
Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahren Sie, was eine relationale Datenbank ist und wie sie funktioniert. Entdecken Sie, wie sie Ihnen helfen kann, Ihre Daten effizient zu organisieren und zu verwalten.

Eine relationale Datenbank ist ein grundlegendes Konzept in der Welt der Datenverwaltung. Es handelt sich dabei um einen Datenbanktyp, der Daten mithilfe von Tabellen und Beziehungen zwischen ihnen speichert und verwaltet. In der heutigen datengesteuerten Welt verlassen sich Unternehmen und Organisationen jeder Größe auf relationale Datenbanken, um große Datenmengen effizient zu speichern, zu organisieren und zu verwalten.
Das relationale Datenbankmodell wurde erstmals in den 1970er Jahren von Edgar F. Codd, einem britischen Informatiker, vorgeschlagen. Seitdem hat es sich zum vorherrschenden Datenbankmodell entwickelt und wird in verschiedenen Anwendungen eingesetzt, von ERP-Systemen (Enterprise Resource Planning) bis hin zu E-Commerce-Websites und mobilen Anwendungen.
In diesem Artikel werden wir uns mit einer relationalen Datenbank, ihrer Funktionsweise sowie ihren Vorteilen und Einschränkungen befassen. Außerdem werden wir die verschiedenen Komponenten einer relationalen Datenbank wie Tabellen, Schlüssel und Beziehungen besprechen und wie sie zusammenarbeiten, um Daten zu verwalten. Am Ende dieses Artikels werden Sie ein solides Verständnis von relationalen Datenbanken und ihrer Rolle in der modernen Datenverwaltung haben.
Eine relationale Datenbank ist ein Datenbanktyp, der Daten in einer oder mehreren Tabellen oder Relationen organisiert, von denen jede einen eindeutigen Namen hat und aus einer Reihe von Zeilen und Spalten besteht. Die Daten in einer relationalen Datenbank sind strukturiert und organisiert, so dass sie leicht zu suchen, abzurufen und zu verwalten sind.
In einer relationalen Datenbank werden die Daten normalerweise in normalisierter Form gespeichert. Die Daten sind in kleinere, zusammenhängende Tabellen unterteilt, die jeweils einen eindeutigen Schlüssel oder Bezeichner haben. Die Beziehungen zwischen diesen Tabellen werden durch die Verwendung von Fremdschlüsseln definiert, die die Daten in einer Tabelle mit den Daten in einer anderen Tabelle verknüpfen.
Relationale Datenbanken sind in verschiedenen Anwendungen weit verbreitet, darunter Geschäfts- und Finanzsysteme, wissenschaftliche Forschung und elektronischer Handel. Sie bieten eine flexible und skalierbare Möglichkeit, große Datenmengen zu speichern und zu verwalten und gleichzeitig die Integrität und Konsistenz der Daten durch Einschränkungen wie Primär- und Fremdschlüssel zu gewährleisten.
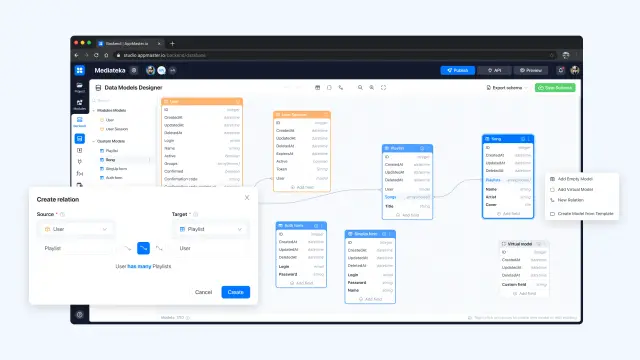
AppMaster verwendet relationale Datenbanken. Es verwendet das DBMS Postgres. AppMaster-Benutzer können jedes Schema relationaler Datenbanken erstellen, einschließlich vieler Arten von Feldern und Beziehungen. Die Benutzer können eine unbegrenzte Anzahl von Modellen, Beziehungen und Feldern erstellen. Jedes Mal, wenn sie das Datenschema ändern und es speichern, schreibt AppMaster automatisch eine Migration für die bestehenden Schemata mit UPD. Das heißt, wenn ein Benutzer eine neue Version seiner Anwendung mit einer geänderten Datenbank einspielt, migriert die Anwendungsbinärdatei automatisch das alte Datenbankschemaformat in das neue Format, ohne dass die Daten verloren gehen.
