



Equipment reservation app: prevent conflicts and track returns
Plan an equipment reservation app that prevents double bookings, records returns and damage, and places faulty items on maintenance hold.
Explore the role of data sharding in large scale systems, its benefits, challenges, and how it can improve the performance and scalability of modern applications.

Data sharding is a technique used to partition and distribute data across multiple servers or instances, often employed in large-scale systems to improve performance, scalability, and manageability. The concept of data sharding originates in horizontal partitioning, where a single table is split into smaller partitions, each containing a subset of the original table's data.
Data sharding involves dividing the data within a larger system among multiple smaller entities, or "shards". Each shard operates independently, enabling the system to process requests concurrently and efficiently while also providing fault tolerance and ensuring availability. Sharding is especially helpful in distributed systems and high-performance applications, where data volumes and user request rates can be quite large. By spreading the processing workload across multiple shards, a system can effectively manage the limitations of physical hardware resources, decrease query response times, and boost performance.
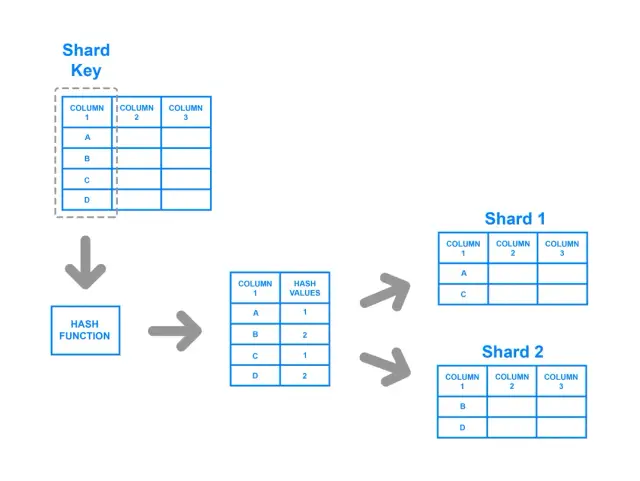
Image source: DigitalOcean
Implementing data sharding in large-scale systems offers numerous benefits that can improve the performance and scalability of modern applications. Some of these benefits include:
While data sharding provides significant benefits for large-scale systems and high-performance applications, it has challenges. Implementing a sharding strategy requires careful planning and consideration, considering various factors such as system architecture, data access patterns, and application requirements. Some challenges developers tend to face when employing data sharding include:
Choosing an appropriate sharding strategy can be complex, requiring a deep understanding of the system's data model and access patterns. Selecting an unsuitable strategy can lead to inefficient resource usage, imbalanced workload distribution, or complicated data management. Careful analysis of data access patterns, growth projections, and technical requirements is necessary before determining the best sharding strategy for the system.
A critical challenge of sharding is managing the increased complexity of distributed system architectures. Developers must address data consistency and integrity across shards, recoverability in case of failures, and performance optimization for system-wide queries. It is essential to have proper tooling, monitoring, and backup mechanisms in place to effectively manage the added complexity of sharded systems.
One of the major challenges in implementing data sharding is ensuring data consistency and integrity across shards. Since data is spread across multiple servers, maintaining consistency can become difficult, especially when the system requires atomic transactions spanning multiple shards. Developers need to adopt techniques such as distributed transactions, eventual consistency, or other strategies to maintain data consistency across shards.
Despite these challenges, the benefits of data sharding are significant, especially for large-scale systems and high-performance applications. With careful planning, strategy selection, and powerful system design, developers can successfully implement data sharding and unlock its potential for improved scalability and performance.
Data sharding is a critical component in building scalable and high-performance applications. Understanding the different sharding strategies and techniques will enable you to choose the most suitable approach for your specific requirements. This section will explore three common sharding strategies: range-based, hash-based, and directory-based sharding.
Range-based sharding involves partitioning data based on a specific range of values for a given key. This can be a simple concept for the developer to understand and implement. For example, you could shard customer records based on the customer ID range (e.g., customer IDs 1-1000 on shard A, 1001-2000 on shard B, and so on). This method ensures that the data is evenly distributed across the shards and can be queried easily by the key range.
