
Ekipman rezervasyon uygulaması: çakışmaları önleyin ve iadeleri takip edin
Çifte rezervasyonları önleyen, iadeleri ve hasarları kaydeden, arızalı ekipmanları bakım bekletmesine alan bir ekipman rezervasyon uygulaması planlayın.
Büyük ölçekli sistemlerde veri parçalamanın rolünü, faydalarını, zorluklarını ve modern uygulamaların performansını ve ölçeklenebilirliğini nasıl geliştirebileceğini keşfedin.

Veri parçalama, verileri birden fazla sunucu veya örnek arasında bölmek ve dağıtmak için kullanılan bir tekniktir ve genellikle performansı, ölçeklenebilirliği ve yönetilebilirliği geliştirmek için büyük ölçekli sistemlerde kullanılır. Veri parçalama kavramı, tek bir tablonun her biri orijinal tablonun verilerinin bir alt kümesini içeren daha küçük bölümlere ayrıldığı yatay bölümlemeden kaynaklanır.
Veri parçalama, daha büyük bir sistemdeki verilerin birden çok küçük varlık veya "parça" arasında bölünmesini içerir. Her parça bağımsız olarak çalışarak sistemin istekleri eş zamanlı ve verimli bir şekilde işlemesini sağlarken aynı zamanda hata toleransı ve kullanılabilirlik sağlar. Parçalama, özellikle veri hacimlerinin ve kullanıcı istek oranlarının oldukça yüksek olabileceği dağıtılmış sistemlerde ve yüksek performanslı uygulamalarda yararlıdır. Bir sistem, işleme iş yükünü birden fazla parçaya yayarak, fiziksel donanım kaynaklarının sınırlamalarını etkili bir şekilde yönetebilir, sorgu yanıt sürelerini azaltabilir ve performansı artırabilir.
Görüntü kaynağı: DigitalOcean
Büyük ölçekli sistemlerde veri parçalamanın uygulanması, modern uygulamaların performansını ve ölçeklenebilirliğini iyileştirebilecek çok sayıda avantaj sunar. Bu avantajlardan bazıları şunlardır:
Veri parçalama, büyük ölçekli sistemler ve yüksek performanslı uygulamalar için önemli avantajlar sağlarken, zorlukları da vardır. Parçalama stratejisi uygulamak, sistem mimarisi, veri erişim modelleri ve uygulama gereksinimleri gibi çeşitli faktörleri göz önünde bulundurarak dikkatli bir planlama ve değerlendirme gerektirir. Geliştiricilerin veri parçalamayı kullanırken karşılaştıkları bazı zorluklar şunları içerir:
Uygun bir parçalama stratejisi seçmek karmaşık olabilir ve sistemin veri modelinin ve erişim modellerinin derinlemesine anlaşılmasını gerektirir. Uygun olmayan bir stratejinin seçilmesi verimsiz kaynak kullanımına, dengesiz iş yükü dağılımına veya karmaşık veri yönetimine yol açabilir. Sistem için en iyi parçalama stratejisini belirlemeden önce veri erişim modellerinin, büyüme tahminlerinin ve teknik gereksinimlerin dikkatli bir şekilde analiz edilmesi gerekir.
Parçalamanın kritik bir zorluğu, dağıtılmış sistem mimarilerinin artan karmaşıklığını yönetmektir. Geliştiriciler, parçalar genelinde veri tutarlılığı ve bütünlüğünü, arıza durumunda kurtarılabilirliği ve sistem çapında sorgular için performans optimizasyonunu ele almalıdır. Parçalı sistemlerin ek karmaşıklığını etkili bir şekilde yönetmek için uygun araçlara, izleme ve yedekleme mekanizmalarına sahip olmak çok önemlidir.
Veri parçalamanın uygulanmasındaki en büyük zorluklardan biri, parçalar arasında veri tutarlılığı ve bütünlüğü sağlamaktır. Veriler birden çok sunucuya yayıldığından, özellikle sistem birden çok parçayı kapsayan atomik işlemler gerektirdiğinde tutarlılığı korumak zor olabilir. Geliştiricilerin, parçalar arasında veri tutarlılığını korumak için dağıtılmış işlemler, nihai tutarlılık veya diğer stratejiler gibi teknikleri benimsemesi gerekir.
Bu zorluklara rağmen, özellikle büyük ölçekli sistemler ve yüksek performanslı uygulamalar için veri parçalamanın faydaları önemlidir. Dikkatli planlama, strateji seçimi ve güçlü sistem tasarımı ile geliştiriciler, veri parçalamayı başarıyla uygulayabilir ve iyileştirilmiş ölçeklenebilirlik ve performans potansiyelini ortaya çıkarabilir.
Veri parçalama, ölçeklenebilir ve yüksek performanslı uygulamalar oluşturmada kritik bir bileşendir. Farklı parçalama stratejilerini ve tekniklerini anlamak, özel gereksinimleriniz için en uygun yaklaşımı seçmenizi sağlayacaktır. Bu bölümde üç ortak parçalama stratejisi incelenecektir: aralık tabanlı, karma tabanlı ve dizin tabanlı parçalama.
