
Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Dowiedz się, czym jest relacyjna baza danych i jak działa. Odkryj, jak może ona pomóc Ci zorganizować i efektywnie zarządzać danymi.

Relacyjna baza danych to podstawowe pojęcie w świecie zarządzania danymi. Jest to rodzaj bazy danych, która przechowuje i zarządza danymi za pomocą tabel i relacji między nimi. W dzisiejszym świecie opartym na danych, firmy i organizacje wszystkich rozmiarów polegają na relacyjnych bazach danych w celu efektywnego przechowywania, organizowania i zarządzania dużymi ilościami danych.
Model relacyjnej bazy danych został po raz pierwszy zaproponowany w latach 70. przez Edgara F. Codda, brytyjskiego informatyka. Od tego czasu stał się dominującym modelem bazy danych i jest wykorzystywany w różnych zastosowaniach, od systemów planowania zasobów przedsiębiorstwa (ERP) po strony internetowe e-commerce i aplikacje mobilne.
W tym artykule poznamy relacyjną bazę danych, sposób jej działania oraz korzyści i ograniczenia. Omówimy również różne elementy relacyjnej bazy danych, takie jak tabele, klucze i relacje, oraz jak współpracują one ze sobą w celu zarządzania danymi. Pod koniec tego artykułu będziesz miał solidne zrozumienie relacyjnych baz danych i ich roli w nowoczesnym zarządzaniu danymi.
Relacyjna baza danych jest rodzajem bazy danych, która organizuje dane w jedną lub więcej tabel lub relacji, z których każda ma unikalną nazwę i składa się z zestawu wierszy i kolumn. Dane w relacyjnej bazie danych są uporządkowane i zorganizowane, co ułatwia ich przeszukiwanie, pobieranie i zarządzanie.
Dane w relacyjnej bazie danych są zazwyczaj przechowywane w znormalizowanej formie. Dane są podzielone na mniejsze, powiązane ze sobą tabele, z których każda ma swój unikalny klucz lub identyfikator. Relacje pomiędzy tymi tabelami są definiowane poprzez użycie kluczy obcych, które łączą dane w jednej tabeli z danymi w innej.
Relacyjne bazy danych są szeroko stosowane w różnych aplikacjach, w tym w systemach biznesowych i finansowych, badaniach naukowych i handlu elektronicznym. Zapewniają one elastyczny i skalowalny sposób przechowywania i zarządzania dużymi ilościami danych przy jednoczesnym zapewnieniu integralności i spójności danych poprzez ograniczenia, takie jak klucze główne i klucze obce.
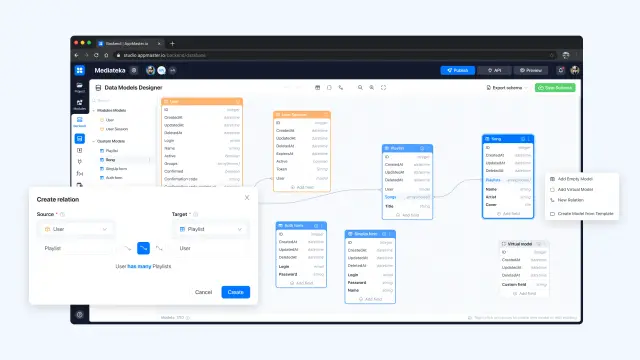
AppMaster korzysta z relacyjnych baz danych. Korzysta z DBMS Postgres. Użytkownicy AppMaster mogą tworzyć dowolne schematy relacyjnych baz danych, w tym wiele typów pól i relacji. Użytkownicy mogą tworzyć nieograniczoną liczbę modeli, relacji i pól. Za każdym razem, gdy zmieniają schemat danych i zapisują go, AppMaster automatycznie napisze migrację dla istniejących schematów z UPD. To znaczy, że kiedy użytkownik wypycha nową wersję swojej aplikacji ze zmienioną bazą danych, binarna aplikacja automatycznie migruje stary format schematu bazy danych do nowego formatu bez utraty swoich danych.
Relacyjne bazy danych są zbudowane przy użyciu tabel, które są również znane jako relacje. Każda tabela składa się z wierszy i kolumn, przy czym każdy wiersz reprezentuje pojedynczy rekord lub instancję danych, a każda kolumna reprezentuje określony atrybut lub pole danych. Zestaw atrybutów lub typów danych, takich jak tekst, liczba, data lub Boolean, definiuje kolumny w tabeli. Każda kolumna ma również unikalną nazwę, która pomaga zidentyfikować typ danych przechowywanych w tej kolumnie.
