
App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Ontdek de rol van data sharding in grootschalige systemen, de voordelen, uitdagingen en hoe het de prestaties en schaalbaarheid van moderne applicaties kan verbeteren.

Data sharding is een techniek die wordt gebruikt om gegevens te partitioneren en te verdelen over meerdere servers of instanties, vaak gebruikt in grootschalige systemen om de prestaties, schaalbaarheid en beheerbaarheid te verbeteren. Het concept van data sharding vindt zijn oorsprong in horizontale partitionering, waarbij een enkele tabel wordt opgesplitst in kleinere partities, die elk een subset van de gegevens van de oorspronkelijke tabel bevatten.
Bij datasharding worden de gegevens binnen een groter systeem verdeeld over meerdere kleinere entiteiten, of "shards". Elke shard werkt onafhankelijk, waardoor het systeem gelijktijdig en efficiënt verzoeken kan verwerken, terwijl het ook fouttolerantie biedt en de beschikbaarheid garandeert. Sharding is vooral nuttig in gedistribueerde systemen en applicaties met hoge prestaties, waar gegevensvolumes en gebruikersverzoeken vrij groot kunnen zijn. Door de verwerkingslast over meerdere shards te verdelen, kan een systeem de beperkingen van fysieke hardwarebronnen effectief beheren, de reactietijden van query's verlagen en de prestaties verbeteren.
Afbeeldingsbron: DigitalOcean
Het implementeren van data sharding in grootschalige systemen biedt talloze voordelen die de prestaties en schaalbaarheid van moderne applicaties kunnen verbeteren. Enkele van deze voordelen zijn
Hoewel datasharding aanzienlijke voordelen biedt voor grootschalige systemen en toepassingen met hoge prestaties, kent het ook uitdagingen. Het implementeren van een shardingstrategie vereist zorgvuldige planning en overweging, waarbij verschillende factoren zoals systeemarchitectuur, gegevenstoegangspatronen en applicatievereisten in overweging moeten worden genomen. Enkele uitdagingen waar ontwikkelaars mee te maken krijgen als ze data sharding toepassen:
Het kiezen van een geschikte shardingstrategie kan complex zijn en vereist een grondig begrip van het datamodel en de toegangspatronen van het systeem. Het kiezen van een ongeschikte strategie kan leiden tot inefficiënt resourcegebruik, onevenwichtige werklastverdeling of gecompliceerd gegevensbeheer. Zorgvuldige analyse van gegevenstoegangspatronen, groeiverwachtingen en technische vereisten is noodzakelijk voordat de beste shardingstrategie voor het systeem wordt bepaald.
Een belangrijke uitdaging van sharding is het beheren van de toegenomen complexiteit van gedistribueerde systeemarchitecturen. Ontwikkelaars moeten zich bezighouden met de consistentie en integriteit van gegevens tussen shards, herstelbaarheid in geval van storingen en prestatieoptimalisatie voor queries over het hele systeem. Het is essentieel om de juiste tooling, monitoring en back-up mechanismen te hebben om de toegevoegde complexiteit van sharded systemen effectief te beheren.
Een van de grootste uitdagingen bij het implementeren van datasharding is het waarborgen van dataconsistentie en -integriteit tussen shards. Aangezien gegevens verspreid zijn over meerdere servers, kan het moeilijk worden om de consistentie te handhaven, vooral als het systeem atomaire transacties vereist die meerdere shards overspannen. Ontwikkelaars moeten technieken gebruiken zoals gedistribueerde transacties, eventuele consistentie of andere strategieën om de dataconsistentie tussen shards te handhaven.
Ondanks deze uitdagingen zijn de voordelen van data sharding aanzienlijk, vooral voor grootschalige systemen en applicaties met hoge prestaties. Met zorgvuldige planning, strategiekeuze en een krachtig systeemontwerp kunnen ontwikkelaars dataharding met succes implementeren en het potentieel voor verbeterde schaalbaarheid en prestaties ontsluiten.
Data sharding is een cruciaal onderdeel bij het bouwen van schaalbare en krachtige applicaties. Als je de verschillende shardingstrategieën en -technieken begrijpt, kun je de meest geschikte aanpak voor je specifieke vereisten kiezen. In deze sectie worden drie veelgebruikte shardingstrategieën besproken: range-based, hash-based en directory-based sharding.