But range-based sharding has some drawbacks. One of them is the potential for uneven data distribution if the chosen key is skewed. This situation can lead to hotspots and performance bottlenecks, as some shards may become overloaded, while others remain underutilized. Choosing a shard key with a uniform distribution is essential to counteract this issue.
Hash-based sharding involves applying a hash function to the shard key, with the resulting hash determining which shard the data belongs to. This strategy ensures a more uniform distribution of data across the shards, as the hash function is designed to give a balanced output regardless of the input values. In this approach, a key-value pair is hashed, and the result of the hash function determines the shard to which the data is directed.
Despite its strengths in achieving a balanced distribution, hash-based sharding has potential drawbacks. For example, it can be challenging to implement range queries with this method, as the relationships between the original keys are lost in the hashing process. Moreover, when the number of shards changes, most hash-based methods require a substantial amount of data to be rehashed and redistributed, which could be resource-intensive and time-consuming.
Directory-based sharding uses a separate lookup table or service to track which shard holds data for a given key. When data is written to the system, the directory service determines the appropriate shard, returning its location to the application. This method enables the application to perform both key-based and range queries efficiently.
Still, directory-based sharding has its challenges, such as managing a separate directory service that could become a single point of failure or a performance bottleneck. Therefore, it is essential to ensure the reliability and scalability of the directory service when using this approach.
No-code platforms like AppMaster empower businesses to build, deploy, and scale applications faster by abstracting complexity away from the development process. Implementing data sharding in no-code platforms can further enhance their benefits, as it allows developers to focus on creating application logic and user experiences, while the platform handles the underlying data management, scaling, and performance optimization.
Integrating data sharding techniques in no-code platforms enables rapid application development, as developers can leverage the built-in sharding capabilities without requiring extensive manual configuration or coding. As a result, businesses can benefit from a more cost-effective and efficient application development process, as developers can devote more time and resources to value-adding activities, such as designing innovative user experiences and refining business processes.
Moreover, including data sharding in no-code platforms ensures that applications can be built with scalability in mind from the ground up. By leveraging data sharding strategies, no-code applications can smoothly accommodate the growth of data volumes and user bases without experiencing performance bottlenecks or stability issues. This feature is especially valuable for modern enterprises that expect their applications to adapt and scale with their evolving business needs.
AppMaster is a leading no-code platform that combines a modern, intuitive interface with powerful backend, web, and mobile application generation capabilities. Recognizing the importance of data sharding in developing scalable and high-performance applications, AppMaster integrates a built-in sharding strategy to enable developers to implement data partitioning and optimization in their applications easily.
With the data sharding capabilities offered by AppMaster, developers can create applications that automatically distribute data across multiple instances or servers, ensuring that the applications are highly scalable and performant, even under high workloads and large amounts of data.
By leveraging AppMaster's data sharding features, businesses can save both time and money in the development process, as developers no longer need to spend considerable effort configuring and managing shard placement, rebalancing, and maintenance tasks. Instead, they can focus on creating innovative, customer-centric solutions while ensuring their applications are built to handle large scale systems and high-performance requirements.
Data sharding is critical in managing large scale systems and has become an essential component of modern applications. "Innovation is the creation of the new or the re-arranging of the old in a new way," as aptly phrased by Mike Vance. By understanding the various sharding strategies and techniques and leveraging the innovative power of no-code platforms such as AppMaster, developers can create scalable, high-performance applications that maintain their responsiveness and efficiency, even as they grow and evolve over time.
Data sharding is a strategy used in large scale systems to partition data across multiple servers or instances to improve performance, scalability, and manageability.
Data sharding helps manage the limitations of physical hardware resources, decrease query response times, and improve the overall performance and scalability of modern applications.
Challenges include determining an appropriate sharding strategy, managing the complexity of distributed systems, and ensuring data consistency and integrity across shards.
Common sharding strategies include range-based sharding, hash-based sharding, and directory-based sharding.
AppMaster leverages a no-code platform with a built-in sharding strategy to create highly scalable and high-performance applications, allowing developers to focus on application logic rather than the complexities of data sharding.
Yes, data sharding can be implemented in no-code platforms, enabling rapid application development and scaling of applications without requiring extensive manual configuration or coding.
Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


