La fragmentación de datos es una técnica utilizada para particionar y distribuir datos entre varios servidores o instancias, a menudo empleada en sistemas a gran escala para mejorar el rendimiento, la escalabilidad y la capacidad de gestión. El concepto de fragmentación de datos tiene su origen en el particionamiento horizontal, en el que una única tabla se divide en particiones más pequeñas, cada una de las cuales contiene un subconjunto de los datos de la tabla original.
La fragmentación de datos consiste en dividir los datos de un sistema más grande entre múltiples entidades más pequeñas, o "fragmentos". Cada fragmento funciona de forma independiente, lo que permite al sistema procesar las solicitudes de forma simultánea y eficiente, al tiempo que proporciona tolerancia a fallos y garantiza la disponibilidad. La fragmentación es especialmente útil en sistemas distribuidos y aplicaciones de alto rendimiento, donde los volúmenes de datos y las tasas de solicitud de los usuarios pueden ser bastante grandes. Al repartir la carga de trabajo de procesamiento entre varios fragmentos, un sistema puede gestionar eficazmente las limitaciones de los recursos físicos de hardware, reducir los tiempos de respuesta de las consultas y aumentar el rendimiento.
Fuente de la imagen: DigitalOcean
Ventajas de la fragmentación de datos en sistemas a gran escala
La implementación de la fragmentación de datos en sistemas a gran escala ofrece numerosos beneficios que pueden mejorar el rendimiento y la escalabilidad de las aplicaciones modernas. Algunos de estos beneficios incluyen:
- Escalabilidad mejorada: Una de las principales ventajas de la fragmentación de datos es su capacidad para mejorar la escalabilidad de una aplicación. Al distribuir los datos y la carga de trabajo entre varios servidores, los desarrolladores pueden superar los retos que supone gestionar volúmenes de datos y demandas de usuarios cada vez mayores. Esto permite ampliar el sistema según sea necesario, en lugar de ampliarlo, lo que implica aumentar los recursos de un único servidor.
- Mayor rendimiento: Los datos se dividen en trozos más pequeños y se distribuyen en múltiples shards, de modo que la carga de trabajo de procesamiento se reparte entre diferentes servidores. Esto permite el procesamiento concurrente y reduce la contención por un único recurso, mejorando el rendimiento del sistema.
- Procesamiento de consultas más rápido: La fragmentación de los datos puede acelerar notablemente los tiempos de procesamiento de las consultas, especialmente en sistemas con operaciones de lectura o escritura intensivas. Al distribuir los datos en varios fragmentos, una consulta puede ser atendida únicamente por el fragmento correspondiente, evitando la necesidad de escanear un conjunto de datos monolítico de mayor tamaño. Esto se traduce en tiempos de respuesta más cortos para las solicitudes de los usuarios y una menor latencia.
- Mayor disponibilidad y tolerancia a fallos: Al distribuir los datos entre varios servidores o instancias, la fragmentación ayuda a garantizar que una aplicación siga estando disponible y respondiendo incluso cuando los fragmentos individuales experimentan fallos o interrupciones. Esto, a su vez, hace que el sistema sea más tolerante a fallos y resistente al tiempo de inactividad causado por puntos únicos de fallo.
- Utilización eficiente de los recursos: La fragmentación ofrece un método más eficiente y equilibrado de utilizar los recursos del sistema en lugar de concentrar la carga de trabajo de procesamiento en un único servidor. Este uso eficaz de los recursos permite un mayor grado de concurrencia, lo que a menudo se traduce en un mejor rendimiento y un mayor rendimiento.
Desafíos de la fragmentación de datos
Aunque la fragmentación de datos aporta importantes ventajas a los sistemas a gran escala y a las aplicaciones de alto rendimiento, también plantea algunos retos. La implementación de una estrategia de fragmentación requiere una cuidadosa planificación y consideración, teniendo en cuenta diversos factores como la arquitectura del sistema, los patrones de acceso a los datos y los requisitos de la aplicación. Algunos de los retos a los que suelen enfrentarse los desarrolladores a la hora de emplear la fragmentación de datos son:
Determinación de la estrategia de fragmentación óptima
La elección de una estrategia de fragmentación adecuada puede ser compleja, ya que requiere un profundo conocimiento del modelo de datos del sistema y de los patrones de acceso. La selección de una estrategia inadecuada puede dar lugar a un uso ineficiente de los recursos, una distribución desequilibrada de la carga de trabajo o una gestión complicada de los datos. Antes de determinar la mejor estrategia de fragmentación para el sistema, es necesario analizar cuidadosamente los patrones de acceso a los datos, las proyecciones de crecimiento y los requisitos técnicos.
