
Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahren Sie, welche Rolle das Sharding von Daten in großen Systemen spielt, welche Vorteile und Herausforderungen damit verbunden sind und wie es die Leistung und Skalierbarkeit moderner Anwendungen verbessern kann.

Data Sharding ist eine Technik zur Partitionierung und Verteilung von Daten auf mehrere Server oder Instanzen, die häufig in großen Systemen zur Verbesserung der Leistung, Skalierbarkeit und Verwaltbarkeit eingesetzt wird. Das Konzept des Data Sharding hat seinen Ursprung in der horizontalen Partitionierung, bei der eine einzelne Tabelle in kleinere Partitionen aufgeteilt wird, die jeweils eine Teilmenge der Daten der ursprünglichen Tabelle enthalten.
Beim Data Sharding werden die Daten innerhalb eines größeren Systems auf mehrere kleinere Einheiten oder "Shards" aufgeteilt. Jeder Shard arbeitet unabhängig und ermöglicht es dem System, Anfragen gleichzeitig und effizient zu verarbeiten und gleichzeitig Fehlertoleranz und Verfügbarkeit zu gewährleisten. Sharding ist besonders hilfreich in verteilten Systemen und Hochleistungsanwendungen, bei denen das Datenvolumen und die Anzahl der Benutzeranfragen sehr hoch sein können. Durch die Verteilung der Verarbeitungslast auf mehrere Shards kann ein System die Beschränkungen der physischen Hardwareressourcen effektiv verwalten, die Antwortzeiten für Abfragen verringern und die Leistung steigern.
Bildquelle: © DigitalOcean
Die Implementierung von Data Sharding in großen Systemen bietet zahlreiche Vorteile, die die Leistung und Skalierbarkeit moderner Anwendungen verbessern können. Einige dieser Vorteile sind:
Data Sharding bietet zwar erhebliche Vorteile für große Systeme und Hochleistungsanwendungen, birgt aber auch Herausforderungen. Die Implementierung einer Sharding-Strategie erfordert eine sorgfältige Planung und Überlegung unter Berücksichtigung verschiedener Faktoren wie Systemarchitektur, Datenzugriffsmuster und Anwendungsanforderungen. Einige Herausforderungen, mit denen Entwickler beim Einsatz von Data Sharding konfrontiert werden, sind:
Die Auswahl einer geeigneten Sharding-Strategie kann komplex sein und erfordert ein tiefes Verständnis des Datenmodells und der Zugriffsmuster des Systems. Die Wahl einer ungeeigneten Strategie kann zu einer ineffizienten Ressourcennutzung, einer unausgewogenen Verteilung der Arbeitslast oder einer komplizierten Datenverwaltung führen. Eine sorgfältige Analyse der Datenzugriffsmuster, der Wachstumsprognosen und der technischen Anforderungen ist erforderlich, bevor die beste Sharding-Strategie für das System festgelegt werden kann.
Eine entscheidende Herausforderung beim Sharding ist die Bewältigung der erhöhten Komplexität verteilter Systemarchitekturen. Die Entwickler müssen sich mit der Datenkonsistenz und -integrität über mehrere Shards hinweg, der Wiederherstellbarkeit im Falle von Ausfällen und der Leistungsoptimierung für systemweite Abfragen befassen. Um die zusätzliche Komplexität von Sharding-Systemen effektiv zu bewältigen, sind geeignete Tools, Überwachungs- und Backup-Mechanismen erforderlich.
Eine der größten Herausforderungen bei der Implementierung von Daten-Sharding ist die Sicherstellung der Datenkonsistenz und -integrität über Shards hinweg. Da die Daten über mehrere Server verteilt sind, kann die Aufrechterhaltung der Konsistenz schwierig werden, insbesondere wenn das System atomare Transaktionen über mehrere Shards hinweg erfordert. Die Entwickler müssen Techniken wie verteilte Transaktionen, eventuelle Konsistenz oder andere Strategien anwenden, um die Datenkonsistenz über mehrere Shards hinweg zu gewährleisten.
Trotz dieser Herausforderungen sind die Vorteile von Data Sharding beträchtlich, insbesondere bei großen Systemen und Hochleistungsanwendungen. Mit sorgfältiger Planung, Strategieauswahl und leistungsfähigem Systemdesign können Entwickler Data Sharding erfolgreich implementieren und das Potenzial für verbesserte Skalierbarkeit und Leistung ausschöpfen.
Daten-Sharding ist eine entscheidende Komponente bei der Entwicklung skalierbarer und leistungsstarker Anwendungen. Wenn Sie die verschiedenen Sharding-Strategien und -Techniken verstehen, können Sie den für Ihre spezifischen Anforderungen am besten geeigneten Ansatz wählen. In diesem Abschnitt werden drei gängige Sharding-Strategien untersucht: bereichsbasiertes, hashbasiertes und verzeichnisbasiertes Sharding.
