Разделение данных - это технология разделения и распределения данных между несколькими серверами или экземплярами, часто используемая в крупномасштабных системах для повышения производительности, масштабируемости и управляемости. Концепция разделения данных берет свое начало в горизонтальном разделении, когда одна таблица разбивается на более мелкие разделы, каждый из которых содержит подмножество данных исходной таблицы.
Разделение данных предполагает разделение данных в большой системе на несколько более мелких сущностей, или "осколков". Каждый из них работает независимо, что позволяет системе обрабатывать запросы одновременно и эффективно, а также обеспечивает отказоустойчивость и доступность. Шардинг особенно полезен в распределенных системах и высокопроизводительных приложениях, где объемы данных и частота запросов пользователей могут быть весьма значительными. Распределение нагрузки на обработку данных между несколькими шардами позволяет эффективно управлять ограниченными физическими аппаратными ресурсами, сокращать время отклика на запросы и повышать производительность.
Источник изображения: DigitalOcean
Преимущества шардирования данных в крупномасштабных системах
Реализация шардинга данных в крупномасштабных системах дает множество преимуществ, которые позволяют повысить производительность и масштабируемость современных приложений. Вот некоторые из этих преимуществ:
- Улучшенная масштабируемость: Одним из основных преимуществ разделения данных является его способность повышать масштабируемость приложения. Распределяя данные и рабочую нагрузку по нескольким серверам, разработчики могут преодолеть трудности, связанные с увеличением объемов данных и запросов пользователей. Это позволяет масштабировать систему по мере необходимости, а не наращивать ресурсы одного сервера.
- Повышенная производительность: Данные делятся на более мелкие фрагменты и распределяются по нескольким хранилищам, поэтому рабочая нагрузка по обработке распределяется между различными серверами. Это обеспечивает одновременную обработку данных и снижение нагрузки на отдельный ресурс, что повышает производительность системы.
- Более быстрая обработка запросов: Разделение данных может заметно ускорить обработку запросов, особенно в системах с интенсивными операциями чтения и записи. Благодаря распределению данных по нескольким хранилищам запрос может быть обработан только в соответствующем хранилище, что позволяет избежать необходимости сканирования большого монолитного набора данных. Это приводит к сокращению времени отклика на запросы пользователей и снижению задержек.
- Повышенная доступность и отказоустойчивость: Распределение данных по нескольким серверам или экземплярам позволяет гарантировать, что приложение будет оставаться доступным и отзывчивым даже при сбоях или перебоях в работе отдельных хранилищ. Это, в свою очередь, делает систему более отказоустойчивой и невосприимчивой к простоям, вызванным единичными точками отказа.
- Эффективное использование ресурсов: Шардинг позволяет более эффективно и сбалансированно использовать системные ресурсы, а не концентрировать вычислительную нагрузку на одном сервере. Такое эффективное использование ресурсов позволяет повысить степень параллелизма, что часто приводит к улучшению производительности и увеличению пропускной способности.
Проблемы, связанные с разделением данных
Несмотря на то что разделение данных дает значительные преимущества для крупномасштабных систем и высокопроизводительных приложений, оно имеет и свои проблемы. Реализация стратегии разделения данных требует тщательного планирования и учета различных факторов, таких как архитектура системы, модели доступа к данным и требования приложения. Среди проблем, с которыми сталкиваются разработчики при использовании разделения данных, можно выделить следующие:
Определение оптимальной стратегии шардинга
Выбор оптимальной стратегии разделения данных может оказаться сложной задачей, требующей глубокого понимания модели данных системы и моделей доступа к ним. Выбор неподходящей стратегии может привести к неэффективному использованию ресурсов, несбалансированному распределению рабочей нагрузки или сложному управлению данными. Прежде чем определить оптимальную стратегию разделения данных в системе, необходимо тщательно проанализировать модели доступа к данным, прогнозы роста и технические требования.