Aralığa dayalı parçalama, verilerin belirli bir anahtar için belirli bir değer aralığına göre bölümlenmesini içerir. Bu, geliştiricinin anlaması ve uygulaması için basit bir kavram olabilir. Örneğin, müşteri kimliği aralığına göre müşteri kayıtlarını parçalayabilirsiniz (örneğin, A parçasında 1-1000 müşteri kimlikleri, B parçasında 1001-2000 vb.). Bu yöntem, verilerin parçalar arasında eşit olarak dağıtılmasını ve anahtar aralığı tarafından kolayca sorgulanabilmesini sağlar.
Ancak menzil tabanlı parçalamanın bazı dezavantajları vardır. Bunlardan biri, seçilen anahtarın çarpık olması durumunda eşit olmayan veri dağılımı potansiyelidir. Bu durum, bazı parçalar aşırı yüklenirken diğerleri yeterince kullanılmadığı için etkin noktalara ve performans darboğazlarına yol açabilir. Tek tip dağılıma sahip bir parça anahtarı seçmek, bu sorunu gidermek için çok önemlidir.
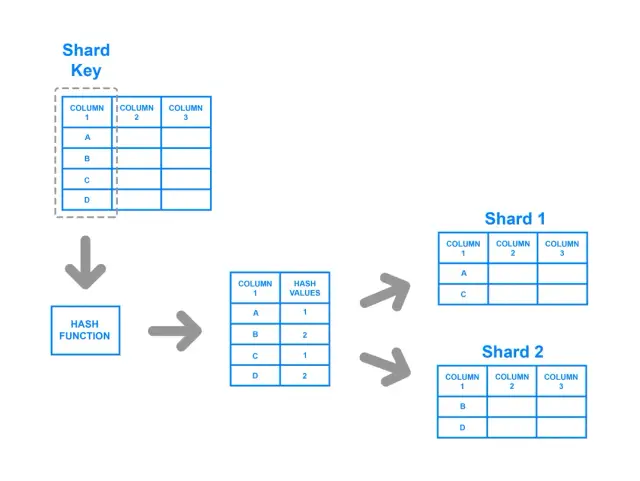
Karma tabanlı parçalama, parça anahtarına bir karma işlevi uygulamayı içerir ve sonuçta elde edilen karma, verilerin hangi parçaya ait olduğunu belirler. Karma işlevi, girdi değerlerinden bağımsız olarak dengeli bir çıktı verecek şekilde tasarlandığından, bu strateji, verilerin parçalar arasında daha düzgün bir şekilde dağıtılmasını sağlar. Bu yaklaşımda, bir anahtar-değer çifti hashlenir ve hash fonksiyonunun sonucu, verilerin yönlendirildiği shard'ı belirler.
Dengeli bir dağıtım elde etmedeki güçlü yanlarına rağmen, hash tabanlı parçalamanın potansiyel sakıncaları vardır. Örneğin, orijinal anahtarlar arasındaki ilişkiler karma sürecinde kaybolduğundan, bu yöntemle aralık sorgularını uygulamak zor olabilir. Ayrıca, parça sayısı değiştiğinde, karma tabanlı yöntemlerin çoğu önemli miktarda verinin yeniden düzenlenmesini ve yeniden dağıtılmasını gerektirir, bu da kaynak yoğun ve zaman alıcı olabilir.
Dizin tabanlı parçalama, hangi parçanın belirli bir anahtar için verileri tuttuğunu izlemek için ayrı bir arama tablosu veya hizmeti kullanır. Veriler sisteme yazıldığında, dizin hizmeti, konumunu uygulamaya döndürerek uygun parçayı belirler. Bu yöntem, uygulamanın hem anahtar tabanlı hem de aralık sorgularını verimli bir şekilde gerçekleştirmesini sağlar.
Yine de, dizin tabanlı parçalamanın, tek bir hata noktasına veya performans darboğazına dönüşebilecek ayrı bir dizin hizmetini yönetme gibi zorlukları vardır. Bu nedenle, bu yaklaşımı kullanırken dizin hizmetinin güvenilirliğini ve ölçeklenebilirliğini sağlamak önemlidir.
AppMaster gibi kodsuz platformlar, karmaşıklığı geliştirme sürecinden soyutlayarak işletmelerin uygulamaları daha hızlı oluşturmasına, devreye almasına ve ölçeklendirmesine olanak tanır. no-code platformlarda veri parçalamanın uygulanması, geliştiricilerin uygulama mantığı ve kullanıcı deneyimleri oluşturmaya odaklanmalarına olanak tanırken, platform temel veri yönetimi, ölçekleme ve performans optimizasyonunu ele aldığından, faydalarını daha da artırabilir.
