
Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj rolę shardingu danych w systemach wielkoskalowych, jego zalety, wyzwania i sposób, w jaki może poprawić wydajność i skalowalność nowoczesnych aplikacji.

Data sharding to technika używana do partycjonowania i dystrybucji danych na wielu serwerach lub instancjach, często stosowana w systemach o dużej skali w celu poprawy wydajności, skalowalności i łatwości zarządzania. Koncepcja dzielenia danych wywodzi się z partycjonowania poziomego, w którym pojedyncza tabela jest dzielona na mniejsze partycje, z których każda zawiera podzbiór oryginalnych danych tabeli.
Dzielenie danych polega na dzieleniu danych w ramach większego systemu na wiele mniejszych jednostek lub "odłamków". Każdy shard działa niezależnie, umożliwiając systemowi przetwarzanie żądań współbieżnie i wydajnie, zapewniając jednocześnie odporność na błędy i dostępność. Sharding jest szczególnie pomocny w systemach rozproszonych i aplikacjach o wysokiej wydajności, gdzie wolumeny danych i liczba żądań użytkowników mogą być dość duże. Rozkładając obciążenie przetwarzania na wiele shardów, system może skutecznie zarządzać ograniczeniami fizycznych zasobów sprzętowych, skracać czasy odpowiedzi zapytań i zwiększać wydajność.
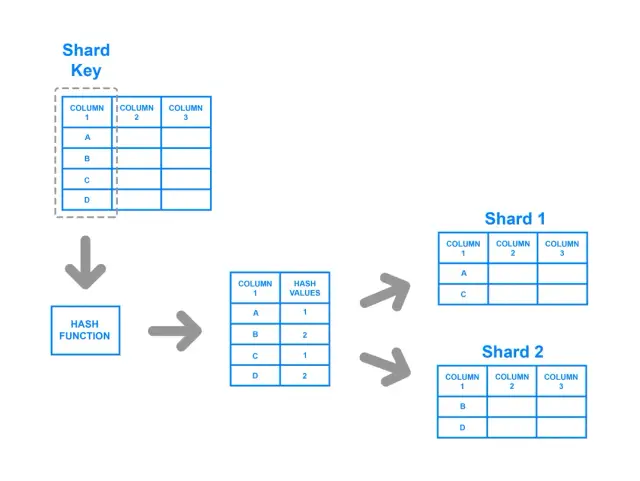
Źródło obrazu: DigitalOcean
Wdrożenie shardingu danych w systemach wielkoskalowych oferuje liczne korzyści, które mogą poprawić wydajność i skalowalność nowoczesnych aplikacji. Niektóre z tych korzyści obejmują
Chociaż dzielenie danych na mniejsze części zapewnia znaczące korzyści dla systemów na dużą skalę i aplikacji o wysokiej wydajności, wiąże się ono z pewnymi wyzwaniami. Wdrożenie strategii shardingu wymaga starannego planowania i rozważenia, biorąc pod uwagę różne czynniki, takie jak architektura systemu, wzorce dostępu do danych i wymagania aplikacji. Niektóre wyzwania, przed którymi stają deweloperzy stosujący sharding danych, są następujące:
Wybór odpowiedniej strategii shardingu może być złożony i wymaga dogłębnego zrozumienia modelu danych systemu i wzorców dostępu. Wybór nieodpowiedniej strategii może prowadzić do nieefektywnego wykorzystania zasobów, niezrównoważonego rozkładu obciążenia lub skomplikowanego zarządzania danymi. Dokładna analiza wzorców dostępu do danych, prognoz wzrostu i wymagań technicznych jest konieczna przed określeniem najlepszej strategii shardingu dla systemu.
Kluczowym wyzwaniem związanym z shardingiem jest zarządzanie zwiększoną złożonością architektur systemów rozproszonych. Deweloperzy muszą zająć się spójnością i integralnością danych we fragmentach, możliwością odzyskiwania danych w przypadku awarii oraz optymalizacją wydajności dla zapytań obejmujących cały system. Niezbędne jest posiadanie odpowiednich narzędzi, mechanizmów monitorowania i tworzenia kopii zapasowych, aby skutecznie zarządzać dodatkową złożonością systemów sharded.