Relationale Datenbanken sind mit Hilfe von Tabellen strukturiert, die auch als Relationen bezeichnet werden. Jede Tabelle besteht aus Zeilen und Spalten, wobei jede Zeile einen einzelnen Datensatz oder eine Instanz von Daten darstellt und jede Spalte ein bestimmtes Attribut oder Feld der Daten repräsentiert. Ein Satz von Attributen oder Datentypen, wie Text, Zahl, Datum oder Boolesche Werte, definiert die Spalten in einer Tabelle. Jede Spalte hat auch einen eindeutigen Namen, der hilft, den in dieser Spalte gespeicherten Datentyp zu identifizieren.
Die Zeilen in einer Tabelle stellen einzelne Datensätze oder Instanzen von Daten dar. Jede Zeile hat einen eindeutigen Bezeichner, der als Primärschlüssel bezeichnet wird. Der Primärschlüssel wird verwendet, um Datensätze zwischen verschiedenen Tabellen in der Datenbank zu verknüpfen. Die Beziehungen zwischen Tabellen in einer relationalen Datenbank werden durch Fremdschlüssel definiert. Ein Fremdschlüssel ist eine Spalte in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist. Auf diese Weise können verwandte Daten miteinander verknüpft und aus verschiedenen Tabellen in der Datenbank abgerufen werden.
Neben Tabellen verwenden relationale Datenbanken auch Einschränkungen (Constraints), um die Integrität und Konsistenz der Daten zu gewährleisten. Constraints sind Regeln oder Bedingungen, die erfüllt sein müssen, bevor Daten in die Datenbank eingefügt, aktualisiert oder gelöscht werden können. Beispiele für Constraints sind Primärschlüssel, Fremdschlüssel, Unique Constraints und Check Constraints.
Das relationale Modell ist ein Datenmodell, das für den Entwurf und die Verwaltung von Daten in einer relationalen Datenbank verwendet wird. Das relationale Modell wurde 1970 von Edgar F. Codd eingeführt und hat sich seither zum am häufigsten verwendeten Datenmodell für moderne Datenbanken entwickelt.
Das relationale Modell basiert auf dem Konzept der Tabellen, die auch als Relationen bezeichnet werden. Jede Tabelle in der Datenbank stellt eine Sammlung von zusammenhängenden Daten dar, und jede Zeile in der Tabelle stellt einen einzelnen Datensatz oder eine Instanz dieser Daten dar. Jede Spalte in der Tabelle steht für ein bestimmtes Attribut oder Feld der Daten.
Die Beziehungen zwischen den Tabellen in der Datenbank werden durch Schlüssel definiert. Ein Primärschlüssel ist eine Spalte oder eine Gruppe von Spalten in einer Tabelle, die jede Zeile in dieser Tabelle eindeutig identifiziert. Ein Fremdschlüssel ist eine Spalte in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist, so dass verwandte Daten über verschiedene Tabellen in der Datenbank hinweg verknüpft werden können.
Das relationale Modell unterstützt auch Operationen zur Abfrage und Manipulation von Daten in der Datenbank, wie SELECT, INSERT, UPDATE und DELETE. Diese Operationen werden mit einer speziellen Sprache, der Structured Query Language (SQL), durchgeführt, die Abfragen und Anweisungen definiert, die mit der Datenbank interagieren.
