
Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Narzędzia No-сode ETL pomagają firmom w analizie danych i podejmowaniu strategicznych decyzji, nie wymagając żmudnego kodu i wysiłków programistycznych.

Z tonami danych dostępnych o twoich klientach, jedyną rzeczą, która przeszkadza ci w wykorzystaniu ich dla korzyści organizacyjnych, jest KOD. Jeśli to określa Ciebie i Twój biznes, będziesz chciał nauczyć się wszystkiego o narzędziach ETLno-code. Dzięki tej nauce mechanizm Extract, Transform, and Load, który wykorzystują eksperci inżynierowie danych, nie będzie Ci obcy. Uzyskasz cenne informacje o swoich interesariuszach, podobne do tych, które specjaliści od danych i inżynierowie danych zgromadziliby po latach kodowania z wykorzystaniem data science i integracji danych. Czy nie brzmi to jak umowa typu win-win? Zanurzmy się głębiej i poznajmy no-code ETL Narzędzia w szczegółach.
ETL(ang. Extract, Transform, and Load) jest podstawowym procesem w hurtowni danych. Podczas tego procesu dane z wielu źródeł informacji są przekształcane w jeden poprzez integrację danych, aby zapewnić decydentom istotne informacje, na których mogą polegać.
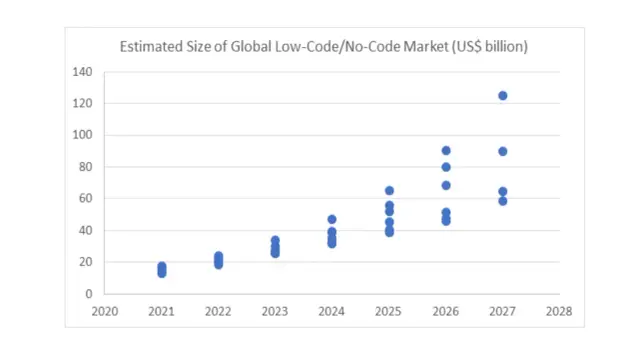
Oczekuje się, że do 2030 roku branża low-code i no-code rozwoju osiągnie zdolność generowania przychodów na poziomie 187 miliardów dolarów. Wzrost przychodów w skali roku wynika ze zwiększonej adopcji przedsiębiorstw z technologią no-codeETL. Oczekuje się, że ponad 75% firm przyjmie te narzędzia i przyczyni się do wzrostu branży integracji danych.
Wzrost w sektorze no-code nie jest specyficzny dla branży IT; zamiast tego oczekuje się, że połowa wzrostu tego sektora będzie pochodzić z firm innych niż sektor IT.
Oto wprowadzenie na temat każdego kroku w procesie:
Wydobywa dane- w tym kroku uzyskuje się dostęp do różnych przepływów danych używanych przez Twoją firmę, a wszystkie dane są przechowywane w jednym repozytorium po tym, jak sprawią, że będą realne do przeniesienia między różnymi programami i systemami do dalszego przetwarzania przy użyciu nauki o danych.
Transformacja - ten krok wymaga, aby dane i hurtownia danych były oczyszczone i sprawne do dalszego wykorzystania. Niektóre główne zasady w procesie transformacji obejmują deduplikację, weryfikację, sortowanie, standaryzację i integrację danych.
Ładowanie - Ładowanie polega na wyświetlaniu danych w nowej lokalizacji, które mogą być łatwo wykorzystane do kolejnych procesów, takich jak raportowanie i podejmowanie decyzji. Mogą istnieć dwa główne mechanizmy ładowania: pełne ładowanie i ładowanie przyrostowe. Bez względu na zastosowany mechanizm ładowania, rezultatem jest łatwiejsza analityka danych.
No-codeETL oznacza przeprowadzenie całego procesu ekstrakcji, transformacji i ładowania bez użycia kodu. Stanowi on backend integracji danych. Narzędzia No-code ETL są zaprojektowane tak, aby maksymalnie zautomatyzować ten proces, a użytkownicy nie muszą wprowadzać żadnych linijek kodu, aby uzyskać jego sprawne działanie. Firmy mogą korzystać z takich narzędzi bez zatrudniania ETL programistów lub ekspertów od danych.