Wiersze w tabeli reprezentują poszczególne rekordy lub instancje danych. Każdy wiersz posiada unikalny identyfikator, który nazywany jest kluczem głównym. Klucz główny jest używany do łączenia rekordów w różnych tabelach w bazie danych. Relacje pomiędzy tabelami w relacyjnej bazie danych są definiowane przy użyciu kluczy obcych. Klucz obcy to kolumna w jednej tabeli, która odnosi się do klucza głównego innej tabeli. Pozwala to na powiązanie i dostęp do powiązanych danych z różnych tabel w bazie danych.
Oprócz tabel, relacyjne bazy danych wykorzystują również ograniczenia w celu zapewnienia integralności i spójności danych. Ograniczenia są regułami lub warunkami, które muszą być spełnione zanim dane mogą być wstawione, zaktualizowane lub usunięte z bazy danych. Przykłady ograniczeń obejmują klucze podstawowe, klucze obce, ograniczenia unikalne i ograniczenia sprawdzające.
Model relacyjny to model danych, który jest używany do projektowania i zarządzania danymi w relacyjnej bazie danych. Model relacyjny został wprowadzony przez Edgara F. Codda w 1970 roku i od tego czasu stał się najczęściej stosowanym modelem danych dla nowoczesnych baz danych.
Model relacyjny opiera się na koncepcji tabel, które są również znane jako relacje. Każda tabela w bazie danych reprezentuje zbiór powiązanych danych, a każdy wiersz w tabeli reprezentuje pojedynczy rekord lub instancję tych danych. Każda kolumna w tabeli reprezentuje określony atrybut lub pole danych.
Relacje pomiędzy tabelami w bazie danych są definiowane za pomocą kluczy. Klucz główny jest kolumną lub zestawem kolumn w tabeli, które jednoznacznie identyfikują każdy wiersz w tej tabeli. Klucz obcy jest kolumną w jednej tabeli, która odnosi się do klucza głównego innej tabeli, pozwalając na powiązanie powiązanych danych między różnymi tabelami w bazie danych.
Model relacyjny obsługuje również operacje zapytania i manipulowania danymi w bazie danych, takie jak SELECT, INSERT, UPDATE i DELETE. Operacje te są wykonywane przy użyciu specjalnego języka zwanego Structured Query Language (SQL), który definiuje zapytania i polecenia, które oddziałują na bazę danych.
Jedną z kluczowych zalet modelu relacyjnego jest jego elastyczność i skalowalność. Tabele mogą być dodawane, usuwane lub modyfikowane w celu dostosowania do zmieniających się wymagań dotyczących danych, a relacje między tabelami mogą być łatwo definiowane lub aktualizowane w razie potrzeby. Dodatkowo model relacyjny zapewnia spójny i znormalizowany sposób organizowania i zarządzania danymi, ułatwiając utrzymanie i aktualizację dużych i złożonych baz danych w czasie.
Systemy zarządzania relacyjnymi bazami danych (RDBMS) oferują liczne korzyści, z których niektóre to:
RDBMS zapewniają solidny i niezawodny sposób zarządzania danymi i są szeroko stosowane w różnych aplikacjach, w tym systemach biznesowych i finansowych, badaniach naukowych i handlu elektronicznym.
Model relacyjny jest modelem danych, który pomaga wymusić spójność danych w systemie bazodanowym. Model ten oparty jest na koncepcji tabel lub relacji, gdzie każda tabela reprezentuje zbiór powiązanych danych, a każdy wiersz w tabeli reprezentuje pojedynczy rekord lub instancję tych danych. Każda kolumna w tabeli reprezentuje określony atrybut lub pole danych.
Spójność danych odnosi się do dokładności i wiarygodności danych przechowywanych w bazie danych. W modelu relacyjnym spójność danych jest wymuszana przez użycie ograniczeń. Ograniczenia są regułami lub warunkami, które muszą być spełnione zanim dane mogą być wstawione, zaktualizowane lub usunięte z tabeli. W modelu relacyjnym można użyć kilku typów ograniczeń, takich jak klucze główne, klucze obce i ograniczenia sprawdzające.
Klucz główny jest unikalnym identyfikatorem dla każdego wiersza w tabeli. Zapewnia on, że każdy rekord w tabeli może być zidentyfikowany i dostępny bez pomyłek i błędów. Klucz obcy jest kolumną w jednej tabeli, która odnosi się do klucza głównego innej tabeli. Zapewnia, że powiązane dane w różnych tabelach są połączone prawidłowo. Ograniczenia sprawdzające są używane do zapewnienia, że wartości danych spełniają określone kryteria lub warunki.
