La répartition des données est une technique utilisée pour partitionner et distribuer les données sur plusieurs serveurs ou instances, souvent employée dans les systèmes à grande échelle pour améliorer les performances, l'évolutivité et la facilité de gestion. Le concept de répartition des données trouve son origine dans le partitionnement horizontal, où une table unique est divisée en partitions plus petites, chacune contenant un sous-ensemble des données de la table d'origine.
La répartition des données consiste à diviser les données d'un système plus vaste en plusieurs entités plus petites, ou "shards". Chaque groupe fonctionne de manière indépendante, ce qui permet au système de traiter les demandes simultanément et efficacement, tout en assurant la tolérance aux pannes et la disponibilité. Le sharding est particulièrement utile dans les systèmes distribués et les applications à haute performance, où les volumes de données et les taux de requêtes des utilisateurs peuvent être très importants. En répartissant la charge de travail sur plusieurs serveurs, un système peut gérer efficacement les limites des ressources matérielles physiques, réduire les temps de réponse des requêtes et améliorer les performances.
Source de l'image : DigitalOcean
Avantages de la répartition des données dans les systèmes à grande échelle
La mise en œuvre de la répartition des données dans les systèmes à grande échelle offre de nombreux avantages qui peuvent améliorer les performances et l'évolutivité des applications modernes. Voici quelques-uns de ces avantages :
- Amélioration de l'évolutivité : L'un des principaux avantages de la répartition des données est sa capacité à améliorer l'évolutivité d'une application. En répartissant les données et la charge de travail sur plusieurs serveurs, les développeurs peuvent surmonter les difficultés liées à l'augmentation des volumes de données et des demandes des utilisateurs. Cela permet d'étendre le système en fonction des besoins, plutôt que de l'augmenter, ce qui implique d'accroître les ressources d'un seul serveur.
- Amélioration des performances : Les données sont divisées en petits morceaux et distribuées sur plusieurs serveurs, de sorte que la charge de travail est répartie sur différents serveurs. Cela permet un traitement simultané et une réduction de la concurrence pour une ressource unique, ce qui améliore les performances du système.
- Traitement plus rapide des requêtes : La répartition des données peut accélérer considérablement le temps de traitement des requêtes, en particulier dans les systèmes où les opérations de lecture et d'écriture sont nombreuses. En répartissant les données sur plusieurs serveurs, une requête peut être traitée uniquement par le serveur concerné, ce qui évite d'avoir à parcourir un ensemble de données plus important et monolithique. Il en résulte des temps de réponse plus courts pour les demandes des utilisateurs et une latence plus faible.
- Amélioration de la disponibilité et de la tolérance aux pannes : En répartissant les données sur plusieurs serveurs ou instances, le sharding permet de s'assurer qu'une application reste disponible et réactive même en cas de défaillance ou de panne d'un des serveurs. Cela rend le système plus tolérant aux pannes et plus résistant aux temps d'arrêt causés par des points de défaillance uniques.
- Utilisation efficace des ressources : Le sharding offre une méthode plus efficace et plus équilibrée d'utilisation des ressources du système, plutôt que de concentrer la charge de travail sur un seul serveur. Cette utilisation efficace des ressources permet un degré de concurrence plus élevé, ce qui se traduit souvent par une amélioration des performances et du débit.
Les défis de l'archivage des données
Si la répartition des données présente des avantages considérables pour les systèmes à grande échelle et les applications à hautes performances, elle n'est pas sans poser de problèmes. La mise en œuvre d'une stratégie de stockage de données nécessite une planification et une réflexion approfondies, en tenant compte de divers facteurs tels que l'architecture du système, les schémas d'accès aux données et les exigences de l'application. Voici quelques-uns des défis auxquels les développeurs ont tendance à être confrontés lorsqu'ils utilisent le stockage de données :
Déterminer la stratégie de sharding optimale
Le choix d'une stratégie de stockage appropriée peut s'avérer complexe et nécessiter une compréhension approfondie du modèle de données et des schémas d'accès du système. Le choix d'une stratégie inadaptée peut conduire à une utilisation inefficace des ressources, à une répartition déséquilibrée de la charge de travail ou à une gestion compliquée des données. Une analyse minutieuse des modèles d'accès aux données, des projections de croissance et des exigences techniques est nécessaire avant de déterminer la meilleure stratégie de sharding pour le système.