Narzędzia no-code ETL działają w chmurze i często mają drag-and-drop interfejs, aby ułatwić użytkownikom nietechnicznym zrozumienie właściwego sposobu korzystania z nich. Dzięki tym narzędziom no-code ETL Twoja organizacja może łatwo stworzyć własny data mart lub hurtownię danych, która ostatecznie wpłynie na tworzenie strategii i podejmowanie decyzji.
Istnieją cztery główne typy narzędzi no-code ETL. W tym rozdziale opowiemy krótko o każdym z tych typów:
Są to narzędzia opracowane i wspierane przez organizacje komercyjne. Będąc pionierami w rozwoju procesów no-code ETL, firmy te zaawansowały już osłonę nauki i zapewniły użytkownikom tych narzędzi graficzny interfejs użytkownika, funkcje łatwego użytkowania i inne cechy w tych narzędziach, które umożliwiają większą dostępność i prostsze użytkowanie.
Jednak cena pobierana w zamian za wszystkie te cechy jest często większa niż w przypadku innych rozwiązań no-code ETL dostępnych na rynku. Duże organizacje zazwyczaj preferują takie narzędzia do integracji danych ze stałym strumieniem napływu danych i wymaganiem wielu informacji z analizy danych w ramach rurociągów danych.
Podobnie jak każde inne oprogramowanie open source, narzędzia open source ETL są darmowe w użyciu. Mogą one zapewnić podstawową funkcjonalność użytkownikom, jednocześnie umożliwiając Twojej organizacji znalezienie i zbadanie kodu źródłowego. Ale funkcje i łatwość użycia oferowane przez te narzędzia różnią się znacznie.
Tak więc wybór ręcznego ETL może wymagać od Ciebie utrzymywania wewnętrznego programisty, który będzie poprawiał podstawowy kod specjalnie dla Twojej organizacji, jeśli nie chcesz polegać tylko na podstawowych funkcjach. Jednak open source ETL pozwala na większe możliwości dostosowania niż jakikolwiek inny typ narzędzia ETL .
Wraz ze wzrostem znaczenia technologii opartej na ch murze, narzędzia ETL są również dostępne z tą formą pracy. Korzystając z technologii chmury, można oczekiwać wysokich opóźnień, dostępności zasobów i elastyczności. Pozwala to na skalowanie zasobów obliczeniowych i spełnianie wymagań organizacyjnych. Ale jednym z problemów z platformami danych w chmurze jest to, że działają one tylko w środowisku serwera w chmurze.
Ostatnim typem narzędzia ETL jest wersja custom. Są one projektowane przez duże firmy przy użyciu wewnętrznych zespołów rozwoju oprogramowania. Mogą być spersonalizowane do wymagań organizacji. Niektóre języki komputerowe, które mogą pomóc w tworzeniu tego oprogramowania to. SQL, Python, oraz Java.
Problemem z tymi narzędziami jest często koszt i nadmierne zapotrzebowanie na zasoby. Tworzenie, testowanie i utrzymanie tych wszystkich narzędzi wymaga czasu i ciągłej aktualizacji procesu. Tak więc, musisz być gotowy, aby odłożyć określony budżet na niestandardowe narzędzia ETL.
Trend korzystania z narzędzi ETL był znaczący w ciągu ostatnich kilku lat. Początkowo procesy ETL były obsługiwane tylko poprzez podejście ręczne, gdzie naukowcy danych byli zatrudniani do wykonania całego procesu integracji danych.
Ale wraz z wprowadzeniem narzędzino-code przez potężne domy programistyczne i deweloperskie, narzędzia ETL stały się znaczące. Przewiduje się, że rynek no-code będzie rósł o 40% rocznie, osiągając 21,2 mld USD do końca 2022 roku. Tak więc, istnieje znaczący udział w rynku tych no-code ETL narzędzi.