Управление сложностью распределенных систем
Важнейшей проблемой шардинга является управление повышенной сложностью архитектуры распределенных систем. Разработчики должны решать вопросы согласованности и целостности данных на всех шардах, возможности восстановления в случае сбоев и оптимизации производительности при выполнении запросов в масштабе всей системы. Для эффективного управления сложной архитектурой распределенных систем необходимо иметь соответствующий инструментарий, механизмы мониторинга и резервного копирования.
Обеспечение согласованности и целостности данных
Одной из основных проблем при внедрении шардирования данных является обеспечение согласованности и целостности данных на всех шардах. Поскольку данные распределены по нескольким серверам, поддержание их целостности может оказаться затруднительным, особенно если система требует атомарных транзакций, охватывающих несколько шардов. Разработчикам приходится применять такие методы, как распределенные транзакции, конечная согласованность или другие стратегии для поддержания согласованности данных на всех хранилищах.
Несмотря на эти трудности, преимущества разделения данных весьма значительны, особенно для крупномасштабных систем и высокопроизводительных приложений. При тщательном планировании, выборе стратегии и создании мощной системы разработчики могут успешно внедрить шардинг данных и раскрыть его потенциал для повышения масштабируемости и производительности.
Стратегии и методы шардинга
Разделение данных - важнейший компонент построения масштабируемых и высокопроизводительных приложений. Понимание различных стратегий и методов шардинга позволит вам выбрать наиболее подходящий подход для решения конкретных задач. В данном разделе рассматриваются три распространенные стратегии разделения данных: разделение на основе диапазонов, хеширование и разделение на основе каталогов.
Разделение на основе диапазона
Разделение на основе диапазона предполагает разделение данных на основе определенного диапазона значений для заданного ключа. Для разработчика это может быть простой концепцией для понимания и реализации. Например, можно разделить записи о клиентах на основе диапазона их идентификаторов (например, идентификаторы клиентов 1-1000 в шаре A, 1001-2000 в шаре B и т.д.). Такой метод обеспечивает равномерное распределение данных по хранилищам и возможность их легкого запроса по диапазону ключей.
Однако чередование на основе диапазонов имеет ряд недостатков. Одним из них является возможность неравномерного распределения данных при перекосе выбранного ключа. Такая ситуация может привести к возникновению "горячих точек" и узких мест в производительности, поскольку одни шарды могут быть перегружены, а другие остаются недозагруженными. Выбор ключа шарда с равномерным распределением очень важен для решения этой проблемы.
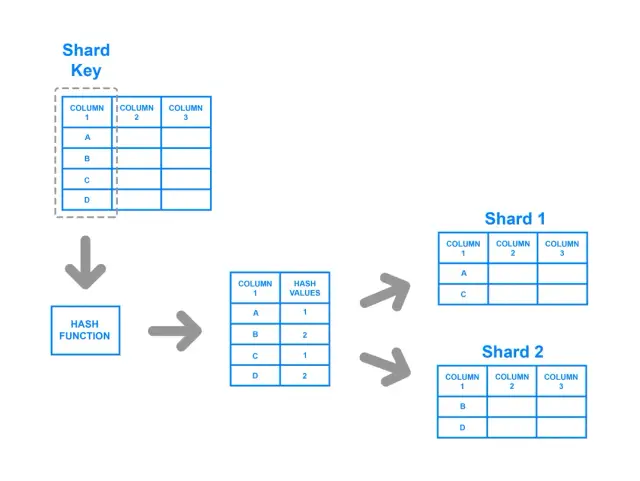
Разделение на основе хэша
Разделение на основе хэша предполагает применение хэш-функции к ключу шарда, по полученному хэшу определяется, к какому шарду относятся данные. Такая стратегия обеспечивает более равномерное распределение данных по хранилищам, поскольку хэш-функция предназначена для получения сбалансированного результата независимо от входных значений. При таком подходе пара ключ-значение подвергается хешированию, и результат хеш-функции определяет, на какой шард направлены данные.