Oprócz ograniczeń model relacyjny obsługuje również transakcje. Transakcja to seria operacji na bazie danych wykonywanych razem jako pojedyncza jednostka pracy. Jeśli jakakolwiek część transakcji zawiedzie, cała transakcja jest cofana, co zapewnia, że baza danych pozostaje spójna.
Wykorzystanie ograniczeń i transakcji w modelu relacyjnym pomaga zapewnić spójność danych w bazie. Ograniczenia zapewniają, że dane są wprowadzane i przechowywane w sposób spójny i niezawodny, natomiast transakcje zapewniają, że modyfikacje danych są dokonywane w sposób atomowy i spójny.
Ponadto RDBMS implementuje mechanizm zwany właściwością "ACID", zapewniający niezawodność transakcji. ACID to skrót od Atomowość, Spójność, Izolacja i Trwałość. Atomowość zapewnia, że transakcja jest traktowana jako pojedyncza jednostka pracy, co oznacza, że wszystkie zmiany są zatwierdzane lub żadna nie jest zatwierdzana. Spójność zapewnia, że baza danych pozostaje w spójnym stanie po każdej transakcji. Izolacja zapewnia, że wiele transakcji może być wykonywanych równolegle bez wzajemnego zakłócania się. Trwałość zapewnia, że zmiany dokonane w bazie danych utrzymują się nawet podczas awarii lub przerw w działaniu systemu.
Model relacyjny dostarcza solidnego i niezawodnego sposobu zarządzania danymi, zapewniając spójność danych w bazie danych. Wymuszając spójność danych, model relacyjny pomaga utrzymać dokładność i wiarygodność danych, co jest krytyczne dla wielu zastosowań.
Zobowiązanie i atomowość to dwa kluczowe pojęcia w systemach baz danych, szczególnie w kontekście przetwarzania transakcji. Transakcja jest sekwencją operacji w bazie danych, które są traktowane jako pojedyncza logiczna jednostka pracy. Transakcje mogą obejmować wiele operacji, takich jak odczyt, zapis i aktualizacja danych, i są często wykorzystywane do zapewnienia, że zmiany w bazie danych są dokonywane w sposób spójny i niezawodny.
Atomowość odnosi się do właściwości transakcji, która zapewnia, że wszystkie jej operacje są traktowane jako jedna, niepodzielna jednostka pracy. Oznacza to, że albo wszystkie operacje w transakcji są zakończone sukcesem, albo żadna z nich. Jeśli jakakolwiek część transakcji nie powiedzie się lub napotka błąd, cała transakcja jest cofana, a wszystkie zmiany dokonane w bazie danych podczas transakcji są cofane.
Zaangażowanie odnosi się do właściwości transakcji, która zapewnia, że po jej pomyślnym zakończeniu jej zmiany zostaną trwale zapisane w bazie danych. Po wykonaniu transakcji, jej zmiany nie mogą być cofnięte ani zwinięte. Zaangażowanie jest zwykle implementowane za pomocą instrukcji commit lub podobnego mechanizmu, który sygnalizuje koniec transakcji i powoduje, że jej zmiany są zapisywane w bazie danych.
Połączenie atomowości i zaangażowania zapewnia, że transakcje w bazie danych są niezawodne i spójne. Atomowość zapewnia, że transakcje są wykonywane w sposób "wszystko albo nic", co pomaga zapobiegać niespójnościom danych lub korupcji. Zaangażowanie zapewnia, że po pomyślnym zakończeniu transakcji jej zmiany są trwałe i mogą na nich polegać inne transakcje lub aplikacje.
W systemach baz danych implementacja atomowości i zaangażowania jest często osiągana poprzez menedżera transakcji lub system przetwarzania transakcji, który jest odpowiedzialny za koordynację i zarządzanie transakcjami. Menadżer transakcji zapewnia, że transakcje są wykonywane w sposób atomowy i spójny, a ich zmiany są przekazywane do bazy danych po ich pomyślnym zakończeniu.
Właściwości ACID (Atomicity, Consistency, Isolation, and Durability) to zestaw cech zapewniających niezawodność i spójność transakcji w bazie danych. Systemy zarządzania relacyjnymi bazami danych (RDBMS) są zaprojektowane tak, aby wspierać właściwości ACID, które są kluczowe dla prawidłowego funkcjonowania wielu aplikacji i systemów, które opierają się na danych.