Ręczne procesy ETL wymagają od analityków danych data science i architektury do wykonania procesu. Nie ma automatyzacji, a każdy krok musi wiązać się z kodowaniem i nadzorem eksperckim. Ponadto, musisz spodziewać się długich godzin pracy dla każdego kroku w procesie. Ten dodatkowy czas jest wymagany nie tylko jako jednorazowy wysiłek, ale musi być wykonany za każdym razem dla wszystkich źródeł danych, co zwiększa ogólną pracę zaangażowaną w proces. Poza tym, więcej godzin pracy inżynierów danych oznacza wyższe koszty na twoim końcu.
Programiści tworzą rurociągi w ręcznym procesie wyodrębniania, przekształcania i ładowania danych. Im większy zakres danych i hurtowni danych, tym więcej czasu i zasobów ludzkich jest wymaganych. Podobnie, proces integracji danych wymaga więcej kodowania, aby go uruchomić.
Ogólnie rzecz biorąc, następujące są główne procesy, że ręczna integracja danych będzie wymagać, aby być wykonywane:
Prowadzenie ręcznych procesów ETL i korzystanie z narzędzi no-code ETL bardzo się różnią. Ten drugi jest bez wątpienia procesem wymagającym i złożonym. W tej sekcji zwrócono uwagę na inne dziedziny, w których ręczny proces kodowania danych różni się od wykorzystania narzędzi:
Łatwość użycia, jaką mogą zaoferować narzędzia no-code ETL, jest poza wyobraźnią. Mają one już ustawiony proces wydobywania nieustrukturyzowanych danych, wykonywania procesu transformacji i ładowania ich do czystego repozytorium. Nie trzeba więc robić wiele poza podaniem lokalizacji dla rurociągów danych.
Jednak ręczne wykonanie procesu nie jest łatwe nawet dla zaawansowanych ekspertów danych, ponieważ wymaga długiego procesu, aby uchwycić cenne informacje z danych. Poza tym istnieje możliwość popełnienia błędu w kodowaniu, który może zrujnować cały proces integracji danych.
Utrzymanie ręcznego kodu ETL jest wyzwaniem. Będziesz musiał opanować wiele języków komputerowych, aby uzyskać dobrą kontrolę nad całym procesem. Być może będziesz musiał zatrudnić ekspertów we wszystkich tych językach lub zasoby, które mogą uzyskać pracę przy użyciu ograniczonych odmian.
Poza tym, będzie wiele scenariuszy integracji danych, dla których możesz potrzebować wykonać proces. Tak więc, proces będzie musiał być ponownie wykonane dla każdego nowego typu informacji wymaganych. Jednak to nie będzie powodem do zmartwień dla Twojej organizacji, gdy zdecydujesz się na rozwiązania no-code ETL. Narzędzia te nie wymagają od Ciebie lub Twojego zespołu bycia ekspertem w dziedzinie informatyki w celu konserwacji; każdy może to zrobić.
Z punktu widzenia kosztów, rozwiązania no-code ETL okażą się lepszą opcją, ponieważ istnieje predefiniowany koszt subskrypcji związany z korzystaniem z tych narzędzi, co nie jest drogie, biorąc pod uwagę wartość, jaką otrzymujesz w zamian. Ale zatrudnienie naukowca zajmującego się danymi będzie wymagało dużych inwestycji. Ponieważ roczne wynagrodzenie dewelopera wynosi ponad 100 000 dolarów, trzeba będzie również zainwestować w innych, którzy mogą nie być ekspertami, ale muszą znać procesy ETL ułatwiające pracę naukowca zajmującego się danymi. Podobnie, specjalistyczny sprzęt byłby również niezbędny, co dodatkowo zwiększa twoje koszty.
Pod względem wydajności, ręczne kodowanie ETL zdecydowanie dostaje górną rękę. To dlatego, że możesz uzyskać niestandardowy proces oparty na potrzebach organizacyjnych. Możesz zmniejszyć lub zwiększyć źródła danych, umieszczając własne reguły podczas procesu transformacji. Wszystkie te działania nie są możliwe w przypadku narzędzi no-code ETL. Te no-code ETL rozwiązania bazują już na predefiniowanym kodzie, który uruchamia proces zgodnie z definicją. Dlatego też ogólna wydajność wyników może się nieznacznie różnić.