Einer der Hauptvorteile des relationalen Modells ist seine Flexibilität und Skalierbarkeit. Tabellen können hinzugefügt, entfernt oder geändert werden, um veränderten Datenanforderungen gerecht zu werden, und die Beziehungen zwischen den Tabellen können bei Bedarf einfach definiert oder aktualisiert werden. Darüber hinaus bietet das relationale Modell eine konsistente und standardisierte Möglichkeit, Daten zu organisieren und zu verwalten, was die Pflege und Aktualisierung großer und komplexer Datenbanken im Laufe der Zeit erleichtert.
Relationale Datenbankmanagementsysteme (RDBMS) bieten zahlreiche Vorteile, von denen einige die folgenden sind
RDBMS bieten eine robuste und zuverlässige Möglichkeit zur Verwaltung von Daten und werden in einer Vielzahl von Anwendungen eingesetzt, darunter Geschäfts- und Finanzsysteme, wissenschaftliche Forschung und E-Commerce.
Das relationale Modell ist ein Datenmodell, das dazu beiträgt, die Datenkonsistenz in einem Datenbanksystem zu gewährleisten. Das Modell basiert auf dem Konzept von Tabellen oder Relationen, wobei jede Tabelle eine Sammlung von zusammenhängenden Daten darstellt und jede Zeile in der Tabelle einen einzelnen Datensatz oder eine Instanz dieser Daten repräsentiert. Jede Spalte in der Tabelle steht für ein bestimmtes Attribut oder Feld der Daten.
Die Datenkonsistenz bezieht sich auf die Genauigkeit und Zuverlässigkeit der in einer Datenbank gespeicherten Daten. Im relationalen Modell wird die Datenkonsistenz durch die Verwendung von Einschränkungen (Constraints) gewährleistet. Constraints sind Regeln oder Bedingungen, die erfüllt sein müssen, bevor Daten in eine Tabelle eingefügt, aktualisiert oder aus ihr gelöscht werden können. Im relationalen Modell können mehrere Arten von Beschränkungen verwendet werden, z. B. Primärschlüssel, Fremdschlüssel und Prüfbeschränkungen.
Ein Primärschlüssel ist ein eindeutiger Bezeichner für jede Zeile in einer Tabelle. Er stellt sicher, dass jeder Datensatz in der Tabelle identifiziert werden kann und der Zugriff darauf ohne Verwechslungen oder Fehler möglich ist. Ein Fremdschlüssel ist eine Spalte in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist. Er stellt sicher, dass zusammengehörige Daten in verschiedenen Tabellen korrekt verknüpft werden. Prüfbeschränkungen werden verwendet, um sicherzustellen, dass Datenwerte bestimmte Kriterien oder Bedingungen erfüllen.
Neben Constraints unterstützt das relationale Modell auch Transaktionen. Eine Transaktion ist eine Reihe von Datenbankoperationen, die zusammen als eine einzige Arbeitseinheit ausgeführt werden. Wenn ein Teil der Transaktion fehlschlägt, wird die gesamte Transaktion rückgängig gemacht, so dass die Konsistenz der Datenbank gewährleistet bleibt.
Die Verwendung von Beschränkungen und Transaktionen im relationalen Modell trägt dazu bei, die Datenkonsistenz in einer Datenbank zu gewährleisten. Constraints stellen sicher, dass die Daten konsistent und zuverlässig eingegeben und gespeichert werden, während Transaktionen gewährleisten, dass Datenänderungen auf atomare und konsistente Weise vorgenommen werden.
