
App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Scoprite cos'è e come funziona un database relazionale. Scoprite come può aiutarvi a organizzare e gestire i vostri dati in modo efficiente.

Un database relazionale è un concetto fondamentale nel mondo della gestione dei dati. È un tipo di database che memorizza e gestisce i dati utilizzando tabelle e relazioni tra di esse. Nell'odierno mondo guidato dai dati, le aziende e le organizzazioni di tutte le dimensioni si affidano ai database relazionali per archiviare, organizzare e gestire in modo efficiente grandi volumi di dati.
Il modello di database relazionale è stato proposto per la prima volta negli anni '70 da Edgar F. Codd, un informatico britannico. Da allora, è diventato il modello di database dominante ed è utilizzato in diverse applicazioni, dai sistemi di pianificazione delle risorse aziendali (ERP) ai siti web di e-commerce e alle applicazioni mobili.
In questo articolo esploreremo un database relazionale, il suo funzionamento e i suoi vantaggi e limiti. Parleremo anche dei diversi componenti di un database relazionale, come tabelle, chiavi e relazioni, e di come lavorano insieme per gestire i dati. Alla fine di questo articolo, avrete una solida conoscenza dei database relazionali e del loro ruolo nella gestione moderna dei dati.
Un database relazionale è un tipo di database che organizza i dati in una o più tabelle o relazioni, ognuna delle quali ha un nome univoco e consiste in un insieme di righe e colonne. I dati di un database relazionale sono strutturati e organizzati, il che ne facilita la ricerca, il recupero e la gestione.
In un database relazionale i dati sono tipicamente memorizzati in forma normalizzata. I dati sono suddivisi in tabelle più piccole e correlate, ciascuna con una chiave o un identificatore unico. Le relazioni tra queste tabelle sono definite attraverso l'uso di chiavi esterne, che collegano i dati di una tabella a quelli di un'altra.
I database relazionali sono ampiamente utilizzati in varie applicazioni, tra cui i sistemi aziendali e finanziari, la ricerca scientifica e il commercio elettronico. Offrono un modo flessibile e scalabile per memorizzare e gestire grandi quantità di dati, garantendo al contempo l'integrità e la coerenza dei dati attraverso vincoli, come le chiavi primarie e le chiavi esterne.
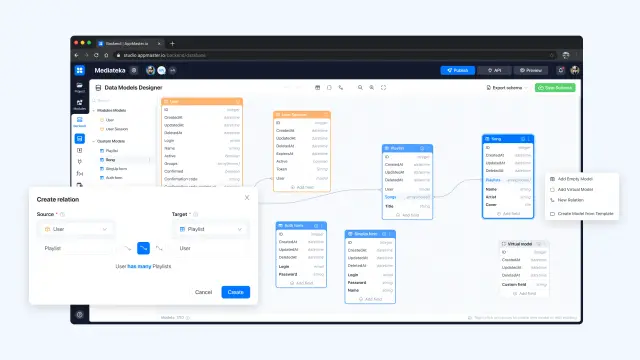
AppMaster utilizza database relazionali. Utilizza il DBMS Postgres. Gli utenti di AppMaster possono creare qualsiasi schema di database relazionale, compresi molti tipi di campi e relazioni. Gli utenti possono creare un numero illimitato di modelli, relazioni e campi. Ogni volta che modificano lo schema dei dati e lo salvano, AppMaster scrive automaticamente una migrazione per gli schemi esistenti con UPD. In altre parole, quando un utente invia una nuova versione della sua applicazione con un database modificato, il binario dell'applicazione migra automaticamente il vecchio formato dello schema del database al nuovo formato senza perdere i dati.
I database relazionali sono strutturati mediante tabelle, note anche come relazioni. Ogni tabella è composta da righe e colonne: ogni riga rappresenta un singolo record o istanza di dati e ogni colonna rappresenta uno specifico attributo o campo dei dati. Un insieme di attributi o tipi di dati, come testo, numero, data o booleano, definisce le colonne di una tabella. Ogni colonna ha anche un nome univoco, che aiuta a identificare il tipo di dati memorizzati in quella colonna.