Beim bereichsbasierten Sharding werden Daten auf der Grundlage eines bestimmten Wertebereichs für einen bestimmten Schlüssel partitioniert. Für den Entwickler kann dies ein einfaches Konzept sein, das er verstehen und umsetzen kann. Sie könnten zum Beispiel Kundendatensätze auf der Grundlage des Kunden-ID-Bereichs aufteilen (z. B. Kunden-IDs 1-1000 auf Shard A, 1001-2000 auf Shard B usw.). Diese Methode stellt sicher, dass die Daten gleichmäßig über die Shards verteilt sind und einfach über den Schlüsselbereich abgefragt werden können.
Das bereichsbasierte Sharding hat jedoch einige Nachteile. Einer davon ist die Möglichkeit einer ungleichmäßigen Datenverteilung, wenn der gewählte Schlüssel schief ist. Dies kann zu Hotspots und Leistungsengpässen führen, da einige Shards überlastet werden können, während andere nicht ausgelastet sind. Die Wahl eines Shard-Schlüssels mit gleichmäßiger Verteilung ist wichtig, um diesem Problem entgegenzuwirken.
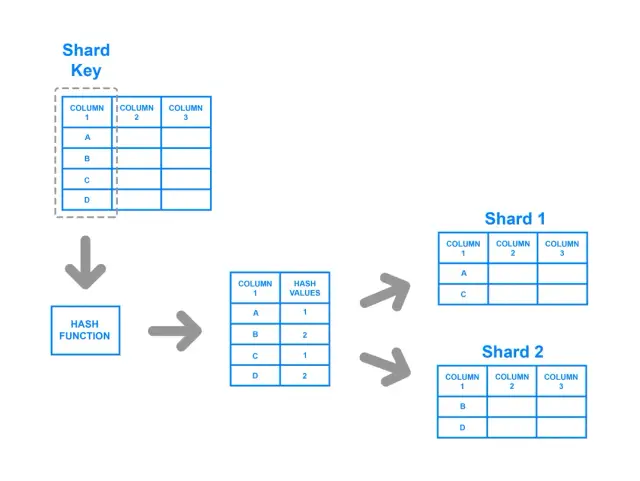
Beim Hash-basierten Sharding wird eine Hash-Funktion auf den Shard-Schlüssel angewandt, und der resultierende Hash-Wert bestimmt, zu welchem Shard die Daten gehören. Diese Strategie gewährleistet eine gleichmäßigere Verteilung der Daten auf die Shards, da die Hash-Funktion so konzipiert ist, dass sie unabhängig von den Eingabewerten eine ausgewogene Ausgabe liefert. Bei diesem Ansatz wird ein Schlüssel-Wert-Paar gehasht, und das Ergebnis der Hash-Funktion bestimmt den Shard, an den die Daten gerichtet sind.
Trotz seiner Stärken beim Erreichen einer ausgewogenen Verteilung hat das hashbasierte Sharding potenzielle Nachteile. So kann es beispielsweise schwierig sein, mit dieser Methode Bereichsabfragen zu implementieren, da die Beziehungen zwischen den ursprünglichen Schlüsseln beim Hashing-Prozess verloren gehen. Wenn sich die Anzahl der Shards ändert, müssen bei den meisten hashbasierten Methoden außerdem erhebliche Datenmengen neu gehasht und verteilt werden, was ressourcen- und zeitaufwendig sein kann.
Beim verzeichnisbasierten Sharding wird eine separate Nachschlagetabelle oder ein Dienst verwendet, um festzustellen, welcher Shard die Daten für einen bestimmten Schlüssel enthält. Wenn Daten in das System geschrieben werden, ermittelt der Verzeichnisdienst den entsprechenden Shard und gibt dessen Speicherort an die Anwendung zurück. Diese Methode ermöglicht es der Anwendung, sowohl schlüsselbasierte als auch Bereichsabfragen effizient durchzuführen.
Dennoch hat das verzeichnisbasierte Sharding seine Tücken, z. B. die Verwaltung eines separaten Verzeichnisdienstes, der zu einem Single Point of Failure oder einem Leistungsengpass werden könnte. Daher muss bei diesem Ansatz unbedingt die Zuverlässigkeit und Skalierbarkeit des Verzeichnisdienstes gewährleistet sein.
No-Code-Plattformen wie AppMaster ermöglichen es Unternehmen, Anwendungen schneller zu erstellen, bereitzustellen und zu skalieren, indem sie die Komplexität aus dem Entwicklungsprozess herausnehmen. Die Implementierung von Data Sharding in no-code -Plattformen kann die Vorteile dieser Plattformen noch verstärken, da sich die Entwickler auf die Erstellung von Anwendungslogik und Benutzererfahrungen konzentrieren können, während die Plattform die zugrunde liegende Datenverwaltung, Skalierung und Leistungsoptimierung übernimmt.