Darüber hinaus implementieren RDBMS einen Mechanismus namens "ACID"-Eigenschaften, der die Zuverlässigkeit von Transaktionen gewährleistet. ACID steht für Atomarität, Konsistenz, Isolation und Dauerhaftigkeit. Atomarität stellt sicher, dass eine Transaktion als eine einzige Arbeitseinheit behandelt wird, was bedeutet, dass alle Änderungen übertragen werden oder gar keine. Konsistenz gewährleistet, dass die Datenbank nach jeder Transaktion in einem konsistenten Zustand bleibt. Isolation gewährleistet, dass mehrere Transaktionen gleichzeitig ausgeführt werden können, ohne sich gegenseitig zu beeinträchtigen. Dauerhaftigkeit gewährleistet, dass Änderungen an der Datenbank auch bei einem Systemausfall oder einer Systemunterbrechung erhalten bleiben.
Das relationale Modell bietet eine robuste und zuverlässige Möglichkeit, Daten zu verwalten und die Datenkonsistenz in einer Datenbank zu gewährleisten. Durch die Erzwingung der Datenkonsistenz trägt das relationale Modell zur Aufrechterhaltung der Datengenauigkeit und -zuverlässigkeit bei, was für eine Vielzahl von Anwendungen entscheidend ist.
Commitment und Atomarität sind zwei Schlüsselkonzepte in Datenbanksystemen, insbesondere im Zusammenhang mit der Transaktionsverarbeitung. Eine Transaktion ist eine Folge von Datenbankoperationen, die als eine einzige logische Arbeitseinheit behandelt werden. Transaktionen können mehrere Operationen umfassen, z. B. das Lesen, Schreiben und Aktualisieren von Daten, und sie werden häufig verwendet, um sicherzustellen, dass Datenbankänderungen konsistent und zuverlässig durchgeführt werden.
Atomarität bezieht sich auf die Eigenschaft einer Transaktion, die sicherstellt, dass alle ihre Operationen als eine einzige, unteilbare Arbeitseinheit behandelt werden. Das bedeutet, dass entweder alle Vorgänge in der Transaktion erfolgreich abgeschlossen werden oder keiner von ihnen. Wenn ein Teil einer Transaktion fehlschlägt oder ein Fehler auftritt, wird die gesamte Transaktion rückgängig gemacht, und alle während der Transaktion an der Datenbank vorgenommenen Änderungen werden rückgängig gemacht.
Commitment bezeichnet die Eigenschaft einer Transaktion, die sicherstellt, dass ihre Änderungen nach erfolgreichem Abschluss dauerhaft in der Datenbank gespeichert werden. Nachdem eine Transaktion bestätigt wurde, können die Änderungen nicht mehr rückgängig gemacht werden. Das Commitment wird in der Regel durch eine Commit-Anweisung oder einen ähnlichen Mechanismus implementiert, der das Ende der Transaktion signalisiert und die Speicherung der Änderungen in der Datenbank bewirkt.
Die Kombination von Atomarität und Commitment gewährleistet, dass Datenbanktransaktionen zuverlässig und konsistent sind. Atomarität stellt sicher, dass Transaktionen in einer Alles-oder-Nichts-Weise ausgeführt werden, was dazu beiträgt, Dateninkonsistenzen oder -beschädigungen zu verhindern. Das Commitment stellt sicher, dass nach dem erfolgreichen Abschluss einer Transaktion die Änderungen dauerhaft sind und andere Transaktionen oder Anwendungen sich darauf verlassen können.
In Datenbanksystemen werden Atomarität und Commitment häufig durch einen Transaktionsmanager oder ein Transaktionsverarbeitungssystem erreicht, das für die Koordinierung und Verwaltung von Transaktionen zuständig ist. Der Transaktionsmanager stellt sicher, dass die Transaktionen atomar und konsistent ausgeführt und ihre Änderungen nach erfolgreichem Abschluss in der Datenbank gespeichert werden.
ACID-Eigenschaften (Atomicity, Consistency, Isolation, and Durability) sind eine Reihe von Merkmalen, die die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen gewährleisten. Relationale Datenbankmanagementsysteme (RDBMS) sind so konzipiert, dass sie ACID-Eigenschaften unterstützen, die für das ordnungsgemäße Funktionieren vieler Anwendungen und Systeme, die auf Daten angewiesen sind, entscheidend sind.