Gestion de la complexité des systèmes distribués
L'un des défis majeurs du sharding est la gestion de la complexité accrue des architectures de systèmes distribués. Les développeurs doivent se préoccuper de la cohérence et de l'intégrité des données entre les différents systèmes, de la capacité de récupération en cas de défaillance et de l'optimisation des performances pour les requêtes à l'échelle du système. Il est essentiel de disposer d'outils, de mécanismes de surveillance et de sauvegarde adéquats pour gérer efficacement la complexité accrue des systèmes distribués.
Assurer la cohérence et l'intégrité des données
L'un des principaux défis liés à la mise en œuvre du sharding de données consiste à garantir la cohérence et l'intégrité des données sur l'ensemble des serveurs. Étant donné que les données sont réparties sur plusieurs serveurs, le maintien de la cohérence peut s'avérer difficile, en particulier lorsque le système nécessite des transactions atomiques sur plusieurs serveurs. Les développeurs doivent adopter des techniques telles que les transactions distribuées, la cohérence éventuelle ou d'autres stratégies pour maintenir la cohérence des données entre les différents serveurs.
Malgré ces difficultés, les avantages de la répartition des données sont considérables, en particulier pour les systèmes à grande échelle et les applications à haute performance. Grâce à une planification minutieuse, à la sélection de stratégies et à une conception puissante du système, les développeurs peuvent mettre en œuvre avec succès le partage des données et exploiter son potentiel pour améliorer l'évolutivité et les performances.
Stratégies et techniques de stockage
La répartition des données est un élément essentiel de la création d'applications évolutives et performantes. Comprendre les différentes stratégies et techniques de stockage vous permettra de choisir l'approche la plus adaptée à vos besoins spécifiques. Cette section explore trois stratégies de stockage communes : le stockage basé sur la plage, le stockage basé sur le hachage et le stockage basé sur le répertoire.
Répartition basée sur l'étendue
Le sharding basé sur une plage de valeurs consiste à partitionner les données en fonction d'une plage spécifique de valeurs pour une clé donnée. Il s'agit d'un concept simple à comprendre et à mettre en œuvre pour le développeur. Par exemple, vous pouvez répartir les enregistrements des clients en fonction de la plage d'ID des clients (par exemple, les ID des clients 1-1000 sur le serveur A, 1001-2000 sur le serveur B, et ainsi de suite). Cette méthode garantit que les données sont réparties de manière homogène entre les groupes et qu'elles peuvent être facilement interrogées à l'aide de la plage de clés.
Cependant, la répartition par plage présente certains inconvénients. L'un d'entre eux est la possibilité d'une distribution inégale des données si la clé choisie est asymétrique. Cette situation peut entraîner l'apparition de points chauds et de goulets d'étranglement au niveau des performances, car certains dépôts peuvent être surchargés, tandis que d'autres restent sous-utilisés. Le choix d'une clé de répartition uniforme est essentiel pour remédier à ce problème.
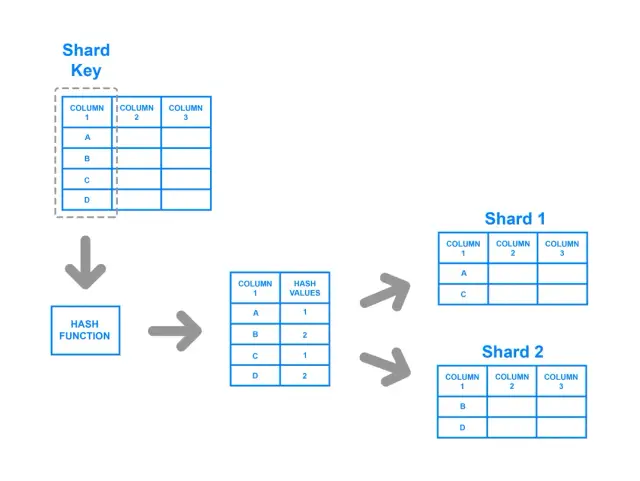
Répartition basée sur le hachage
Le sharding basé sur le hachage consiste à appliquer une fonction de hachage à la clé du shard, le hachage résultant déterminant le shard auquel les données appartiennent. Cette stratégie garantit une distribution plus uniforme des données dans les répertoires, car la fonction de hachage est conçue pour produire un résultat équilibré quelles que soient les valeurs d'entrée. Dans cette approche, une paire clé-valeur est hachée et le résultat de la fonction de hachage détermine le groupe vers lequel les données sont dirigées.