Jednym z głównych wyzwań związanych z wdrażaniem shardingu danych jest zapewnienie spójności i integralności danych pomiędzy shardami. Ponieważ dane są rozproszone na wielu serwerach, utrzymanie spójności może stać się trudne, zwłaszcza gdy system wymaga transakcji atomowych obejmujących wiele odłamków. Deweloperzy muszą przyjąć techniki takie jak transakcje rozproszone, ewentualna spójność lub inne strategie, aby utrzymać spójność danych między odłamkami.
Pomimo tych wyzwań, korzyści płynące z shardingu danych są znaczące, zwłaszcza w przypadku systemów o dużej skali i aplikacji o wysokiej wydajności. Dzięki starannemu planowaniu, doborowi strategii i wydajnemu projektowi systemu, deweloperzy mogą z powodzeniem wdrożyć sharding danych i uwolnić jego potencjał w zakresie poprawy skalowalności i wydajności.
Sharding danych jest kluczowym elementem w budowaniu skalowalnych i wysokowydajnych aplikacji. Zrozumienie różnych strategii i technik shardingu pozwoli ci wybrać najbardziej odpowiednie podejście do konkretnych wymagań. W tej sekcji omówione zostaną trzy popularne strategie dzielenia danych na mniejsze części: sharding oparty na zakresach, sharding oparty na hashach i sharding oparty na katalogach.
Sharding oparty na zakresie obejmuje partycjonowanie danych w oparciu o określony zakres wartości dla danego klucza. Dla dewelopera może to być prosta koncepcja do zrozumienia i wdrożenia. Na przykład, można podzielić rekordy klientów na podstawie zakresu identyfikatorów klientów (np. identyfikatory klientów 1-1000 na shardzie A, 1001-2000 na shardzie B i tak dalej). Metoda ta zapewnia, że dane są równomiernie rozłożone w shardach i mogą być łatwo wyszukiwane według zakresu klucza.
Sharding oparty na zakresie ma jednak pewne wady. Jedną z nich jest możliwość nierównomiernej dystrybucji danych, jeśli wybrany klucz jest przekrzywiony. Taka sytuacja może prowadzić do hotspotów i wąskich gardeł wydajności, ponieważ niektóre shardy mogą zostać przeciążone, podczas gdy inne pozostają niewykorzystane. Wybór klucza shardu o równomiernej dystrybucji jest niezbędny, aby przeciwdziałać temu problemowi.
Sharding oparty na skrócie polega na zastosowaniu funkcji skrótu do klucza shardu, a wynikowy skrót określa, do którego shardu należą dane. Strategia ta zapewnia bardziej równomierną dystrybucję danych w shardach, ponieważ funkcja skrótu jest zaprojektowana tak, aby dawać zrównoważony wynik niezależnie od wartości wejściowych. W tym podejściu para klucz-wartość jest haszowana, a wynik funkcji haszującej określa shard, do którego kierowane są dane.
Pomimo swoich mocnych stron w osiąganiu zrównoważonej dystrybucji, sharding oparty na hashowaniu ma potencjalne wady. Przykładowo, implementacja zapytań zakresowych za pomocą tej metody może być trudna, ponieważ relacje między oryginalnymi kluczami są tracone w procesie haszowania. Co więcej, gdy liczba shardów ulega zmianie, większość metod opartych na hashowaniu wymaga ponownego haszowania i redystrybucji znacznej ilości danych, co może być zasobochłonne i czasochłonne.
Sharding oparty na katalogach wykorzystuje oddzielną tabelę wyszukiwania lub usługę do śledzenia, który shard przechowuje dane dla danego klucza. Gdy dane są zapisywane w systemie, usługa katalogowa określa odpowiedni shard, zwracając jego lokalizację do aplikacji. Metoda ta umożliwia aplikacji wydajne wykonywanie zarówno zapytań opartych na kluczach, jak i zakresach.
Sharding oparty na katalogach ma jednak swoje wyzwania, takie jak zarządzanie oddzielną usługą katalogową, która może stać się pojedynczym punktem awarii lub wąskim gardłem wydajności. W związku z tym konieczne jest zapewnienie niezawodności i skalowalności usługi katalogowej podczas korzystania z tego podejścia.
Platformy bez kodu, takie jak AppMaster, umożliwiają firmom szybsze tworzenie, wdrażanie i skalowanie aplikacji poprzez abstrahowanie złożoności od procesu rozwoju. Wdrożenie shardingu danych na platformach no-code może jeszcze bardziej zwiększyć ich zalety, ponieważ pozwala programistom skupić się na tworzeniu logiki aplikacji i doświadczeń użytkowników, podczas gdy platforma obsługuje podstawowe zarządzanie danymi, skalowanie i optymalizację wydajności.