Atomarität bezieht sich auf die Idee, dass eine Transaktion als eine einzige, unteilbare Arbeitseinheit behandelt werden sollte. Das bedeutet, dass, wenn ein Teil einer Transaktion fehlschlägt, die gesamte Transaktion rückgängig gemacht wird und alle während der Transaktion an der Datenbank vorgenommenen Änderungen rückgängig gemacht werden müssen. Atomarität gewährleistet, dass Datenbankänderungen konsistent und zuverlässig durchgeführt werden, ohne dass es zu teilweisen oder unvollständigen Aktualisierungen kommt.
Konsistenz bedeutet, dass eine Transaktion die Datenbank in einem konsistenten Zustand verlassen sollte, in dem alle Daten den definierten Regeln und Einschränkungen entsprechen. Das bedeutet, dass eine Transaktion keine der Integritätsbeschränkungen der Datenbank verletzen darf, wie z. B. eindeutige Schlüssel oder Fremdschlüssel. Die Konsistenz gewährleistet, dass die Datenbank zuverlässig und genau bleibt.
Isolation bedeutet, dass mehrere Transaktionen gleichzeitig ausgeführt werden können, ohne sich gegenseitig zu stören. Die Isolierung stellt sicher, dass die Auswirkungen einer Transaktion für andere Transaktionen nicht sichtbar sind, bis die erste Transaktion abgeschlossen ist. Diese Eigenschaft verhindert, dass Dateninkonsistenzen und Konflikte entstehen, wenn mehrere Transaktionen gleichzeitig versuchen, auf dieselben Daten zuzugreifen oder sie zu ändern.
Dauerhaftigkeit bezieht sich auf die Idee, dass die Änderungen einer Transaktion, sobald sie abgeschlossen ist, dauerhaft und beständig sein sollten, selbst im Falle eines Systemausfalls. Dauerhaftigkeit wird in der Regel durch Techniken wie Write-ahead-Logging erreicht, bei dem alle während einer Transaktion vorgenommenen Änderungen in einer Protokolldatei aufgezeichnet werden, bevor sie auf die Datenbank angewendet werden. Dadurch wird sichergestellt, dass selbst bei einem Systemabsturz oder Stromausfall die während der Transaktion vorgenommenen Änderungen wiederhergestellt werden können.
RDBMS-Systeme wie MySQL, Oracle und SQL Server bieten integrierte Unterstützung für ACID-Eigenschaften, die sicherstellen, dass Datenbanktransaktionen zuverlässig und konsistent ausgeführt werden. Diese Eigenschaften tragen dazu bei, die Integrität und Zuverlässigkeit der Datenbank zu gewährleisten, wodurch sie sich für eine Vielzahl von Anwendungen eignen, die auf genaue und konsistente Daten angewiesen sind.
Gespeicherte Prozeduren sind Programme, die in einem relationalen Datenbankmanagementsystem (RDBMS) gespeichert sind und auf der Serverseite ausgeführt werden. Sie werden verwendet, um komplexe Operationen mit den in der Datenbank gespeicherten Daten durchzuführen und können von Anwendungsprogrammen oder direkt vom Datenbankmanagementsystem aus aufgerufen werden.
Gespeicherte Prozeduren werden in der Regel in einer Programmiersprache geschrieben, die vom Datenbankmanagementsystem unterstützt wird, wie z. B. SQL oder PL/SQL. Sie werden kompiliert und in der Datenbank gespeichert und können ausgeführt werden, indem man sie namentlich aufruft.
Gespeicherte Prozeduren bieten mehrere Vorteile in einer relationalen Datenbankumgebung. Ein Vorteil ist, dass sie die Leistung verbessern können, indem sie die Datenmenge reduzieren, die zwischen der Datenbank und der Anwendung übertragen werden muss. Dies liegt daran, dass gespeicherte Prozeduren auf der Serverseite ausgeführt werden, was den Netzwerkverkehr und die Latenzzeit reduziert.