Le righe di una tabella rappresentano singoli record o istanze di dati. Ogni riga ha un identificatore unico, chiamato chiave primaria. La chiave primaria viene utilizzata per collegare i record tra le diverse tabelle del database. Le relazioni tra le tabelle di un database relazionale sono definite mediante chiavi esterne. Una chiave esterna è una colonna di una tabella che fa riferimento alla chiave primaria di un'altra tabella. Ciò consente di collegare i dati correlati e di accedervi da tabelle diverse del database.
Oltre alle tabelle, i database relazionali utilizzano anche vincoli per garantire l'integrità e la coerenza dei dati. I vincoli sono regole o condizioni che devono essere soddisfatte prima che i dati possano essere inseriti, aggiornati o eliminati dal database. Esempi di vincoli sono le chiavi primarie, le chiavi esterne, i vincoli di unicità e i vincoli di controllo.
Il modello relazionale è un modello di dati utilizzato per progettare e gestire i dati in un database relazionale. Il modello relazionale è stato introdotto da Edgar F. Codd nel 1970 e da allora è diventato il modello di dati più utilizzato per i database moderni.
Il modello relazionale si basa sul concetto di tabelle, note anche come relazioni. Ogni tabella del database rappresenta una raccolta di dati correlati e ogni riga della tabella rappresenta un singolo record o istanza di tali dati. Ogni colonna della tabella rappresenta un attributo o un campo specifico dei dati.
Le relazioni tra le tabelle del database sono definite mediante chiavi. Una chiave primaria è una colonna o un insieme di colonne di una tabella che identifica in modo univoco ogni riga di quella tabella. Una chiave esterna è una colonna di una tabella che fa riferimento alla chiave primaria di un'altra tabella, consentendo di collegare dati correlati tra le diverse tabelle del database.
Il modello relazionale supporta anche operazioni di interrogazione e manipolazione dei dati nel database, come SELECT, INSERT, UPDATE e DELETE. Queste operazioni vengono eseguite utilizzando un linguaggio speciale chiamato Structured Query Language (SQL), che definisce le query e le istruzioni che interagiscono con il database.
Uno dei vantaggi principali del modello relazionale è la sua flessibilità e scalabilità. Le tabelle possono essere aggiunte, rimosse o modificate per adattarsi alle mutevoli esigenze dei dati e le relazioni tra le tabelle possono essere facilmente definite o aggiornate in base alle necessità. Inoltre, il modello relazionale fornisce un modo coerente e standardizzato di organizzare e gestire i dati, rendendo più facile la manutenzione e l'aggiornamento di database grandi e complessi nel tempo.
I sistemi di gestione dei database relazionali (RDBMS) offrono numerosi vantaggi, alcuni dei quali sono i seguenti:
Gli RDBMS offrono un modo robusto e affidabile di gestire i dati e sono ampiamente utilizzati in una varietà di applicazioni, tra cui sistemi aziendali e finanziari, ricerca scientifica e commercio elettronico.
Il modello relazionale è un modello di dati che aiuta a garantire la coerenza dei dati in un sistema di database. Il modello si basa sul concetto di tabelle o relazioni, dove ogni tabella rappresenta una raccolta di dati correlati e ogni riga della tabella rappresenta un singolo record o istanza di tali dati. Ogni colonna della tabella rappresenta un attributo o un campo specifico dei dati.
La coerenza dei dati si riferisce all'accuratezza e all'affidabilità dei dati memorizzati in un database. Nel modello relazionale, la coerenza dei dati è garantita dall'uso di vincoli. I vincoli sono regole o condizioni che devono essere soddisfatte prima che i dati possano essere inseriti, aggiornati o cancellati da una tabella. Nel modello relazionale si possono usare diversi tipi di vincoli, come le chiavi primarie, le chiavi esterne e i vincoli di controllo.
