
Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Khám phá vai trò của phân đoạn dữ liệu trong các hệ thống quy mô lớn, lợi ích, thách thức của nó và cách nó có thể cải thiện hiệu suất và khả năng mở rộng của các ứng dụng hiện đại.

Data sharding là một kỹ thuật được sử dụng để phân vùng và phân phối dữ liệu trên nhiều máy chủ hoặc phiên bản, thường được sử dụng trong các hệ thống quy mô lớn để cải thiện hiệu suất, khả năng mở rộng và khả năng quản lý. Khái niệm phân mảnh dữ liệu bắt nguồn từ phân vùng ngang, trong đó một bảng được chia thành các phân vùng nhỏ hơn, mỗi phân vùng chứa một tập hợp con dữ liệu của bảng gốc.
Phân đoạn dữ liệu liên quan đến việc phân chia dữ liệu trong một hệ thống lớn hơn cho nhiều thực thể nhỏ hơn hoặc "phân đoạn". Mỗi phân đoạn hoạt động độc lập, cho phép hệ thống xử lý các yêu cầu đồng thời và hiệu quả đồng thời cung cấp khả năng chịu lỗi và đảm bảo tính khả dụng. Sharding đặc biệt hữu ích trong các hệ thống phân tán và ứng dụng hiệu suất cao, nơi khối lượng dữ liệu và tỷ lệ yêu cầu của người dùng có thể khá lớn. Bằng cách trải rộng khối lượng công việc xử lý trên nhiều phân đoạn, một hệ thống có thể quản lý hiệu quả các giới hạn của tài nguyên phần cứng vật lý, giảm thời gian phản hồi truy vấn và tăng hiệu suất.
Nguồn hình ảnh: DigitalOcean
Việc triển khai bảo vệ dữ liệu trong các hệ thống quy mô lớn mang lại nhiều lợi ích có thể cải thiện hiệu suất và khả năng mở rộng của các ứng dụng hiện đại. Một số lợi ích này bao gồm:
Mặc dù bảo vệ dữ liệu mang lại lợi ích đáng kể cho các hệ thống quy mô lớn và ứng dụng hiệu suất cao, nhưng nó cũng có những thách thức. Việc triển khai chiến lược sharding yêu cầu lập kế hoạch và cân nhắc cẩn thận, xem xét các yếu tố khác nhau như kiến trúc hệ thống, mẫu truy cập dữ liệu và yêu cầu ứng dụng. Một số thách thức mà các nhà phát triển có xu hướng gặp phải khi sử dụng phân đoạn dữ liệu bao gồm:
Việc chọn một chiến lược phân đoạn thích hợp có thể phức tạp, đòi hỏi sự hiểu biết sâu sắc về mô hình dữ liệu của hệ thống và các mẫu truy cập. Chọn một chiến lược không phù hợp có thể dẫn đến việc sử dụng tài nguyên không hiệu quả, phân bổ khối lượng công việc không cân bằng hoặc quản lý dữ liệu phức tạp. Phân tích cẩn thận các mẫu truy cập dữ liệu, dự báo tăng trưởng và yêu cầu kỹ thuật là cần thiết trước khi xác định chiến lược bảo vệ tốt nhất cho hệ thống.
Một thách thức quan trọng của sharding là quản lý sự phức tạp ngày càng tăng của kiến trúc hệ thống phân tán. Các nhà phát triển phải giải quyết tính nhất quán và toàn vẹn của dữ liệu trên các phân đoạn, khả năng khôi phục trong trường hợp lỗi và tối ưu hóa hiệu suất cho các truy vấn trên toàn hệ thống. Điều cần thiết là phải có sẵn các công cụ, cơ chế giám sát và sao lưu phù hợp để quản lý hiệu quả sự phức tạp gia tăng của các hệ thống phân mảnh.