Gespeicherte Prozeduren bieten auch ein gewisses Maß an Sicherheit und Zugriffskontrolle. Sie können zur Durchsetzung von Geschäftsregeln und Sicherheitsrichtlinien verwendet werden und den Zugriff auf sensible Daten einschränken, indem sie nur von autorisierten Benutzern ausgeführt werden dürfen. Da Stored Procedures vorkompiliert und in der Datenbank gespeichert sind, sind sie außerdem weniger anfällig für SQL-Injection-Angriffe als Ad-hoc-SQL-Anweisungen.
Ein weiterer Vorteil von Stored Procedures ist, dass sie die Konsistenz und Wartbarkeit der Datenbank verbessern können. Durch die Kapselung komplexer Geschäftslogik in einer gespeicherten Prozedur können Anwendungsentwickler sicherstellen, dass die Logik in der gesamten Datenbank konsistent angewendet wird. Außerdem können gespeicherte Prozeduren unabhängig vom Anwendungscode aktualisiert werden, was die Wartung und Aktualisierung der Datenbanklogik erleichtert.
Zusammenfassend lässt sich sagen, dass Stored Procedures in einer relationalen Datenbankumgebung mehrere Vorteile bieten, darunter verbesserte Leistung, Sicherheit, Zugriffskontrolle, Konsistenz und Wartbarkeit. Sie sind ein leistungsfähiges Werkzeug für Entwickler und Datenbankadministratoren und werden in modernen Datenbanksystemen häufig eingesetzt.
Die Gleichzeitigkeitskontrolle ist ein entscheidender Aspekt von relationalen Datenbankmanagementsystemen (RDBMS), der sicherstellt, dass mehrere Transaktionen, die auf dieselben Daten zugreifen, gleichzeitig ausgeführt werden können, ohne falsche Ergebnisse zu produzieren. Eine der Techniken, die zur Gleichzeitigkeitskontrolle eingesetzt werden, ist die Datenbanksperre, bei der Sperren auf Datenbankobjekte wie Tabellen, Zeilen oder Spalten erworben und freigegeben werden.
Das Sperren ist ein Mechanismus, der den gleichzeitigen Zugriff auf dieselben Daten durch mehrere Transaktionen verhindert. Wenn eine Transaktion den Zugriff auf ein bestimmtes Datenbankobjekt, z. B. eine Zeile in einer Tabelle, anfordert, erwirbt sie eine Sperre für dieses Objekt. Die Sperre verhindert, dass andere Transaktionen auf das Objekt zugreifen, bis die erste Transaktion die Sperre aufhebt. Sobald die Transaktion abgeschlossen ist, wird die Sperre freigegeben, so dass andere Transaktionen auf das Objekt zugreifen können.
Bei den Datenbanksperren gibt es zwei Kategorien: Lesesperren und Schreibsperren. Gemeinsame Sperren ermöglichen es mehreren Transaktionen, dieselben Daten gleichzeitig zu lesen, während exklusive Sperren den Zugriff anderer Transaktionen auf die Daten blockieren, bis die Sperre aufgehoben wird. Wenn eine Transaktion eine exklusive Sperre für ein Datenbankobjekt erwirbt, hat sie die volle Kontrolle über das Objekt und kann es nach Bedarf ändern.
Datenbanksperren sind für die Aufrechterhaltung der Datenkonsistenz bei gleichzeitigen Datenbanktransaktionen unerlässlich. Sie kann jedoch auch zu Leistungsproblemen führen, insbesondere in Umgebungen mit hoher Parallelität. Wenn zu viele Transaktionen auf die Freigabe von Sperren warten, kann dies zu langen Wartezeiten und einem geringeren Durchsatz führen.