Atomowość odnosi się do idei, że transakcja powinna być traktowana jako pojedyncza, niepodzielna jednostka pracy. Oznacza to, że jeśli jakakolwiek część transakcji zawiedzie, cała transakcja powinna zostać cofnięta, a wszystkie zmiany dokonane w bazie danych podczas transakcji powinny zostać cofnięte. Atomowość zapewnia, że zmiany w bazie danych są dokonywane konsekwentnie i niezawodnie, bez częściowych lub niekompletnych aktualizacji.
Spójność odnosi się do idei, że transakcja powinna pozostawić bazę danych w spójnym stanie, w którym wszystkie dane spełniają określone reguły i ograniczenia. Oznacza to, że transakcja nie powinna naruszyć żadnego z ograniczeń integralności bazy danych, takich jak unikalne klucze lub klucze obce. Spójność zapewnia, że baza danych pozostaje niezawodna i dokładna.
Izolacja odnosi się do idei, że wiele transakcji powinno być w stanie wykonywać się współbieżnie bez wzajemnego zakłócania się. Izolacja zapewnia, że efekty jednej transakcji nie są widoczne dla innych transakcji, dopóki pierwsza transakcja nie zostanie zakończona. Właściwość ta zapobiega powstawaniu niespójności danych i konfliktów, gdy wiele transakcji próbuje uzyskać dostęp lub zmodyfikować te same dane jednocześnie.
Trwałość odnosi się do idei, że po dokonaniu transakcji jej zmiany powinny być trwałe i uporczywe, nawet w przypadku awarii systemu. Trwałość jest zazwyczaj implementowana za pomocą technik takich jak write-ahead logging, gdzie wszystkie zmiany dokonane podczas transakcji są zapisywane w pliku dziennika zanim zostaną zastosowane w bazie danych. Zapewnia to, że nawet w przypadku awarii systemu lub braku zasilania, zmiany dokonane podczas transakcji mogą zostać odzyskane.
Systemy RDBMS, takie jak MySQL, Oracle i SQL Server, zapewniają wbudowane wsparcie dla właściwości ACID, co gwarantuje, że transakcje w bazie danych są wykonywane niezawodnie i spójnie. Właściwości te pomagają zapewnić integralność i niezawodność bazy danych, co czyni je odpowiednimi dla wielu aplikacji, które polegają na dokładnych i spójnych danych.
Procedury zapisane to programy przechowywane w systemie zarządzania relacyjną bazą danych (RDBMS) i wykonywane po stronie serwera. Służą do wykonywania złożonych operacji na danych przechowywanych w bazie i mogą być wywoływane z programów aplikacyjnych lub bezpośrednio z systemu zarządzania bazą danych.
Procedury składowane są zazwyczaj napisane w języku programowania obsługiwanym przez system zarządzania bazą danych, takim jak SQL lub PL/SQL. Są one kompilowane i przechowywane w bazie danych i mogą być wykonywane poprzez wywołanie ich przez nazwę.
Procedury składowane zapewniają kilka korzyści w środowisku relacyjnej bazy danych. Jedną z nich jest to, że mogą poprawić wydajność poprzez zmniejszenie ilości danych, które muszą być przesyłane pomiędzy bazą danych a aplikacją. Dzieje się tak dlatego, że procedury składowane są wykonywane po stronie serwera, co zmniejsza ruch sieciowy i opóźnienia.
Procedury składowane zapewniają również pewien poziom bezpieczeństwa i kontroli dostępu. Mogą być wykorzystywane do egzekwowania reguł biznesowych i polityk bezpieczeństwa, a także mogą ograniczać dostęp do wrażliwych danych, zezwalając na ich wykonanie tylko upoważnionym użytkownikom. Dodatkowo, ponieważ procedury składowane są prekompilowane i przechowywane w bazie danych, są mniej podatne na ataki SQL injection niż doraźne instrukcje SQL.
Inną zaletą procedur składowanych jest to, że mogą one poprawić spójność bazy danych i jej utrzymanie. Poprzez zamknięcie złożonej logiki biznesowej w procedurze składowanej, programiści aplikacji mogą zapewnić, że logika ta jest konsekwentnie stosowana w całej bazie danych. Dodatkowo, procedury składowane mogą być aktualizowane niezależnie od kodu aplikacji, co ułatwia utrzymanie i aktualizację logiki bazy danych.