Una chiave primaria è un identificatore unico per ogni riga di una tabella. Garantisce che ogni record della tabella possa essere identificato e consultato senza confusione o errori. Una chiave esterna è una colonna di una tabella che fa riferimento alla chiave primaria di un'altra tabella. Assicura che i dati correlati in tabelle diverse siano collegati correttamente. I vincoli di controllo sono utilizzati per garantire che i valori dei dati soddisfino criteri o condizioni specifiche.
Oltre ai vincoli, il modello relazionale supporta le transazioni. Una transazione è una serie di operazioni di database eseguite insieme come un'unica unità di lavoro. Se una parte della transazione fallisce, l'intera transazione viene annullata, garantendo la coerenza del database.
L'uso di vincoli e transazioni nel modello relazionale aiuta a garantire la coerenza dei dati in un database. I vincoli garantiscono che i dati siano inseriti e memorizzati in modo coerente e affidabile, mentre le transazioni assicurano che le modifiche ai dati siano effettuate in modo atomico e coerente.
Inoltre, gli RDBMS implementano un meccanismo chiamato proprietà "ACID", che garantisce l'affidabilità delle transazioni. ACID sta per Atomicità, Consistenza, Isolamento e Durata. L'atomicità garantisce che una transazione sia trattata come una singola unità di lavoro, il che significa che tutte le modifiche vengono impegnate, oppure nessuna. La coerenza garantisce che il database rimanga in uno stato coerente dopo ogni transazione. L'isolamento garantisce che più transazioni possano essere eseguite simultaneamente senza interferire l'una con l'altra. La durata garantisce che le modifiche apportate al database persistano anche in caso di guasto o interruzione del sistema.
Il modello relazionale offre un modo robusto e affidabile di gestire i dati, garantendo la coerenza dei dati in un database. Applicando la coerenza dei dati, il modello relazionale contribuisce a mantenere l'accuratezza e l'affidabilità dei dati, che è fondamentale per un'ampia gamma di applicazioni.
L'impegno e l'atomicità sono due concetti chiave nei sistemi di database, in particolare nel contesto dell'elaborazione delle transazioni. Una transazione è una sequenza di operazioni di database che vengono trattate come una singola unità logica di lavoro. Le transazioni possono coinvolgere più operazioni, come la lettura, la scrittura e l'aggiornamento dei dati, e sono spesso utilizzate per garantire che le modifiche al database vengano effettuate in modo coerente e affidabile.
L'atomicità si riferisce alla proprietà di una transazione che garantisce che tutte le sue operazioni siano trattate come una singola unità di lavoro indivisibile. Ciò significa che o tutte le operazioni della transazione vengono completate con successo o nessuna di esse. Se una parte di una transazione fallisce o incontra un errore, l'intera transazione viene annullata e tutte le modifiche apportate al database durante la transazione vengono annullate.
L'impegno si riferisce alla proprietà di una transazione che garantisce che, una volta completata con successo, le sue modifiche vengano salvate in modo permanente nel database. Dopo il commit di una transazione, le sue modifiche non possono essere annullate o annullate. L'impegno è tipicamente implementato utilizzando una dichiarazione di commit o un meccanismo simile, che segnala la fine della transazione e fa sì che le sue modifiche vengano salvate nel database.
La combinazione di atomicità e impegno assicura che le transazioni del database siano affidabili e coerenti. L'atomicità assicura che le transazioni siano eseguite in modo "tutto o niente", il che aiuta a prevenire l'incoerenza o la corruzione dei dati. L'impegno garantisce che, una volta completata con successo una transazione, le sue modifiche siano permanenti e possano essere considerate da altre transazioni o applicazioni.
Nei sistemi di database, l'implementazione dell'atomicità e dell'impegno è spesso ottenuta attraverso un gestore di transazioni o un sistema di elaborazione delle transazioni, responsabile del coordinamento e della gestione delle transazioni. Il transaction manager assicura che le transazioni siano eseguite in modo atomico e coerente e che le loro modifiche siano impegnate nel database una volta completate con successo.