Một trong những thách thức lớn trong việc triển khai phân đoạn dữ liệu là đảm bảo tính nhất quán và toàn vẹn của dữ liệu giữa các phân đoạn. Vì dữ liệu được trải rộng trên nhiều máy chủ nên việc duy trì tính nhất quán có thể trở nên khó khăn, đặc biệt khi hệ thống yêu cầu các giao dịch nguyên tử trải rộng trên nhiều phân đoạn. Các nhà phát triển cần áp dụng các kỹ thuật như giao dịch phân tán, tính nhất quán cuối cùng hoặc các chiến lược khác để duy trì tính nhất quán của dữ liệu giữa các phân đoạn.
Bất chấp những thách thức này, lợi ích của việc chia nhỏ dữ liệu là rất đáng kể, đặc biệt là đối với các hệ thống quy mô lớn và ứng dụng hiệu suất cao. Với việc lập kế hoạch cẩn thận, lựa chọn chiến lược và thiết kế hệ thống mạnh mẽ, các nhà phát triển có thể triển khai thành công việc bảo vệ dữ liệu và khai thác tiềm năng của nó để cải thiện khả năng mở rộng và hiệu suất.
Data sharding là một thành phần quan trọng trong việc xây dựng các ứng dụng hiệu suất cao và có thể mở rộng. Hiểu các chiến lược và kỹ thuật phân mảnh khác nhau sẽ cho phép bạn chọn phương pháp phù hợp nhất cho các yêu cầu cụ thể của mình. Phần này sẽ khám phá ba chiến lược phân mảnh phổ biến: phân mảnh dựa trên phạm vi, dựa trên hàm băm và dựa trên thư mục.
Phân đoạn dựa trên phạm vi liên quan đến việc phân vùng dữ liệu dựa trên một phạm vi giá trị cụ thể cho một khóa nhất định. Đây có thể là một khái niệm đơn giản để nhà phát triển hiểu và triển khai. Ví dụ: bạn có thể phân tách hồ sơ khách hàng dựa trên phạm vi ID khách hàng (ví dụ: ID khách hàng 1-1000 trên phân đoạn A, 1001-2000 trên phân đoạn B, v.v.). Phương pháp này đảm bảo rằng dữ liệu được phân bổ đồng đều trên các phân đoạn và có thể được truy vấn dễ dàng theo phạm vi khóa.
Nhưng sharding dựa trên phạm vi có một số nhược điểm. Một trong số đó là khả năng phân phối dữ liệu không đồng đều nếu khóa được chọn bị lệch. Tình trạng này có thể dẫn đến các điểm nóng và tắc nghẽn hiệu suất, vì một số phân đoạn có thể trở nên quá tải, trong khi những phân đoạn khác vẫn chưa được sử dụng đúng mức. Chọn một khóa phân đoạn có phân phối đồng đều là điều cần thiết để giải quyết vấn đề này.
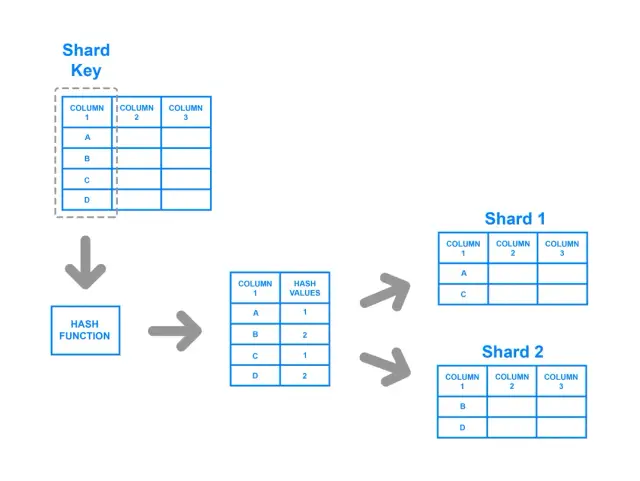
Phân đoạn dựa trên hàm băm liên quan đến việc áp dụng hàm băm cho khóa phân đoạn, với hàm băm kết quả xác định dữ liệu thuộc về phân đoạn nào. Chiến lược này đảm bảo phân phối dữ liệu đồng đều hơn trên các phân đoạn, vì hàm băm được thiết kế để cung cấp đầu ra cân bằng bất kể giá trị đầu vào là gì. Theo cách tiếp cận này, một cặp khóa-giá trị được băm và kết quả của hàm băm xác định phân đoạn mà dữ liệu được hướng đến.
