的变化完成工作的资源。
此外,将有多种数据整合的场景,你可能需要执行这个过程。所以,对于每一种新的信息类型的要求,都必须重新进行处理。然而,当选择no-code ETL 解决方案时,这将不会成为你的组织担心的原因。这些工具不需要你或你的团队成为计算机科学方面的专家来维护;任何人都可以做到。
从成本的角度来看,no-code ETL 解决方案将被证明是一个更好的选择,因为使用这些工具涉及到预定的订阅费用,考虑到你得到的回报价值,这并不昂贵。 但雇用一个数据科学家需要大量的投资。由于开发人员的年薪超过 10 万美元,你还需要投资于其他人,他们可能不是专家,但必须知道ETL 流程,以方便数据科学家。同样,专门的硬件也将是必不可少的,这将进一步增加你的成本。
就性能而言,手动ETL 编码肯定会占上风。这是因为你可以根据你的组织需求得到一个定制的过程。你可以减少或增加数据源,在转换过程中设置你自己的规则。所有这些活动都不可能用no-code ETL 工具。这些no-code ETL 解决方案已经基于一个预定义的代码,它按照定义运行过程。因此,结果的整体性能可能略有不同。
ETL 工具倾向于根据组织数据源和要求的变化进行扩展。所以,如果你将来做大了,也不会有什么。然而,使用数据整合的手动过程将需要你创建更多的代码行来获得结果。
ETL 工具也允许 工作流程自动化,因为数据将被提取、转换,并根据你安排的时间和方式加载到所需的存储库。所有这些信息通常都是从数据仓库中获取的。你将不必通过编码来执行数据管道的每一步。在手动 流程的情况下,所有的数据库和存储库将不得不用大量的代码手动连接来进行整个流程。ETL
no-code ETL 工具在你有广泛的数据库和需要过多的编码工作的情况下是完美的。然而,如果你的数据库没有什么发展,或者你所需要的信息并不紧急,你可能会选择手动ETL 。然而,即使在这种情况下,你也必须愿意写大量的代码行。
手动ETL 和no-code ETL 的另一个区别是数据源的数量。然而,你可以对任何数量的数据源使用这些方法。但是,数据源的数量越少,在手动ETL 的情况下,过程的复杂性就会越低。no-code ETL 工具让你连接任何数量的数据库,而不需要任何额外的编码。
要升级或改变当前的数据图或进行ETL 的途径,no-code 工具可以提供很大帮助。你必须重新做整个编码过程,以获得较新的编码,并采用手工编码的方式。如果你会选择开源的ETL 工具,根据你的需要进行调整或定制将变得更加复杂。
No-code ETL 解决方案可以对你的业务有帮助,因为它们可以在没有编码的情况下工作。通过一个典型的no-code ETL ,你可以使用一个简单的用户界面工具来创建一个数据地图,将路径呈现给服务器。然后,服务器可以在自动化上运行整个过程,而不需要你的进一步协助。
添加转换规则也是ETL 可以帮助你的方式之一。清理、重构、分离或删除数据集是可能的,以确保提供最新和相关的信息。通过将一些简单的规则应用于该过程,检查提取的数据质量也是可能的。
你可以安排整个ETL ,所以不需要手动运行,就可以实现更新的数据集和信息,用于战略决策。此外,可视化、直观和用户友好的界面确保每个人都可以利用这些ETL ,以节省时间,提高生产力和获得更好的结果。
在使用no-code ETL 流程时,你会遇到许多情况,在这些情况下,ETL 工具是有帮助的。这些包括。
连接器
如果你有不同的数据管道,你可以很容易地连接它们,而不需要添加任何一行代码。例如,如果你的客户数据存储在Oracle中,而订单信息在Microsoft Excel中,该工具将连接到这些数据仓库。
数据剖析
你必须对数据进行定义,以获得最大的收益。ETL 流程可以让你输入数据变量,如类型、完整性和质量。基于定义的值,数据将被自动排序。
预建的转换
在ETL 软件中可以有内置的转换,可以直接应用于原始数据,使你的事情变得更加容易。
方便的调度
你可以用特定的触发器来安排ETL 管道,这样事情就会保持自动化,你就不必在某个特定的时间投入明显的努力。
最好的no-code ETL 工具之一是AppMaster 。它可以自动完成提取、转换、加载和数据验证的整个过程。
用AppMaster创建数据管道
开源的ETL 工具可能不是在所有情况下都有帮助。你需要专门的软件来创建提取数据的管道,并将人工ETL ,转变为自动化的数据架构。你肯定可以用开源ETL 工具开始你的组织数据提取和数据整合之旅。但是,你仍然需要专门的软件,包含所有需要的功能,以创建一个无缝的数据管道,这最终有助于数据准备和数据分析。AppMaster ,这个软件可以完全满足你的需求。
实施数据仓库的最佳实践
通过AppMaster ,你可以期望使用 PostgreSQL 数据库 来整合数据,加载数据,并将其转换为可以帮助你的组织做出重要决策的格式。所有这些方面都可以通过手动ETL 机制来覆盖;然而,有了AppMaster在你身边,你可以在不需要编码的情况下管理数据集成。
整合数据源
你只需要在手动ETL ,整合你的组织所使用的不同数据结构,并让该工具执行其操作。数据整合的结果将是你进行重要决策所需的信息。与手动ETL 工具相比,数据整合过程可以在相对较少的时间内进行管理。你不需要在数据质量或其他因素上做出妥协。
提供易于使用的界面
AppMaster 是专门设计来提供一个易于使用的界面,同时帮助你提取数据。通过为不同的利益相关者提供不同的仪表盘设施,调整你所需要的信息变得更容易获得。 在正确的时间获得正确的信息有助于更好的决策。此外,这样的界面可以节省时间,并在一个屏幕上提供所有基本数据。
No-code ETL 工具可以为管理数据提供一个简单的解决方案,可以为你的业务带来更多的增长机会。你不需要 开发人员来执行 ,这使得事情变得更加容易,用户友好,并具有成本效益。ETLETL
由于与no-code ETL 工具相关的多种好处,这些工具是商业世界的新现实,特别是对于拥有大量数据的公司。从多个可用的开源ETL 工具中,你必须依赖提供先进功能且易于使用的平台,如AppMaster 。