Die Integration von Data-Sharding-Techniken in no-code Plattformen ermöglicht eine schnelle Anwendungsentwicklung, da Entwickler die integrierten Sharding-Funktionen nutzen können, ohne dass eine umfangreiche manuelle Konfiguration oder Kodierung erforderlich ist. Dadurch profitieren Unternehmen von einem kostengünstigeren und effizienteren Anwendungsentwicklungsprozess, da die Entwickler mehr Zeit und Ressourcen für wertschöpfende Aktivitäten wie die Gestaltung innovativer Benutzererfahrungen und die Verfeinerung von Geschäftsprozessen aufwenden können.
Darüber hinaus gewährleistet die Integration von Data Sharding in no-code Plattformen, dass Anwendungen von Anfang an mit Blick auf Skalierbarkeit entwickelt werden können. Durch die Nutzung von Data-Sharding-Strategien können no-code -Anwendungen problemlos das Wachstum von Datenvolumen und Benutzerbasis bewältigen, ohne dass es zu Leistungsengpässen oder Stabilitätsproblemen kommt. Diese Funktion ist besonders wertvoll für moderne Unternehmen, die von ihren Anwendungen erwarten, dass sie sich an die sich wandelnden Geschäftsanforderungen anpassen und skalieren.
AppMaster ist eine führende No-Code-Plattform, die eine moderne, intuitive Benutzeroberfläche mit leistungsstarken Funktionen zur Erstellung von Backend-, Web- und mobilen Anwendungen kombiniert. AppMaster hat die Bedeutung von Data Sharding für die Entwicklung skalierbarer und hochleistungsfähiger Anwendungen erkannt und eine integrierte Sharding-Strategie entwickelt, die es Entwicklern ermöglicht, Datenpartitionierung und -optimierung einfach in ihren Anwendungen zu implementieren.
Mit den von AppMaster angebotenen Data-Sharding-Funktionen können Entwickler Anwendungen erstellen, die Daten automatisch auf mehrere Instanzen oder Server verteilen und so sicherstellen, dass die Anwendungen auch bei hoher Arbeitslast und großen Datenmengen hoch skalierbar und performant sind.
Durch die Nutzung der Daten-Sharding-Funktionen von AppMaster können Unternehmen sowohl Zeit als auch Geld im Entwicklungsprozess sparen, da die Entwickler keinen erheblichen Aufwand mehr für die Konfiguration und Verwaltung von Shard-Platzierung, Rebalancing und Wartungsaufgaben betreiben müssen. Stattdessen können sie sich auf die Entwicklung innovativer, kundenorientierter Lösungen konzentrieren und gleichzeitig sicherstellen, dass ihre Anwendungen für die Verwaltung großer Systeme und Hochleistungsanforderungen ausgelegt sind.
Data Sharding ist für die Verwaltung großer Systeme von entscheidender Bedeutung und hat sich zu einer wesentlichen Komponente moderner Anwendungen entwickelt. " Innovation ist die Schaffung von Neuem oder die Umgestaltung von Altem auf neue Weise", wie Mike Vance treffend formulierte. Durch das Verständnis der verschiedenen Sharding-Strategien und -Techniken und die Nutzung der innovativen Leistung von no-code -Plattformen wie AppMaster können Entwickler skalierbare, leistungsstarke Anwendungen erstellen, die ihre Reaktionsfähigkeit und Effizienz beibehalten, auch wenn sie im Laufe der Zeit wachsen und sich weiterentwickeln.
Data Sharding ist eine Strategie, die in großen Systemen zur Partitionierung von Daten auf mehrere Server oder Instanzen verwendet wird, um die Leistung, Skalierbarkeit und Verwaltbarkeit zu verbessern.
Data Sharding hilft, die Grenzen der physischen Hardwareressourcen zu überwinden, die Antwortzeiten für Abfragen zu verkürzen und die Gesamtleistung und Skalierbarkeit moderner Anwendungen zu verbessern.
Zu den Herausforderungen gehören die Festlegung einer geeigneten Sharding-Strategie, die Bewältigung der Komplexität verteilter Systeme und die Gewährleistung der Datenkonsistenz und -integrität über mehrere Shards hinweg.
Zu den gängigen Sharding-Strategien gehören bereichsbasiertes Sharding, Hash-basiertes Sharding und verzeichnisbasiertes Sharding.
AppMaster nutzt eine no-code Plattform mit einer integrierten Sharding-Strategie, um hoch skalierbare und leistungsstarke Anwendungen zu erstellen, die es Entwicklern ermöglichen, sich auf die Anwendungslogik zu konzentrieren, anstatt sich mit der Komplexität des Daten-Shardings auseinanderzusetzen.
Ja, Data Sharding kann in no-code Plattformen implementiert werden und ermöglicht eine schnelle Anwendungsentwicklung und Skalierung von Anwendungen, ohne dass eine umfangreiche manuelle Konfiguration oder Kodierung erforderlich ist.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