Mặc dù có điểm mạnh trong việc đạt được sự phân phối cân bằng, nhưng phân đoạn dựa trên hàm băm có những nhược điểm tiềm ẩn. Ví dụ: có thể khó thực hiện các truy vấn phạm vi bằng phương pháp này vì mối quan hệ giữa các khóa ban đầu bị mất trong quá trình băm. Ngoài ra, khi số lượng phân đoạn thay đổi, hầu hết các phương pháp dựa trên hàm băm đều yêu cầu một lượng dữ liệu đáng kể được băm lại và phân phối lại, điều này có thể tốn nhiều tài nguyên và thời gian.
Phân đoạn dựa trên thư mục sử dụng một bảng tra cứu hoặc dịch vụ riêng biệt để theo dõi phân đoạn nào chứa dữ liệu cho một khóa nhất định. Khi dữ liệu được ghi vào hệ thống, dịch vụ thư mục sẽ xác định phân đoạn thích hợp, trả lại vị trí của nó cho ứng dụng. Phương pháp này cho phép ứng dụng thực hiện cả truy vấn dựa trên khóa và phạm vi một cách hiệu quả.
Tuy nhiên, sharding dựa trên thư mục có những thách thức của nó, chẳng hạn như việc quản lý một dịch vụ thư mục riêng biệt có thể trở thành một điểm lỗi duy nhất hoặc tắc nghẽn hiệu suất. Do đó, điều cần thiết là đảm bảo độ tin cậy và khả năng mở rộng của dịch vụ thư mục khi sử dụng phương pháp này.
Các nền tảng không cần mã như AppMaster trao quyền cho các doanh nghiệp xây dựng, triển khai và thay đổi quy mô ứng dụng nhanh hơn bằng cách trừu tượng hóa sự phức tạp khỏi quy trình phát triển. Việc triển khai phân đoạn dữ liệu trong các nền tảng no-code có thể nâng cao hơn nữa lợi ích của chúng, vì nó cho phép các nhà phát triển tập trung vào việc tạo logic ứng dụng và trải nghiệm người dùng, trong khi nền tảng xử lý việc quản lý dữ liệu cơ bản, mở rộng quy mô và tối ưu hóa hiệu suất.
Việc tích hợp các kỹ thuật phân tách dữ liệu trong nền tảng no-code cho phép phát triển ứng dụng nhanh chóng , vì các nhà phát triển có thể tận dụng các khả năng phân tách dữ liệu tích hợp sẵn mà không yêu cầu mã hóa hoặc cấu hình thủ công. Do đó, các doanh nghiệp có thể hưởng lợi từ quy trình phát triển ứng dụng hiệu quả và tiết kiệm chi phí hơn, vì các nhà phát triển có thể dành nhiều thời gian và nguồn lực hơn cho các hoạt động gia tăng giá trị, chẳng hạn như thiết kế trải nghiệm người dùng sáng tạo và tinh chỉnh quy trình kinh doanh.
Ngoài ra, việc bao gồm phân đoạn dữ liệu trong các nền tảng no-code đảm bảo rằng các ứng dụng có thể được xây dựng với khả năng mở rộng ngay từ đầu. Bằng cách tận dụng các chiến lược bảo vệ dữ liệu, các ứng dụng no-code có thể đáp ứng dễ dàng sự tăng trưởng của khối lượng dữ liệu và cơ sở người dùng mà không gặp phải các vấn đề về tắc nghẽn hiệu suất hoặc độ ổn định. Tính năng này đặc biệt có giá trị đối với các doanh nghiệp hiện đại mong muốn các ứng dụng của họ thích ứng và mở rộng theo nhu cầu kinh doanh đang phát triển của họ.