Несмотря на свои преимущества в достижении сбалансированного распределения, хеширование имеет и потенциальные недостатки. Например, с помощью этого метода сложно реализовать запросы на диапазон, поскольку в процессе хеширования теряются связи между исходными ключами. Кроме того, при изменении количества хранилищ большинство хэш-методов требуют перегенерирования и перераспределения значительного объема данных, что может потребовать больших затрат ресурсов и времени.
Разделение на основе каталогов
При разделении на основе каталогов используется отдельная таблица поиска или служба для отслеживания того, в каком шарде хранятся данные по заданному ключу. При записи данных в систему служба каталогов определяет соответствующий шард и возвращает его местоположение приложению. Такой метод позволяет приложению эффективно выполнять запросы как по ключу, так и по диапазону.
Тем не менее, разделение по каталогам имеет свои сложности, например, управление отдельной службой каталогов, которая может стать единой точкой отказа или узким местом в производительности. Поэтому при использовании данного подхода необходимо обеспечить надежность и масштабируемость службы каталогов.
No-Code платформы для шардинга данных
Платформы no-code, такие как AppMaster, позволяют предприятиям быстрее создавать, развертывать и масштабировать приложения, абстрагируясь от сложностей в процессе разработки. Реализация шардинга данных в платформах no-code может еще больше повысить их преимущества, поскольку позволяет разработчикам сосредоточиться на создании логики приложения и пользовательского опыта, а платформа берет на себя управление данными, масштабирование и оптимизацию производительности.
Интеграция методов разделения данных в платформы no-code обеспечивает быструю разработку приложений, поскольку разработчики могут использовать встроенные возможности разделения данных, не прибегая к длительной ручной настройке или кодированию. В результате бизнес получает выгоду от более экономичного и эффективного процесса разработки приложений, поскольку разработчики могут уделять больше времени и ресурсов таким видам деятельности, как создание инновационных пользовательских интерфейсов и совершенствование бизнес-процессов.
Кроме того, использование шардинга данных в платформах no-code позволяет создавать приложения с учетом масштабируемости с самого начала. Благодаря использованию стратегий шардинга данных приложения на no-code могут плавно увеличивать объемы данных и базы пользователей, не испытывая при этом проблем с производительностью и стабильностью. Эта возможность особенно ценна для современных предприятий, которые рассчитывают на то, что их приложения будут адаптироваться и масштабироваться в соответствии с меняющимися потребностями бизнеса.
Пример из практики: Реализация шардинга данных в AppMaster
AppMaster - это ведущая no-code платформа, сочетающая в себе современный интуитивно понятный интерфейс с мощными возможностями создания бэкенда, веб-приложений и мобильных приложений. Понимая важность шардинга данных для разработки масштабируемых и высокопроизводительных приложений, AppMaster интегрирует встроенную стратегию шардинга, позволяющую разработчикам легко реализовать разделение и оптимизацию данных в своих приложениях.
Благодаря возможностям разделения данных, предлагаемым AppMaster, разработчики могут создавать приложения, которые автоматически распределяют данные между несколькими экземплярами или серверами, обеспечивая высокую масштабируемость и производительность приложений даже при высоких рабочих нагрузках и больших объемах данных.

Использование возможностей AppMaster по разделению данных позволяет компаниям сэкономить время и деньги в процессе разработки, поскольку разработчикам больше не нужно тратить значительные усилия на настройку и управление размещением, перебалансировкой и обслуживанием разделов. Вместо этого они могут сосредоточиться на создании инновационных решений, ориентированных на клиента, и гарантировать, что их приложения созданы для работы с крупномасштабными системами и высокопроизводительными требованиями.
Разделение данных играет важную роль в управлении крупномасштабными системами и стало неотъемлемым компонентом современных приложений. " Инновации - это создание нового или перестройка старого на новый лад", - так метко выразился Майк Вэнс. Понимая различные стратегии и методы шардинга и используя инновационные возможности платформ no-code, таких как AppMaster, разработчики могут создавать масштабируемые, высокопроизводительные приложения, которые сохраняют свою отзывчивость и эффективность даже при росте и эволюции.