Gestión de la complejidad de los sistemas distribuidos
Un reto crítico de la fragmentación es la gestión de la creciente complejidad de las arquitecturas de sistemas distribuidos. Los desarrolladores deben tener en cuenta la coherencia e integridad de los datos en los distintos fragmentos, la capacidad de recuperación en caso de fallos y la optimización del rendimiento de las consultas en todo el sistema. Es esencial disponer de las herramientas, la supervisión y los mecanismos de copia de seguridad adecuados para gestionar eficazmente la complejidad añadida de los sistemas fragmentados.
Garantizar la coherencia y la integridad de los datos
Uno de los principales retos a la hora de implantar la fragmentación de datos es garantizar la coherencia e integridad de los datos en todos los fragmentos. Dado que los datos se reparten entre varios servidores, mantener la coherencia puede resultar difícil, especialmente cuando el sistema requiere transacciones atómicas que abarcan varios fragmentos. Los desarrolladores tienen que adoptar técnicas como las transacciones distribuidas, la consistencia eventual u otras estrategias para mantener la consistencia de los datos en todos los shards.
A pesar de estos retos, los beneficios de la fragmentación de datos son significativos, especialmente para sistemas a gran escala y aplicaciones de alto rendimiento. Con una cuidadosa planificación, selección de estrategias y un potente diseño del sistema, los desarrolladores pueden implantar con éxito la fragmentación de datos y liberar su potencial para mejorar la escalabilidad y el rendimiento.
Estrategias y técnicas de fragmentación
La fragmentación de datos es un componente crítico en la creación de aplicaciones escalables y de alto rendimiento. La comprensión de las diferentes estrategias y técnicas de fragmentación le permitirá elegir el enfoque más adecuado para sus necesidades específicas. Esta sección explorará tres estrategias comunes de fragmentación: fragmentación basada en rangos, fragmentación basada en hash y fragmentación basada en directorios.
Compartimentación por rangos
La fragmentación basada en rangos consiste en particionar los datos en función de un rango específico de valores para una clave determinada. Puede ser un concepto sencillo de entender e implementar para el desarrollador. Por ejemplo, puede dividir los registros de clientes en función del intervalo de ID de cliente (por ejemplo, ID de cliente 1-1000 en el fragmento A, 1001-2000 en el fragmento B, etc.). Este método garantiza que los datos se distribuyan uniformemente entre los fragmentos y se puedan consultar fácilmente por el rango de claves.
Pero la fragmentación basada en rangos tiene algunos inconvenientes. Uno de ellos es la posibilidad de que los datos se distribuyan de forma desigual si la clave elegida está sesgada. Esta situación puede provocar puntos calientes y cuellos de botella en el rendimiento, ya que algunos fragmentos pueden sobrecargarse, mientras que otros permanecen infrautilizados. La elección de una clave de fragmentación con una distribución uniforme es esencial para contrarrestar este problema.
Fragmentación basada en hash
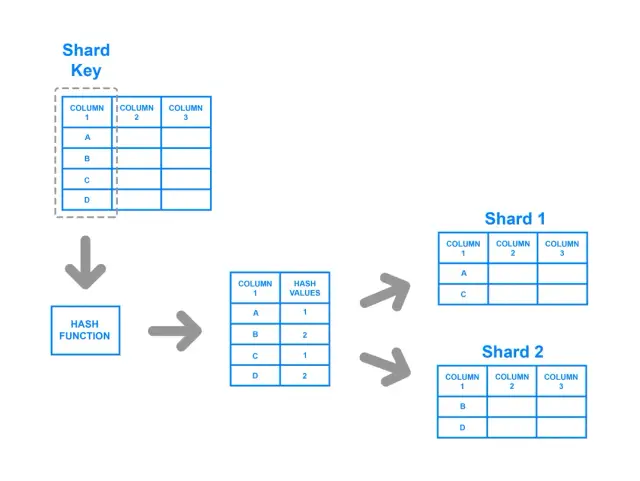
La fragmentación basada en hash consiste en aplicar una función hash a la clave del fragmento, y el hash resultante determina a qué fragmento pertenecen los datos. Esta estrategia garantiza una distribución más uniforme de los datos entre los fragmentos, ya que la función hash está diseñada para ofrecer un resultado equilibrado independientemente de los valores de entrada. En este enfoque, un par clave-valor se somete a hash, y el resultado de la función hash determina el fragmento al que se dirigen los datos.