Le proprietà ACID (Atomicità, Consistenza, Isolamento e Durata) sono un insieme di caratteristiche che garantiscono l'affidabilità e la coerenza delle transazioni di database. I sistemi di gestione dei database relazionali (RDBMS) sono progettati per supportare le proprietà ACID, che sono fondamentali per il corretto funzionamento di molte applicazioni e sistemi che si basano sui dati.
L'atomicità si riferisce all'idea che una transazione debba essere trattata come una singola unità di lavoro indivisibile. Ciò significa che se una parte di una transazione fallisce, l'intera transazione deve essere annullata e tutte le modifiche apportate al database durante la transazione devono essere annullate. L'atomicità garantisce che le modifiche al database vengano effettuate in modo coerente e affidabile, senza aggiornamenti parziali o incompleti.
La coerenza si riferisce all'idea che una transazione debba lasciare il database in uno stato coerente in cui tutti i dati soddisfano le regole e i vincoli definiti. Ciò significa che una transazione non deve violare nessuno dei vincoli di integrità del database, come le chiavi uniche o le chiavi esterne. La coerenza garantisce che il database rimanga affidabile e preciso.
L'isolamento si riferisce all'idea che più transazioni debbano essere in grado di essere eseguite simultaneamente senza interferire l'una con l'altra. L'isolamento garantisce che gli effetti di una transazione non siano visibili alle altre transazioni fino al completamento della prima. Questa proprietà impedisce l'insorgere di incoerenze e conflitti tra i dati quando più transazioni tentano di accedere o modificare gli stessi dati contemporaneamente.
La durabilità si riferisce all'idea che una volta che una transazione è stata impegnata, le sue modifiche devono essere permanenti e persistenti, anche in caso di guasto del sistema. La durabilità è tipicamente implementata utilizzando tecniche come il write-ahead logging, in cui tutte le modifiche apportate durante una transazione vengono registrate in un file di log prima di essere applicate al database. In questo modo, anche se il sistema si blocca o subisce un'interruzione di corrente, le modifiche apportate durante la transazione possono essere recuperate.
I sistemi RDBMS come MySQL, Oracle e SQL Server offrono un supporto integrato per le proprietà ACID, assicurando che le transazioni del database vengano eseguite in modo affidabile e coerente. Queste proprietà contribuiscono a garantire l'integrità e l'affidabilità del database, rendendoli adatti a un'ampia gamma di applicazioni che si basano su dati accurati e coerenti.
Le stored procedures sono programmi memorizzati all'interno di un sistema di gestione di database relazionali (RDBMS) ed eseguiti sul lato server. Vengono utilizzate per eseguire operazioni complesse sui dati memorizzati nel database e possono essere richiamate da programmi applicativi o direttamente dal sistema di gestione del database.
Le stored procedure sono generalmente scritte in un linguaggio di programmazione supportato dal sistema di gestione del database, come SQL o PL/SQL. Vengono compilate e memorizzate nel database e possono essere eseguite chiamandole per nome.
Le procedure memorizzate offrono diversi vantaggi in un ambiente di database relazionale. Un vantaggio è che possono migliorare le prestazioni riducendo la quantità di dati da trasferire tra il database e l'applicazione. Le procedure memorizzate vengono infatti eseguite sul lato server, riducendo il traffico di rete e la latenza.
Le stored procedure forniscono anche un livello di sicurezza e di controllo degli accessi. Possono essere utilizzate per applicare le regole aziendali e i criteri di sicurezza e limitare l'accesso ai dati sensibili, consentendo l'esecuzione solo agli utenti autorizzati. Inoltre, poiché le stored procedure sono precompilate e memorizzate nel database, sono meno vulnerabili agli attacchi SQL injection rispetto alle istruzioni SQL ad hoc.
Un altro vantaggio delle stored procedure è che possono migliorare la coerenza e la manutenibilità del database. Incapsulando la logica aziendale complessa all'interno di una stored procedure, gli sviluppatori di applicazioni possono garantire che la logica sia applicata in modo coerente in tutto il database. Inoltre, le stored procedure possono essere aggiornate indipendentemente dal codice dell'applicazione, rendendo più semplice la manutenzione e l'aggiornamento della logica del database.