Range-based sharding houdt in dat gegevens worden gepartitioneerd op basis van een specifiek bereik van waarden voor een bepaalde sleutel. Dit kan een eenvoudig concept zijn voor de ontwikkelaar om te begrijpen en te implementeren. Je zou bijvoorbeeld klantrecords kunnen sharden op basis van het bereik van de klant-ID (bijv. klant-ID's 1-1000 op shard A, 1001-2000 op shard B, enzovoort). Deze methode zorgt ervoor dat de gegevens gelijkmatig worden verdeeld over de shards en gemakkelijk kunnen worden opgevraagd op basis van het sleutelbereik.
Maar sharding op basis van bereik heeft enkele nadelen. Eén daarvan is de mogelijkheid van ongelijke gegevensverdeling als de gekozen sleutel scheef is. Deze situatie kan leiden tot hotspots en prestatieproblemen, omdat sommige shards overbelast kunnen raken, terwijl andere onderbenut blijven. Het kiezen van een shard sleutel met een uniforme verdeling is essentieel om dit probleem tegen te gaan.
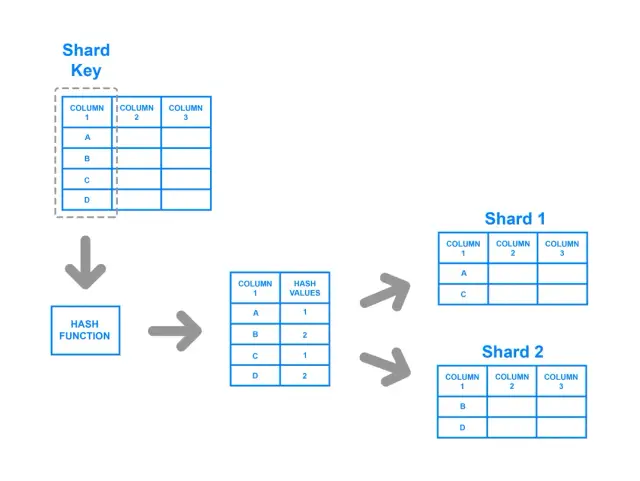
Bij sharding op basis van hash wordt een hash-functie toegepast op de shard-sleutel, waarbij de resulterende hash bepaalt bij welke shard de gegevens horen. Deze strategie zorgt voor een meer uniforme verdeling van gegevens over de shards, omdat de hashfunctie is ontworpen om een gebalanceerde uitvoer te geven ongeacht de invoerwaarden. In deze aanpak wordt een sleutelwaardepaar gehasht en het resultaat van de hashfunctie bepaalt naar welke shard de gegevens gaan.
Ondanks de sterke punten in het bereiken van een gebalanceerde verdeling, heeft sharding op basis van hash potentiële nadelen. Het kan bijvoorbeeld een uitdaging zijn om bereikqueries te implementeren met deze methode, omdat de relaties tussen de originele sleutels verloren gaan in het hashproces. Bovendien, wanneer het aantal shards verandert, vereisen de meeste hash-gebaseerde methodes een aanzienlijke hoeveelheid data die opnieuw gehasht en verdeeld moet worden, wat veel middelen en tijd kan kosten.
Directory-based sharding gebruikt een aparte opzoektabel of service om bij te houden welke shard gegevens voor een bepaalde sleutel bevat. Wanneer gegevens naar het systeem worden geschreven, bepaalt de directoryservice de juiste shard en stuurt de locatie terug naar de applicatie. Deze methode stelt de applicatie in staat om zowel sleutelgebaseerde als bereikqueries efficiënt uit te voeren.
Toch heeft directory-gebaseerde sharding zijn uitdagingen, zoals het beheren van een aparte directoryservice die een single point of failure of een prestatiebottleneck kan worden. Daarom is het essentieel om de betrouwbaarheid en schaalbaarheid van de directoryservice te garanderen bij het gebruik van deze aanpak.
No-code platforms zoals AppMaster stellen bedrijven in staat om applicaties sneller te bouwen, te implementeren en te schalen door de complexiteit weg te halen uit het ontwikkelproces. Het implementeren van data sharding in no-code platformen kan hun voordelen verder vergroten, omdat het ontwikkelaars in staat stelt zich te concentreren op het creëren van applicatielogica en gebruikerservaringen, terwijl het platform het onderliggende databeheer, het schalen en de prestatieoptimalisatie voor zijn rekening neemt.