Um dieses Problem zu lösen, verwenden viele RDBMS-Systeme verschiedene Sperrtechniken, wie z. B. optimistisches Sperren, das mehreren Transaktionen den gleichzeitigen Zugriff auf dieselben Daten ermöglicht und Konflikte erst dann löst, wenn sie auftreten. Ein anderer Ansatz ist die Verwendung von Multi-Versions-Concurrency-Control (MVCC), bei der mehrere Versionen von Daten in der Datenbank erstellt werden, so dass mehrere Transaktionen ohne Sperren gleichzeitig Daten lesen und ändern können.
Datenbanksperren sind eine wichtige Technik zur Aufrechterhaltung der Konsistenz bei gleichzeitigen Datenbanktransaktionen. Obwohl es zu Leistungsproblemen führen kann, verwenden moderne RDBMS-Systeme verschiedene Sperrtechniken und -algorithmen, um die Wartezeiten zu minimieren und die Gleichzeitigkeit zu verbessern.
Bei der Auswahl einer relationalen Datenbank sind mehrere Faktoren zu berücksichtigen, u. a:
Bei der Auswahl einer relationalen Datenbank müssen mehrere Faktoren berücksichtigt werden, darunter Skalierbarkeit, Leistung, Verfügbarkeit, Sicherheit, Benutzerfreundlichkeit, Kompatibilität, Kosten, Community, Funktionen und Möglichkeiten sowie Anbieterunterstützung. Eine sorgfältige Bewertung dieser Faktoren kann dazu beitragen, dass eine Datenbank ausgewählt wird, die den Anforderungen der Anwendung entspricht und einen zuverlässigen, effizienten und sicheren Datenzugriff ermöglicht.
Die Geschichte der relationalen Datenbanken beginnt in den späten 1960er Jahren, als ein Informatiker namens Edgar Codd das Konzept eines relationalen Modells für Datenbanken vorschlug. Codds Idee war es, Daten in Tabellen oder Relationen zu organisieren, die jeweils aus Zeilen und Spalten bestehen, wobei jede Zeile einen eindeutigen Datensatz und jede Spalte ein Datenattribut darstellt. Außerdem schlug er eine Reihe von mathematischen Prinzipien, die so genannte relationale Algebra, für die Bearbeitung und Abfrage der Daten vor.
In den frühen 1970er Jahren entwickelten die IBM-Forscher Donald Chamberlin und Raymond Boyce eine Sprache für die Abfrage relationaler Datenbanken namens Structured English Query Language (SEQUEL), die später in SQL umbenannt wurde. SQL wurde zur Standardsprache für relationale Datenbanken und ist auch heute noch weit verbreitet.
In den späten 1970er und frühen 1980er Jahren wurden mehrere kommerzielle relationale Datenbanksysteme entwickelt, darunter IBMs System R, Oracle und Ingres. Diese Datenbanken implementierten das relationale Modell und boten Funktionen wie Unterstützung für Transaktionen, Indizierung und Abfrageoptimierung.
In den 1990er Jahren wuchs die Beliebtheit relationaler Datenbanken mit dem Aufkommen von Client-Server-Computing und dem Internet weiter an. Relationale Datenbanken bieten eine robuste und skalierbare Plattform für die Speicherung und den Abruf von Daten und unterstützen Anwendungen von Finanzsystemen bis hin zu E-Commerce-Sites.
In den frühen 2000er Jahren führte das Aufkommen von Open-Source-Software zur Entwicklung mehrerer beliebter relationaler Open-Source-Datenbanken, darunter MySQL, PostgreSQL und SQLite. Diese Datenbanken boten eine kostengünstige Alternative zu kommerziellen Datenbanken und wurden von vielen Entwicklern und Unternehmen angenommen.