Narzędzia ETL mają tendencję do skalowania w zależności od organizacyjnych źródeł danych i zmian wymagań. Więc nie będzie dużo, jeśli pójdziesz duży w przyszłości. Jednak korzystanie z ręcznego procesu integracji danych będzie wymagało od Ciebie stworzenia jeszcze bardziej rozbudowanych linii kodu, aby uzyskać wynik.
ETL Narzędzia pozwalają również na automatyzację przepływu pracy, ponieważ dane zostaną wyodrębnione, przekształcone i załadowane do wymaganego repozytorium w oparciu o to, kiedy i jak zaplanowałeś ten proces. Wszystkie te informacje są zwykle pozyskiwane z hurtowni danych. Nie będziesz musiał wykonywać każdego kroku potoku danych poprzez kodowanie. W przypadku ręcznego procesu ETL, wszystkie bazy danych i repozytoria będą musiały być ręcznie dołączone z rozbudowanym kodem do przeprowadzenia całego procesu.
Narzędzia no-code ETL są idealne w sytuacji, gdy posiadasz rozbudowane bazy danych z wymaganą nadmierną pracą kodowania. Jeśli jednak Twoje bazy danych nie są zbytnio rozbudowane lub wymagane informacje nie są pilne, możesz wybrać ręczne ETL. Jednak nawet w tym przypadku musisz być gotowy do napisania obszernych linii kodu.
Kolejną różnicą między ręcznym ETL a no-code ETL jest liczba źródeł danych. Jednak możesz użyć tych metod dla dowolnej liczby źródeł danych. Jednak im mniejsza liczba źródeł danych, tym mniejsza będzie złożoność procesu w przypadku ręcznego ETL. Narzędzia no-code ETL pozwalają połączyć dowolną liczbę baz danych bez konieczności dodatkowego kodowania.
Aby uaktualnić lub zmienić obecną mapę danych lub ścieżkę prowadzenia ETL, narzędzia no-code mogą być bardzo pomocne. Będziesz musiał ponownie wykonać cały proces kodowania dla nowszego kodu z ręcznym procesem kodowania. Jeśli wybrałbyś narzędzia open source ETL, wprowadzanie poprawek zgodnie z Twoimi potrzebami lub dostosowywanie go będzie jeszcze bardziej skomplikowane.
No-code ETL Rozwiązania mogą być pomocne dla Twojego biznesu, ponieważ mogą pracować bez kodowania. W przypadku typowego no-code ETL, możesz użyć prostego narzędzia interfejsu użytkownika do stworzenia mapy danych, aby przedstawić ścieżkę do serwera. Następnie serwer może uruchomić cały proces na automacie, nie wymagając dalszej pomocy od Ciebie.
Dodawanie reguł transformacji jest również jednym ze sposobów, w jaki ETL może Ci pomóc. Czyszczenie, reorganizacja, rozdzielanie lub usuwanie zestawów danych jest możliwe, aby zapewnić dostarczenie aktualnych i istotnych informacji. Sprawdzanie jakości wyodrębnionych danych jest również możliwe poprzez zastosowanie kilku prostych reguł do procesu.
Cały proces ETL można zaplanować, więc jego ręczne uruchomienie nie będzie wymagane do uzyskania aktualnych zbiorów danych i informacji do podejmowania strategicznych decyzji. Poza tym, wizualny, intuicyjny i przyjazny dla użytkownika interfejs zapewnia, że każdy może wykorzystać te ETL narzędzia, aby zaoszczędzić czas, zwiększyć wydajność i uzyskać lepsze wyniki.
Podczas pracy z procesami no-code ETL napotkasz wiele scenariuszy, w których narzędzia ETL są pomocne. Należą do nich:
Łączniki
Jeśli masz różne rurociągi danych, możesz je łatwo połączyć bez dodawania jakiejkolwiek linii kodu. Na przykład, jeśli dane twojego klienta są przechowywane w Oracle, podczas gdy informacje o zamówieniach są w Microsoft Excel, narzędzie połączy się z tymi magazynami danych.