Door data sharding technieken te integreren in no-code platforms kunnen applicaties snel ontwikkeld worden, omdat ontwikkelaars gebruik kunnen maken van de ingebouwde sharding mogelijkheden zonder uitgebreide handmatige configuratie of codering. Als gevolg hiervan kunnen bedrijven profiteren van een kosteneffectiever en efficiënter applicatieontwikkelingsproces, omdat ontwikkelaars meer tijd en middelen kunnen besteden aan activiteiten die waarde toevoegen, zoals het ontwerpen van innovatieve gebruikerservaringen en het verfijnen van bedrijfsprocessen.
Bovendien zorgt de integratie van datasharding in no-code platformen ervoor dat applicaties vanaf het begin kunnen worden gebouwd met het oog op schaalbaarheid. Door gebruik te maken van datashardingstrategieën kunnen no-code toepassingen de groei van datavolumes en gebruikersbestanden probleemloos verwerken zonder prestatieproblemen of stabiliteitsproblemen. Deze functie is vooral waardevol voor moderne ondernemingen die verwachten dat hun applicaties zich aanpassen aan de veranderende bedrijfsbehoeften.
AppMaster is een toonaangevend no-code platform dat een moderne, intuïtieve interface combineert met krachtige mogelijkheden voor het genereren van backend-, web- en mobiele applicaties. AppMaster erkent het belang van data sharding bij het ontwikkelen van schaalbare en krachtige applicaties en integreert daarom een ingebouwde sharding strategie zodat ontwikkelaars eenvoudig data partitionering en optimalisatie in hun applicaties kunnen implementeren.
Met de mogelijkheden voor datasharing die AppMaster biedt, kunnen ontwikkelaars toepassingen maken die automatisch gegevens verdelen over meerdere instanties of servers, zodat de toepassingen zeer schaalbaar zijn en goed presteren, zelfs bij een hoge werkbelasting en grote hoeveelheden gegevens.
Door gebruik te maken van AppMaster kunnen bedrijven zowel tijd als geld besparen in het ontwikkelproces, omdat ontwikkelaars niet langer veel tijd hoeven te besteden aan het configureren en beheren van shard placement, rebalancing en onderhoudstaken. In plaats daarvan kunnen ze zich richten op het maken van innovatieve, klantgerichte oplossingen terwijl ze er zeker van zijn dat hun applicaties gebouwd zijn om grootschalige systemen en hoge prestatie-eisen aan te kunnen.
Data sharding is cruciaal bij het beheren van grootschalige systemen en is een essentieel onderdeel geworden van moderne applicaties. "Innovatie is het creëren van het nieuwe of het herschikken van het oude op een nieuwe manier", zoals Mike Vance het treffend verwoordde. Door de verschillende shardingstrategieën en -technieken te begrijpen en gebruik te maken van de innovatieve kracht van no-code platforms zoals AppMaster, kunnen ontwikkelaars schaalbare, krachtige applicaties maken die hun reactiesnelheid en efficiëntie behouden, zelfs als ze in de loop van de tijd groeien en evolueren.
Data sharding is een strategie die wordt gebruikt in grootschalige systemen om gegevens te verdelen over meerdere servers of instanties om de prestaties, schaalbaarheid en beheerbaarheid te verbeteren.
Data sharding helpt bij het beheren van de beperkingen van fysieke hardwarebronnen, het verlagen van de responstijden van query's en het verbeteren van de algehele prestaties en schaalbaarheid van moderne applicaties.
Uitdagingen zijn onder andere het bepalen van een geschikte shardingstrategie, het beheren van de complexiteit van gedistribueerde systemen en het waarborgen van de consistentie en integriteit van gegevens tussen shards.
Veelgebruikte shardingstrategieën zijn range-based sharding, hash-based sharding en directory-based sharding.
AppMaster maakt gebruik van een no-code platform met een ingebouwde shardingstrategie om zeer schaalbare en krachtige applicaties te maken, waardoor ontwikkelaars zich kunnen richten op de applicatielogica in plaats van op de complexiteit van het sharden van gegevens.
Ja, data sharding kan worden geïmplementeerd in no-code platforms, waardoor applicaties snel kunnen worden ontwikkeld en geschaald zonder dat uitgebreide handmatige configuratie of codering nodig is.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