Malgré ses avantages en termes de distribution équilibrée, le sharding basé sur le hachage présente des inconvénients potentiels. Par exemple, il peut être difficile de mettre en œuvre des requêtes de plage avec cette méthode, car les relations entre les clés d'origine sont perdues dans le processus de hachage. En outre, en cas de modification du nombre de fichiers, la plupart des méthodes basées sur le hachage exigent qu'une quantité substantielle de données soit remaniée et redistribuée, ce qui peut s'avérer coûteux en ressources et en temps.
Regroupement basé sur un répertoire
Le sharding basé sur un répertoire utilise une table de recherche ou un service séparé pour savoir quel shard détient les données d'une clé donnée. Lorsque des données sont écrites dans le système, le service d'annuaire détermine le groupe de stockage approprié et renvoie son emplacement à l'application. Cette méthode permet à l'application d'effectuer efficacement des requêtes basées sur les clés et sur l'étendue des données.
Cependant, le sharding basé sur un annuaire présente des difficultés, telles que la gestion d'un service d'annuaire distinct qui pourrait devenir un point de défaillance unique ou un goulot d'étranglement au niveau des performances. Il est donc essentiel de garantir la fiabilité et l'évolutivité du service d'annuaire lors de l'utilisation de cette approche.
Les plateformes sans code comme AppMaster permettent aux entreprises de créer, de déployer et de mettre à l'échelle des applications plus rapidement en éliminant la complexité du processus de développement. La mise en œuvre de la répartition des données dans les plateformes no-code peut encore améliorer leurs avantages, car elle permet aux développeurs de se concentrer sur la création de la logique d'application et des expériences utilisateur, tandis que la plateforme prend en charge la gestion des données sous-jacentes, la mise à l'échelle et l'optimisation des performances.
L'intégration des techniques de stockage de données dans les plateformes no-code permet un développement rapide des applications, car les développeurs peuvent exploiter les capacités de stockage intégrées sans avoir besoin d'une configuration ou d'un codage manuel extensif. Les entreprises peuvent ainsi bénéficier d'un processus de développement d'applications plus rentable et plus efficace, les développeurs pouvant consacrer plus de temps et de ressources à des activités à valeur ajoutée, telles que la conception d'expériences utilisateur innovantes et l'affinement des processus d'entreprise.
En outre, l'intégration du partage des données dans les plateformes no-code garantit que les applications peuvent être conçues en tenant compte de l'évolutivité dès le départ. En s'appuyant sur des stratégies de partage des données, les applications no-code peuvent s'adapter en douceur à la croissance des volumes de données et des bases d'utilisateurs sans rencontrer de goulots d'étranglement au niveau des performances ou de problèmes de stabilité. Cette fonctionnalité est particulièrement précieuse pour les entreprises modernes qui attendent de leurs applications qu'elles s'adaptent et évoluent en fonction de leurs besoins commerciaux.
Étude de cas : Mise en œuvre du sharding de données dans AppMaster
AppMaster est une plateforme no-code de premier plan qui combine une interface moderne et intuitive avec de puissantes capacités de génération d'applications dorsales, web et mobiles. Reconnaissant l'importance du partage des données dans le développement d'applications évolutives et performantes, AppMaster intègre une stratégie de partage des données pour permettre aux développeurs d'implémenter facilement le partitionnement et l'optimisation des données dans leurs applications.
Grâce aux capacités de partage des données offertes par AppMaster, les développeurs peuvent créer des applications qui répartissent automatiquement les données entre plusieurs instances ou serveurs, garantissant ainsi l'évolutivité et la performance des applications, même en cas de charges de travail élevées et de grandes quantités de données.

En tirant parti des fonctions de partage des données de AppMaster, les entreprises peuvent gagner du temps et de l'argent dans le processus de développement, car les développeurs n'ont plus besoin de consacrer des efforts considérables à la configuration et à la gestion des tâches de placement, de rééquilibrage et de maintenance des disques durs. Au lieu de cela, ils peuvent se concentrer sur la création de solutions innovantes et centrées sur le client, tout en s'assurant que leurs applications sont conçues pour gérer des systèmes à grande échelle et des exigences de haute performance.
La répartition des données est essentielle à la gestion des systèmes à grande échelle et est devenue un composant essentiel des applications modernes. "L' innovation est la création du nouveau ou la réorganisation de l'ancien d'une nouvelle manière", comme le dit si bien Mike Vance. En comprenant les différentes stratégies et techniques de sharding et en tirant parti de la puissance d'innovation des plateformes no-code telles que AppMaster, les développeurs peuvent créer des applications évolutives et très performantes qui conservent leur réactivité et leur efficacité, même lorsqu'elles se développent et évoluent au fil du temps.