Podsumowując, procedury składowane zapewniają szereg korzyści w środowisku relacyjnej bazy danych, w tym zwiększoną wydajność, bezpieczeństwo, kontrolę dostępu, spójność i łatwość utrzymania. Są potężnym narzędziem dla programistów i administratorów baz danych i są szeroko stosowane w nowoczesnych systemach baz danych.
Kontrola współbieżności jest krytycznym aspektem systemów zarządzania relacyjnymi bazami danych (RDBMS), który zapewnia, że wiele transakcji uzyskujących dostęp do tych samych danych może wykonywać się współbieżnie bez uzyskania nieprawidłowych wyników. Jedną z technik używanych do osiągnięcia kontroli współbieżności jest blokada bazy danych, która polega na nabywaniu i zwalnianiu blokad na obiektach bazy danych takich jak tabele, wiersze lub kolumny.
Blokada jest mechanizmem, który zapobiega jednoczesnemu dostępowi do tych samych danych przez wiele transakcji. Kiedy transakcja żąda dostępu do określonego obiektu bazy danych, np. wiersza w tabeli, nabywa blokadę na tym obiekcie. Blokada uniemożliwia innym transakcjom dostęp do obiektu, dopóki pierwsza transakcja nie zwolni blokady. Po zakończeniu transakcji blokada jest zwalniana, co umożliwia innym transakcjom dostęp do obiektu.
W blokadach baz danych istnieją dwie kategorie: blokady współdzielone i blokady wyłączne. Zamki współdzielone umożliwiają wielu transakcjom jednoczesny odczyt tych samych danych, natomiast zamki wyłączne blokują innym transakcjom dostęp do danych do momentu zwolnienia blokady. Gdy transakcja uzyska wyłączną blokadę na obiekcie bazy danych, ma pełną kontrolę nad tym obiektem i może go dowolnie modyfikować.
Blokada bazy danych jest niezbędna do zachowania spójności danych w współbieżnych transakcjach bazy danych. Jednakże może ona również prowadzić do problemów z wydajnością, szczególnie w środowiskach o dużej liczbie transakcji. Jeśli zbyt wiele transakcji oczekuje na zwolnienie blokad, może to spowodować długi czas oczekiwania i spadek przepustowości.
Aby rozwiązać ten problem, wiele systemów RDBMS stosuje różne techniki blokowania, takie jak optymistyczne blokowanie, które pozwala wielu transakcjom na równoczesny dostęp do tych samych danych i rozwiązuje konflikty tylko wtedy, gdy się pojawią. Innym podejściem jest wykorzystanie kontroli współbieżności wielu wersji (MVCC), która tworzy wiele wersji danych w bazie danych, pozwalając wielu transakcjom na jednoczesny odczyt i modyfikację danych bez blokowania.
Blokowanie bazy danych jest krytyczną techniką utrzymywania spójności we współbieżnych transakcjach bazy danych. Chociaż może to prowadzić do problemów z wydajnością, nowoczesne systemy RDBMS wykorzystują różne techniki i algorytmy blokowania, aby zminimalizować czas oczekiwania i poprawić współbieżność.
Przy wyborze relacyjnej bazy danych należy rozważyć kilka czynników, w tym:
Wybór relacyjnej bazy danych wymaga rozważenia kilku czynników, w tym skalowalności, wydajności, dostępności, bezpieczeństwa, łatwości użycia, kompatybilności, kosztów, społeczności, funkcji i możliwości oraz wsparcia dostawcy. Dokładna ocena tych czynników może pomóc w wyborze bazy danych, która spełnia wymagania aplikacji i zapewnia niezawodny, wydajny i bezpieczny dostęp do danych.
Historia relacyjnych baz danych rozpoczyna się pod koniec lat 60. ubiegłego wieku, kiedy to informatyk o nazwisku Edgar Codd zaproponował koncepcję relacyjnego modelu baz danych. Ideą Codda było zorganizowanie danych w tabele lub relacje, z których każda składa się z wierszy i kolumn, przy czym każdy wiersz reprezentuje unikalny rekord, a każda kolumna atrybut danych. Zaproponował on również zestaw zasad matematycznych, znanych jako algebra relacyjna, służących do manipulowania i odpytywania danych.
We wczesnych latach 70. badacze IBM Donald Chamberlin i Raymond Boyce opracowali język zapytań do relacyjnych baz danych o nazwie Structured English Query Language (SEQUEL), przemianowany później na SQL. SQL stał się standardowym językiem dla relacyjnych baz danych i do dziś jest szeroko stosowany.