In sintesi, le stored procedure offrono diversi vantaggi in un ambiente di database relazionale, tra cui il miglioramento delle prestazioni, della sicurezza, del controllo degli accessi, della coerenza e della manutenibilità. Sono uno strumento potente per gli sviluppatori e gli amministratori di database e sono ampiamente utilizzate nei moderni sistemi di database.
Il controllo della concorrenza è un aspetto critico dei sistemi di gestione dei database relazionali (RDBMS) che garantisce che più transazioni che accedono agli stessi dati possano essere eseguite simultaneamente senza produrre risultati errati. Una delle tecniche utilizzate per ottenere il controllo della concorrenza è il blocco del database, che comporta l'acquisizione e il rilascio di blocchi su oggetti del database come tabelle, righe o colonne.
Il blocco è un meccanismo che impedisce l'accesso simultaneo agli stessi dati da parte di più transazioni. Quando una transazione richiede l'accesso a un particolare oggetto del database, come una riga di una tabella, acquisisce un blocco su quell'oggetto. Il blocco impedisce alle altre transazioni di accedere all'oggetto finché la prima transazione non rilascia il blocco. Una volta completata la transazione, il blocco viene rilasciato, consentendo alle altre transazioni di accedere all'oggetto.
Nel blocco dei database esistono due categorie: i blocchi condivisi e i blocchi esclusivi. I lock condivisi consentono a più transazioni di leggere gli stessi dati contemporaneamente, mentre i lock esclusivi bloccano l'accesso ai dati da parte di altre transazioni finché il lock non viene rilasciato. Quando una transazione acquisisce un blocco esclusivo su un oggetto del database, ha il pieno controllo sull'oggetto e può modificarlo come necessario.
Il blocco del database è essenziale per mantenere la coerenza dei dati nelle transazioni di database concorrenti. Tuttavia, può anche causare problemi di prestazioni, soprattutto in ambienti ad alta frequenza. Se troppe transazioni attendono il rilascio dei lock, possono verificarsi lunghi tempi di attesa e una riduzione del throughput.
Per risolvere questo problema, molti sistemi RDBMS utilizzano varie tecniche di blocco, come il blocco ottimistico, che consente a più transazioni di accedere agli stessi dati in modo simultaneo e risolve i conflitti solo quando si verificano. Un altro approccio consiste nell'utilizzare il controllo della concorrenza multi-versione (MVCC), che crea più versioni dei dati nel database, consentendo a più transazioni di leggere e modificare i dati in modo simultaneo senza bloccarli.
Il blocco del database è una tecnica fondamentale per mantenere la coerenza nelle transazioni concomitanti del database. Sebbene possa causare problemi di prestazioni, i moderni sistemi RDBMS utilizzano varie tecniche e algoritmi di locking per ridurre al minimo i tempi di attesa e migliorare la concorrenza.
Quando si sceglie un database relazionale, ci sono diversi fattori da considerare, tra cui:
La scelta di un database relazionale richiede la considerazione di diversi fattori, tra cui la scalabilità, le prestazioni, la disponibilità, la sicurezza, la facilità d'uso, la compatibilità, il costo, la comunità, le caratteristiche e le capacità e il supporto del fornitore. Un'attenta valutazione di questi fattori può contribuire a garantire la scelta di un database che soddisfi i requisiti dell'applicazione e fornisca un accesso affidabile, efficiente e sicuro ai dati.
La storia dei database relazionali inizia alla fine degli anni '60, quando un informatico di nome Edgar Codd propose il concetto di modello relazionale per i database. L'idea di Codd era quella di organizzare i dati in tabelle o relazioni, ciascuna composta da righe e colonne, con ogni riga che rappresentava un record unico e ogni colonna che rappresentava un attributo dei dati. Egli propose anche un insieme di principi matematici, noti come algebra relazionale, per manipolare e interrogare i dati.
All'inizio degli anni '70, i ricercatori IBM Donald Chamberlin e Raymond Boyce svilupparono un linguaggio per l'interrogazione dei database relazionali chiamato Structured English Query Language (SEQUEL), in seguito ribattezzato SQL. SQL è diventato il linguaggio standard per i database relazionali ed è ancora oggi ampiamente utilizzato.