AppMaster là nền tảng không mã hàng đầu kết hợp giao diện hiện đại, trực quan với khả năng tạo ứng dụng di động, web và phụ trợ mạnh mẽ. Nhận thức được tầm quan trọng của việc phân tách dữ liệu trong việc phát triển các ứng dụng hiệu năng cao và có thể mở rộng, AppMaster tích hợp một chiến lược phân đoạn dữ liệu tích hợp để cho phép các nhà phát triển thực hiện phân vùng và tối ưu hóa dữ liệu trong các ứng dụng của họ một cách dễ dàng.
Với khả năng phân tách dữ liệu do AppMaster cung cấp, nhà phát triển có thể tạo các ứng dụng tự động phân phối dữ liệu trên nhiều phiên bản hoặc máy chủ, đảm bảo rằng các ứng dụng có khả năng mở rộng và hoạt động hiệu quả, ngay cả khi có khối lượng công việc cao và lượng dữ liệu lớn.
Bằng cách tận dụng các tính năng phân mảnh dữ liệu của AppMaster, các doanh nghiệp có thể tiết kiệm cả thời gian và tiền bạc trong quá trình phát triển , vì các nhà phát triển không còn cần phải tốn nhiều công sức để định cấu hình và quản lý các tác vụ sắp xếp phân đoạn, tái cân bằng và bảo trì. Thay vào đó, họ có thể tập trung vào việc tạo ra các giải pháp sáng tạo, lấy khách hàng làm trung tâm đồng thời đảm bảo các ứng dụng của họ được xây dựng để xử lý các hệ thống quy mô lớn và các yêu cầu về hiệu năng cao.
Data sharding rất quan trọng trong việc quản lý các hệ thống quy mô lớn và đã trở thành một thành phần thiết yếu của các ứng dụng hiện đại. "Đổi mới là việc tạo ra cái mới hoặc sắp xếp lại cái cũ theo một cách mới," như Mike Vance đã diễn đạt một cách khéo léo. Bằng cách hiểu các chiến lược và kỹ thuật phân mảnh khác nhau, đồng thời tận dụng sức mạnh đổi mới của các nền tảng no-code như AppMaster, các nhà phát triển có thể tạo các ứng dụng hiệu suất cao, có thể mở rộng để duy trì khả năng đáp ứng và hiệu quả của chúng, ngay cả khi chúng phát triển và phát triển theo thời gian.
Phân mảnh dữ liệu là một chiến lược được sử dụng trong các hệ thống quy mô lớn để phân vùng dữ liệu trên nhiều máy chủ hoặc phiên bản nhằm cải thiện hiệu suất, khả năng mở rộng và khả năng quản lý.
Data sharding giúp quản lý các giới hạn của tài nguyên phần cứng vật lý, giảm thời gian phản hồi truy vấn và cải thiện hiệu suất tổng thể cũng như khả năng mở rộng của các ứng dụng hiện đại.
Các thách thức bao gồm xác định chiến lược phân đoạn phù hợp, quản lý độ phức tạp của các hệ thống phân tán và đảm bảo tính nhất quán và toàn vẹn của dữ liệu trên các phân đoạn.
Các chiến lược phân đoạn phổ biến bao gồm phân đoạn dựa trên phạm vi, phân đoạn dựa trên hàm băm và phân đoạn dựa trên thư mục.
AppMaster tận dụng một nền tảng no-code với chiến lược sharding tích hợp để tạo ra các ứng dụng hiệu suất cao và có khả năng mở rộng cao, cho phép các nhà phát triển tập trung vào logic ứng dụng hơn là sự phức tạp của việc sharding dữ liệu.
Có, phân đoạn dữ liệu có thể được triển khai trong các nền tảng no-code, cho phép phát triển ứng dụng nhanh chóng và mở rộng quy mô ứng dụng mà không yêu cầu mã hóa hoặc cấu hình thủ công.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