Profilowanie danych
Będziesz musiał zdefiniować dane, aby uzyskać z nich jak najwięcej. Procesy ETL mogą pozwolić Ci na wprowadzenie zmiennych danych, takich jak typy, integralność i jakość. Na podstawie zdefiniowanych wartości, dane zostaną automatycznie posortowane.
Wbudowane transformacje
W oprogramowaniu ETL mogą być dostępne zbudowane transformacje, które można bezpośrednio zastosować do surowych danych, co znacznie ułatwia sprawę.
Wygodne planowanie
Możesz zaplanować potok ETL z określonymi wyzwalaczami, dzięki czemu rzeczy pozostają zautomatyzowane i nie będziesz musiał wkładać pozornego wysiłku w określonym czasie.
Jednym z najlepszych narzędzi no-code ETL jest AppMaster. Może on zautomatyzować cały proces ekstrakcji, transformacji, ładowania i walidacji danych.
Tworzenie rurociągów danych za pomocą AppMaster
Open source ETL Tools może nie być pomocne w każdej sytuacji. Potrzebujesz specjalistycznego oprogramowania do tworzenia rurociągów, które wydobywają dane i przenoszą ręczne ETL w zautomatyzowaną architekturę danych. Z pewnością możesz rozpocząć swoją organizacyjną podróż do ekstrakcji danych i integracji danych za pomocą narzędzi open source ETL. Wciąż jednak będziesz potrzebował specjalistycznego oprogramowania, które zawiera wszystkie wymagane funkcjonalności, aby stworzyć bezproblemowy rurociąg danych, który ostatecznie pomaga w przygotowaniu danych i analizie danych. AppMaster to oprogramowanie, które może w pełni zaspokoić Twoje potrzeby.
Wdrożenie najlepszych praktyk hurtowni danych
Dzięki AppMaster, możesz oczekiwać, że użyjesz bazy danychPostgreSQL do integracji danych, ładowania danych i konwertowania ich do formatu, w którym mogą pomóc w podejmowaniu ważnych decyzji dla Twojej organizacji. Wszystkie te aspekty mogą być objęte ręcznymi mechanizmami ETL, jednak z AppMasterem u boku, możesz zarządzać integracją danych bez konieczności kodowania.
Integracja źródeł danych
Będziesz musiał po prostu zintegrować różne struktury danych, z których korzysta Twoja organizacja w ręcznym ETL i pozwolić narzędziu wykonać swoje operacje. Wynikiem integracji danych będą informacje, których potrzebujesz, aby przystąpić do ważnych decyzji. W porównaniu do ręcznych ETL narzędzi, procesy integracji danych mogą być zarządzane w stosunkowo krótszym czasie. Nie musisz iść na kompromis w kwestii jakości danych lub innych czynników.
Oferuje łatwy w użyciu interfejs
AppMaster jest specjalnie zaprojektowany, aby zaoferować łatwy w użyciu interfejs podczas pomagania w wydobyciu danych. Z różnych obiektów dashboard dla różnych zainteresowanych, wyrównanie informacji, które trzeba staje się znacznie bardziej dostępne. Dostęp do właściwych informacji w odpowiednim czasie pomaga w lepszym podejmowaniu decyzji. Poza tym, taki interfejs oszczędza czas i oferuje wszystkie istotne dane na jednym ekranie.
No-code ETL Narzędzia mogą zapewnić łatwe rozwiązanie do zarządzania danymi w sposób, który może przynieść więcej możliwości rozwoju dla Twojej firmy. Nie potrzebujesz ETL programistów do wykonania procesu ETL, co czyni rzeczy o wiele łatwiejszymi, przyjaznymi dla użytkownika i opłacalnymi.
Z wieloma korzyściami związanymi z narzędziami no-code ETL, narzędzia te są nową rzeczywistością w świecie biznesu, zwłaszcza dla firm z tonami danych. Z wielu narzędzi open source ETL dostępnych, twoje poleganie musi być na platformie, która oferuje zaawansowane funkcje z łatwymi zastosowaniami, jak AppMaster.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