Veri parçalama tekniklerini no-code platformlara entegre etmek, geliştiricilerin kapsamlı manuel yapılandırma veya kodlama gerektirmeden yerleşik parçalama yeteneklerinden yararlanabilmesi nedeniyle hızlı uygulama geliştirmeye olanak tanır. Sonuç olarak, geliştiriciler yenilikçi kullanıcı deneyimleri tasarlama ve iş süreçlerini iyileştirme gibi katma değerli etkinliklere daha fazla zaman ve kaynak ayırabildikleri için işletmeler daha uygun maliyetli ve verimli bir uygulama geliştirme sürecinden yararlanabilir.
Ayrıca, no-code platformlarda veri parçalamayı dahil etmek, uygulamaların sıfırdan ölçeklenebilirlik göz önünde bulundurularak oluşturulabilmesini sağlar. Veri parçalama stratejilerinden yararlanan no-code uygulamalar, performans darboğazları veya kararlılık sorunları yaşamadan veri hacimlerinin ve kullanıcı tabanlarının büyümesini sorunsuz bir şekilde karşılayabilir. Bu özellik, uygulamalarının gelişen iş gereksinimlerine göre uyarlanmasını ve ölçeklenmesini bekleyen modern kuruluşlar için özellikle değerlidir.
AppMaster, modern, sezgisel arayüzü güçlü arka uç, web ve mobil uygulama oluşturma yetenekleriyle birleştiren lider bir kodsuz platformdur . Ölçeklenebilir ve yüksek performanslı uygulamalar geliştirmede veri parçalamanın önemini kabul eden AppMaster, geliştiricilerin uygulamalarında kolayca veri bölümleme ve optimizasyon uygulamalarını sağlamak için yerleşik bir parçalama stratejisini entegre eder.
AppMaster sunduğu veri parçalama yetenekleriyle geliştiriciler, verileri birden fazla örnek veya sunucu arasında otomatik olarak dağıtan uygulamalar oluşturarak, uygulamaların yüksek iş yükleri ve büyük miktarda veri altında bile yüksek düzeyde ölçeklenebilir ve performanslı olmasını sağlayabilir.
AppMaster veri parçalama özelliklerinden yararlanarak, geliştiricilerin artık parça yerleştirme, yeniden dengeleme ve bakım görevlerini yapılandırmak ve yönetmek için önemli çaba harcamasına gerek kalmadığından, işletmeler geliştirme sürecinde hem zamandan hem de paradan tasarruf edebilir. Bunun yerine, uygulamalarının büyük ölçekli sistemleri ve yüksek performans gereksinimlerini karşılayacak şekilde tasarlandığından emin olurken yenilikçi, müşteri odaklı çözümler oluşturmaya odaklanabilirler.
Veri parçalama, büyük ölçekli sistemlerin yönetiminde kritik öneme sahiptir ve modern uygulamaların önemli bir bileşeni haline gelmiştir. Mike Vance'in uygun bir şekilde ifade ettiği gibi , "İnovasyon, yeninin yaratılması veya eskinin yeni bir şekilde yeniden düzenlenmesidir" . Geliştiriciler, çeşitli parçalama stratejilerini ve tekniklerini anlayarak ve AppMaster gibi no-code platformların yenilikçi gücünden yararlanarak, zaman içinde büyüyüp gelişirken bile yanıt verebilirliklerini ve verimliliklerini koruyan ölçeklenebilir, yüksek performanslı uygulamalar oluşturabilirler.
Veri parçalama, büyük ölçekli sistemlerde performansı, ölçeklenebilirliği ve yönetilebilirliği geliştirmek için verileri birden fazla sunucu veya örnek arasında bölmek için kullanılan bir stratejidir.
Veri parçalama, fiziksel donanım kaynaklarının sınırlamalarını yönetmeye, sorgu yanıt sürelerini azaltmaya ve modern uygulamaların genel performansını ve ölçeklenebilirliğini geliştirmeye yardımcı olur.
Zorluklar arasında uygun parçalama stratejisinin belirlenmesi, dağıtılmış sistemlerin karmaşıklığının yönetilmesi ve parçalar arasında veri tutarlılığı ve bütünlüğünün sağlanması yer alır.
Ortak parçalama stratejileri, aralık tabanlı parçalama, karma tabanlı parçalama ve dizin tabanlı parçalama içerir.
AppMaster yüksek düzeyde ölçeklenebilir ve yüksek performanslı uygulamalar oluşturmak için yerleşik parçalama stratejisine sahip no-code bir platformdan yararlanır ve geliştiricilerin veri parçalamanın karmaşıklığı yerine uygulama mantığına odaklanmasına olanak tanır.
Evet, veri parçalama, kapsamlı manuel yapılandırma veya kodlama gerektirmeden hızlı uygulama geliştirme ve uygulamaların ölçeklendirilmesini sağlayan no-code platformlarda uygulanabilir.



Ücretsiz planla AppMaster ile denemeler yapın.
Hazır olduğunuzda uygun aboneliği seçebilirsiniz.