Tra la fine degli anni '70 e l'inizio degli anni '80 sono stati sviluppati diversi sistemi di database relazionali commerciali, tra cui System R di IBM, Oracle e Ingres. Questi database implementavano il modello relazionale e fornivano funzionalità quali il supporto per le transazioni, l'indicizzazione e l'ottimizzazione delle query.
Negli anni '90, la popolarità dei database relazionali ha continuato a crescere con l'emergere dell'informatica client-server e di Internet. I database relazionali forniscono una piattaforma robusta e scalabile per l'archiviazione e il recupero dei dati, supportando applicazioni che vanno dai sistemi finanziari ai siti di e-commerce.
All'inizio degli anni 2000, l'ascesa del software open-source ha portato allo sviluppo di numerosi database relazionali open-source, tra cui MySQL, PostgreSQL e SQLite. Questi database hanno rappresentato un'alternativa economica ai database commerciali e sono stati ampiamente adottati da sviluppatori e organizzazioni.
Oggi i database relazionali continuano a essere il tipo di database più utilizzato, con nuove caratteristiche e capacità come il calcolo distribuito, l'integrazione nel cloud e il supporto all'apprendimento automatico. Anche se sono emersi altri tipi di database, come i database NoSQL e a grafo, i database relazionali rimangono una parte fondamentale dell'infrastruttura dei dati per molte organizzazioni.
In conclusione, un database relazionale è uno strumento potente per gestire grandi quantità di dati in modo strutturato e organizzato. Utilizzando tabelle con righe e colonne e stabilendo relazioni tra di esse, un database relazionale può memorizzare e recuperare informazioni in modo efficiente per una varietà di applicazioni. L'uso di SQL come linguaggio standard per la gestione dei database relazionali ha facilitato l'interazione e la manipolazione dei dati da parte di sviluppatori e utenti. Con la continua crescita delle applicazioni basate sui dati, l'importanza di comprendere e utilizzare i database relazionali continuerà a crescere. Che siate programmatori, analisti di dati o semplicemente persone che desiderano gestire le proprie informazioni in modo più efficace, imparare a conoscere i database relazionali può essere un investimento prezioso per il vostro tempo e il vostro impegno.
Un database relazionale è un tipo di database che organizza i dati in una o più tabelle o relazioni basate su un insieme specifico di regole. Le tabelle sono collegate o correlate da un campo o da una chiave comune, consentendo agli utenti di accedere e manipolare facilmente i dati.
I vantaggi dell'utilizzo di un database relazionale includono:
I componenti di un database relazionale includono
I tipi di chiavi utilizzate in un database relazionale includono:
Una chiave primaria è un identificatore unico per ogni riga o record di una tabella. Viene utilizzata per garantire l'integrità dei dati e per collegare i dati tra più tabelle.
Una chiave esterna è un campo di una tabella che fa riferimento alla chiave primaria di un'altra tabella. Si usa per stabilire relazioni tra le tabelle.
Una chiave candidata è un identificatore unico per ogni riga o record di una tabella. Viene utilizzata per determinare la Chiave primaria della tabella.
Una chiave composta è una combinazione di due o più campi che insieme servono come identificatore unico per ogni riga o record di una tabella.
La normalizzazione è il processo di organizzazione dei dati in un database per ridurre la ridondanza e migliorare l'integrità dei dati. Comporta la suddivisione di tabelle di grandi dimensioni in tabelle più piccole e specializzate e la creazione di relazioni tra di esse.
La denormalizzazione consiste nell'aggiungere dati ridondanti a un database per migliorare le prestazioni. Si tratta di duplicare i dati su più tabelle per evitare costosi join e query.
Tra gli esempi di sistemi di gestione di database relazionali vi sono:
Il linguaggio SQL (Structured Query Language) è un linguaggio di programmazione utilizzato per comunicare con i database relazionali. Viene utilizzato per creare, modificare e recuperare dati dai database.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