Pod koniec lat 70. i na początku lat 80. powstało kilka komercyjnych systemów relacyjnych baz danych, w tym System R firmy IBM, Oracle i Ingres. Bazy te implementowały model relacyjny i zapewniały takie funkcje jak obsługa transakcji, indeksowanie i optymalizacja zapytań.
W latach 90-tych popularność relacyjnych baz danych nadal rosła wraz z pojawieniem się obliczeń klient-serwer i Internetu. Relacyjne bazy danych zapewniają solidną i skalowalną platformę do przechowywania i wyszukiwania danych, wspierając zastosowania od systemów finansowych po witryny handlu elektronicznego.
Na początku XXI wieku rozwój oprogramowania open-source doprowadził do powstania kilku popularnych relacyjnych baz danych typu open-source, w tym MySQL, PostgreSQL oraz SQLite. Bazy te stanowiły ekonomiczną alternatywę dla komercyjnych baz danych i zostały szeroko przyjęte przez programistów i organizacje.
Obecnie relacyjne bazy danych nadal są najczęściej używanym typem bazy danych, z nowymi funkcjami i możliwościami, takimi jak przetwarzanie rozproszone, integracja z chmurą i wsparcie uczenia maszynowego. Chociaż pojawiły się inne typy baz danych, takie jak bazy NoSQL i bazy danych grafów, relacyjne bazy danych pozostają krytycznym elementem infrastruktury danych dla wielu organizacji.
Podsumowując, relacyjna baza danych jest potężnym narzędziem do zarządzania dużymi ilościami danych w ustrukturyzowany i zorganizowany sposób. Poprzez użycie tabel z wierszami i kolumnami oraz ustanowienie relacji między nimi, relacyjna baza danych może efektywnie przechowywać i pobierać informacje dla różnych zastosowań. Zastosowanie języka SQL jako standardowego języka zarządzania relacyjnymi bazami danych ułatwiło programistom i użytkownikom interakcję z danymi i manipulowanie nimi. Wraz z ciągłym rozwojem aplikacji opartych na danych, znaczenie zrozumienia i wykorzystania relacyjnych baz danych będzie tylko rosło. Niezależnie od tego, czy jesteś programistą, analitykiem danych, czy po prostu kimś, kto chce skuteczniej zarządzać swoimi informacjami, poznanie relacyjnych baz danych może być wartościową inwestycją Twojego czasu i wysiłku.
Relacyjna baza danych jest rodzajem bazy danych, która organizuje dane w jedną lub więcej tabel lub relacji opartych na określonym zestawie reguł. Tabele są połączone lub powiązane przez wspólne pole lub klucz, co pozwala użytkownikom na łatwy dostęp i manipulację danymi.
Zalety korzystania z Relacyjnej Bazy Danych obejmują:
Składniki Relacyjnej Bazy Danych obejmują:
Rodzaje kluczy używanych w Relacyjnej Bazie Danych obejmują:
Klucz główny jest unikalnym identyfikatorem dla każdego wiersza lub rekordu w tabeli. Jest on używany do zapewnienia integralności danych oraz do łączenia danych pomiędzy wieloma tabelami.
Klucz obcy jest polem w tabeli, które odnosi się do klucza głównego w innej tabeli. Jest on używany do tworzenia relacji między tabelami.
Klucz kandydujący jest unikalnym identyfikatorem dla każdego wiersza lub rekordu w tabeli. Jest on używany do określenia klucza głównego dla tabeli.
Klucz złożony jest kombinacją dwóch lub więcej pól, które razem służą jako unikalny identyfikator dla każdego wiersza lub rekordu w tabeli.
Normalizacja jest procesem organizowania danych w bazie danych w celu zmniejszenia redundancji i poprawy integralności danych. Polega ona na rozbiciu dużych tabel na mniejsze, bardziej wyspecjalizowane tabele i ustanowieniu relacji między nimi.
Denormalizacja to dodawanie zbędnych danych do bazy danych w celu poprawy wydajności. Polega ona na powielaniu danych w wielu tabelach, aby uniknąć kosztownych połączeń i zapytań.
Przykłady Relacyjnych Systemów Zarządzania Bazą Danych obejmują:
Structured Query Language (SQL) jest językiem programowania używanym do komunikacji z relacyjnymi bazami danych. Jest on używany do tworzenia, modyfikowania i pobierania danych z baz danych.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