Heute sind relationale Datenbanken nach wie vor der am häufigsten verwendete Datenbanktyp, wobei neue Funktionen und Möglichkeiten wie verteiltes Rechnen, Cloud-Integration und Unterstützung für maschinelles Lernen hinzugekommen sind. Auch wenn andere Datenbanktypen wie NoSQL- und Graphdatenbanken auf den Markt gekommen sind, bleiben relationale Datenbanken für viele Unternehmen ein wichtiger Bestandteil der Dateninfrastruktur.
Zusammenfassend lässt sich sagen, dass eine relationale Datenbank ein leistungsstarkes Tool für die strukturierte und organisierte Verwaltung großer Datenmengen ist. Durch die Verwendung von Tabellen mit Zeilen und Spalten und die Herstellung von Beziehungen zwischen ihnen kann eine relationale Datenbank Informationen für eine Vielzahl von Anwendungen effizient speichern und abrufen. Die Verwendung von SQL als Standardsprache für die Verwaltung relationaler Datenbanken hat es Entwicklern und Benutzern erleichtert, mit Daten zu interagieren und sie zu manipulieren. Mit dem kontinuierlichen Wachstum datengesteuerter Anwendungen wird die Bedeutung des Verständnisses und der Nutzung relationaler Datenbanken weiter zunehmen. Ganz gleich, ob Sie Programmierer, Datenanalyst oder einfach nur jemand sind, der seine Informationen effektiver verwalten möchte, die Beschäftigung mit relationalen Datenbanken kann eine wertvolle Investition in Ihre Zeit und Mühe sein.
Eine relationale Datenbank ist ein Datenbanktyp, der Daten in einer oder mehreren Tabellen oder Beziehungen organisiert, die auf einem bestimmten Satz von Regeln basieren. Die Tabellen sind durch ein gemeinsames Feld oder einen gemeinsamen Schlüssel miteinander verbunden, so dass die Benutzer leicht auf die Daten zugreifen und sie manipulieren können.
Die Vorteile der Verwendung einer relationalen Datenbank sind unter anderem:
Zu den Komponenten einer relationalen Datenbank gehören:
In einer relationalen Datenbank werden unter anderem folgende Arten von Schlüsseln verwendet:
Ein Primärschlüssel ist ein eindeutiger Bezeichner für jede Zeile oder jeden Datensatz in einer Tabelle. Er wird verwendet, um die Datenintegrität zu gewährleisten und um Daten über mehrere Tabellen hinweg zu verknüpfen.
Ein Fremdschlüssel ist ein Feld in einer Tabelle, das auf den Primärschlüssel einer anderen Tabelle verweist. Er wird verwendet, um Beziehungen zwischen Tabellen herzustellen.
Ein Kandidatenschlüssel ist ein eindeutiger Bezeichner für jede Zeile oder jeden Datensatz in einer Tabelle. Er wird verwendet, um den Primärschlüssel für die Tabelle zu bestimmen.
Ein zusammengesetzter Schlüssel ist eine Kombination aus zwei oder mehr Feldern, die zusammen als eindeutiger Bezeichner für jede Zeile oder jeden Datensatz in einer Tabelle dienen.
Unter Normalisierung versteht man den Prozess der Organisation von Daten in einer Datenbank, um Redundanzen zu verringern und die Datenintegrität zu verbessern. Dabei werden große Tabellen in kleinere, spezialisiertere Tabellen aufgeteilt und Beziehungen zwischen ihnen hergestellt.
Denormalisierung ist das Hinzufügen redundanter Daten zu einer Datenbank, um die Leistung zu verbessern. Dabei werden Daten über mehrere Tabellen hinweg dupliziert, um kostspielige Verknüpfungen und Abfragen zu vermeiden.
Beispiele für relationale Datenbankmanagementsysteme sind:
Structured Query Language (SQL) ist eine Programmiersprache, die für die Kommunikation mit relationalen Datenbanken verwendet wird. Sie wird zum Erstellen, Ändern und Abrufen von Daten aus Datenbanken verwendet.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