A pesar de sus ventajas para lograr una distribución equilibrada, la fragmentación basada en hash tiene posibles inconvenientes. Por ejemplo, puede resultar difícil realizar consultas de rango con este método, ya que las relaciones entre las claves originales se pierden en el proceso de hash. Además, cuando cambia el número de fragmentos, la mayoría de los métodos basados en hash requieren que se vuelva a hacer el hash y se redistribuyan una cantidad sustancial de datos, lo que puede consumir muchos recursos y tiempo.
Fragmentación basada en directorios
La compartimentación basada en directorios utiliza una tabla o servicio de búsqueda independiente para saber qué compartimento contiene los datos de una clave determinada. Cuando se escriben datos en el sistema, el servicio de directorio determina el almacén apropiado y devuelve su ubicación a la aplicación. Este método permite a la aplicación realizar consultas tanto basadas en claves como en rangos de forma eficiente.
Sin embargo, la fragmentación basada en directorios tiene sus retos, como la gestión de un servicio de directorio independiente que podría convertirse en un punto único de fallo o en un cuello de botella para el rendimiento. Por lo tanto, es esencial garantizar la fiabilidad y escalabilidad del servicio de directorio cuando se utiliza este enfoque.
Las plataformas sin código como AppMaster permiten a las empresas crear, desplegar y escalar aplicaciones más rápidamente al eliminar la complejidad del proceso de desarrollo. La implementación de la fragmentación de datos en las plataformas no-code puede mejorar aún más sus beneficios, ya que permite a los desarrolladores centrarse en la creación de la lógica de la aplicación y las experiencias del usuario, mientras que la plataforma se encarga de la gestión de datos subyacentes, el escalado y la optimización del rendimiento.
La integración de técnicas de fragmentación de datos en las plataformas no-code permite un rápido desarrollo de las aplicaciones, ya que los desarrolladores pueden aprovechar las capacidades de fragmentación incorporadas sin necesidad de una configuración o codificación manual exhaustiva. Como resultado, las empresas pueden beneficiarse de un proceso de desarrollo de aplicaciones más rentable y eficiente, ya que los desarrolladores pueden dedicar más tiempo y recursos a actividades de valor añadido, como el diseño de experiencias de usuario innovadoras y el perfeccionamiento de los procesos de negocio.
Además, la inclusión de la fragmentación de datos en las plataformas no-code garantiza que las aplicaciones puedan crearse teniendo en cuenta la escalabilidad desde el principio. Al aprovechar las estrategias de fragmentación de datos, las aplicaciones de no-code pueden adaptarse sin problemas al crecimiento de los volúmenes de datos y las bases de usuarios sin experimentar cuellos de botella en el rendimiento ni problemas de estabilidad. Esta característica es especialmente valiosa para las empresas modernas que esperan que sus aplicaciones se adapten y escalen con la evolución de sus necesidades empresariales.
Caso práctico: Implementación de Data Sharding en AppMaster
AppMaster es una plataforma sin código líder que combina una interfaz moderna e intuitiva con potentes capacidades de generación de aplicaciones backend, web y móviles. Reconociendo la importancia de la fragmentación de datos en el desarrollo de aplicaciones escalables y de alto rendimiento, AppMaster integra una estrategia de fragmentación incorporada para permitir a los desarrolladores implementar fácilmente la partición y optimización de datos en sus aplicaciones.
Con las funciones de fragmentación de datos que ofrece AppMaster, los desarrolladores pueden crear aplicaciones que distribuyan automáticamente los datos entre varias instancias o servidores, garantizando así la escalabilidad y el rendimiento de las aplicaciones, incluso con cargas de trabajo elevadas y grandes cantidades de datos.

Al aprovechar las funciones de fragmentación de datos de AppMaster, las empresas pueden ahorrar tiempo y dinero en el proceso de desarrollo, ya que los desarrolladores ya no tienen que dedicar un esfuerzo considerable a configurar y gestionar la colocación, el reequilibrio y las tareas de mantenimiento de los fragmentos. En su lugar, pueden centrarse en crear soluciones innovadoras y centradas en el cliente, garantizando al mismo tiempo que sus aplicaciones están diseñadas para gestionar sistemas a gran escala y requisitos de alto rendimiento.
La fragmentación de datos es fundamental para gestionar sistemas a gran escala y se ha convertido en un componente esencial de las aplicaciones modernas. "La innovación es la creación de lo nuevo o la reorganización de lo viejo de una manera nueva", como bien dijo Mike Vance. Comprendiendo las distintas estrategias y técnicas de fragmentación y aprovechando el poder innovador de las plataformas no-code como AppMaster, los desarrolladores pueden crear aplicaciones escalables y de alto rendimiento que mantengan su capacidad de respuesta y eficiencia, incluso a medida que crecen y evolucionan con el tiempo.