Integracja technik dzielenia danych w platformach no-code umożliwia szybkie tworzenie aplikacji, ponieważ programiści mogą wykorzystać wbudowane możliwości dzielenia danych bez konieczności ręcznej konfiguracji lub kodowania. W rezultacie firmy mogą korzystać z bardziej opłacalnego i wydajnego procesu tworzenia aplikacji, ponieważ programiści mogą poświęcić więcej czasu i zasobów na działania tworzące wartość dodaną, takie jak projektowanie innowacyjnych doświadczeń użytkowników i udoskonalanie procesów biznesowych.
Co więcej, uwzględnienie dzielenia danych w platformach no-code zapewnia, że aplikacje mogą być budowane z myślą o skalowalności od samego początku. Wykorzystując strategie dzielenia danych, aplikacje no-code mogą płynnie dostosowywać się do wzrostu ilości danych i baz użytkowników bez doświadczania wąskich gardeł wydajności lub problemów ze stabilnością. Funkcja ta jest szczególnie cenna dla nowoczesnych przedsiębiorstw, które oczekują, że ich aplikacje będą się dostosowywać i skalować wraz ze zmieniającymi się potrzebami biznesowymi.
AppMaster to wiodąca platforma no-code, która łączy w sobie nowoczesny, intuicyjny interfejs z potężnymi możliwościami generowania aplikacji backendowych, webowych i mobilnych. Uznając znaczenie shardingu danych w tworzeniu skalowalnych i wysokowydajnych aplikacji, AppMaster integruje wbudowaną strategię shardingu, aby umożliwić programistom łatwe wdrażanie partycjonowania i optymalizacji danych w swoich aplikacjach.
Dzięki możliwościom dzielenia danych oferowanym przez AppMaster, programiści mogą tworzyć aplikacje, które automatycznie dystrybuują dane między wieloma instancjami lub serwerami, zapewniając, że aplikacje są wysoce skalowalne i wydajne, nawet przy dużych obciążeniach i dużych ilościach danych.
Wykorzystując funkcje dzielenia danych AppMaster, firmy mogą zaoszczędzić zarówno czas, jak i pieniądze w procesie rozwoju, ponieważ programiści nie muszą już poświęcać znacznego wysiłku na konfigurowanie i zarządzanie rozmieszczaniem odłamków, równoważeniem i zadaniami konserwacyjnymi. Zamiast tego mogą skupić się na tworzeniu innowacyjnych, zorientowanych na klienta rozwiązań, zapewniając jednocześnie, że ich aplikacje są zbudowane do obsługi systemów o dużej skali i wysokich wymaganiach wydajnościowych.
Sharding danych ma kluczowe znaczenie w zarządzaniu systemami o dużej skali i stał się istotnym elementem nowoczesnych aplikacji. "Innowacja to tworzenie nowego lub ponowne układanie starego w nowy sposób", jak trafnie sformułował Mike Vance. Rozumiejąc różne strategie i techniki shardingu oraz wykorzystując innowacyjną moc platform no-code, takich jak AppMaster, programiści mogą tworzyć skalowalne, wysokowydajne aplikacje, które zachowują swoją responsywność i wydajność, nawet gdy rosną i ewoluują w czasie.
Data sharding to strategia stosowana w dużych systemach do partycjonowania danych na wielu serwerach lub instancjach w celu poprawy wydajności, skalowalności i łatwości zarządzania.
Sharding danych pomaga zarządzać ograniczeniami fizycznych zasobów sprzętowych, skracać czasy odpowiedzi zapytań oraz poprawiać ogólną wydajność i skalowalność nowoczesnych aplikacji.
Wyzwania obejmują określenie odpowiedniej strategii shardingu, zarządzanie złożonością systemów rozproszonych oraz zapewnienie spójności i integralności danych w shardach.
Typowe strategie shardingu obejmują sharding oparty na zakresach, sharding oparty na hashach i sharding oparty na katalogach.
AppMaster wykorzystuje platformę no-code z wbudowaną strategią shardingu do tworzenia wysoce skalowalnych i wydajnych aplikacji, pozwalając programistom skupić się na logice aplikacji, a nie na złożoności shardingu danych.
Tak, sharding danych można wdrożyć na platformach no-code, umożliwiając szybkie tworzenie i skalowanie aplikacji bez konieczności ich ręcznej konfiguracji lub kodowania.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


