
App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprender o que é uma base de dados relacional e como ela funciona. Descubra como ela pode ajudá-lo a organizar e gerir os seus dados de forma eficiente.

Uma base de dados relacional é um conceito fundamental no mundo da gestão de dados. É um tipo de base de dados que armazena e gere dados utilizando tabelas e relações entre eles. No mundo actual, as empresas e organizações de todas as dimensões dependem de bases de dados relacionais para armazenar, organizar e gerir eficazmente grandes volumes de dados.
O modelo de base de dados relacional foi proposto pela primeira vez nos anos 70 por Edgar F. Codd, um cientista informático britânico. Desde então, tornou-se o modelo de base de dados dominante e é utilizado em várias aplicações, desde sistemas de planeamento de recursos empresariais (ERP) a websites de comércio electrónico e aplicações móveis.
Neste artigo, vamos explorar uma base de dados relacional, como funciona, e os seus benefícios e limitações. Também discutiremos os diferentes componentes de uma base de dados relacional, tais como tabelas, chaves, e relações, e como funcionam em conjunto para gerir os dados. No final deste artigo, terá uma sólida compreensão das bases de dados relacionais e do seu papel na gestão moderna de dados.
Uma base de dados relacional é um tipo de base de dados que organiza os dados em uma ou mais tabelas ou relações, cada uma das quais tem um nome único e consiste num conjunto de linhas e colunas. Os dados de uma base de dados relacional são estruturados e organizados, o que facilita a pesquisa, a recuperação e a gestão.
Os dados são tipicamente armazenados de uma forma normalizada numa base de dados relacional. Os dados são divididos em tabelas menores e relacionadas, cada uma com a sua chave ou identificador único. As relações entre estas tabelas são definidas através da utilização de chaves estrangeiras, que ligam os dados de uma tabela aos dados de outra.
As bases de dados relacionais são amplamente utilizadas em várias aplicações, incluindo sistemas empresariais e financeiros, investigação científica, e comércio electrónico. Fornecem uma forma flexível e escalável de armazenar e gerir grandes quantidades de dados, assegurando simultaneamente a integridade e consistência dos dados através de restrições, tais como chaves primárias e chaves estrangeiras.
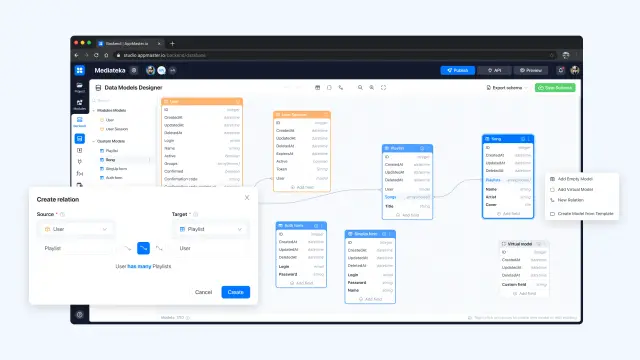
A AppMaster utiliza bases de dados relacionais. Utiliza SGBD Postgres. Os utilizadores AppMaster podem criar qualquer esquema de bases de dados relacionais, incluindo muitos tipos de campos e relações. Os utilizadores podem criar um número ilimitado de modelos, relações, e campos. Cada vez que alteram o esquema de dados e o guardam, o AppMaster escreve automaticamente uma migração para os esquemas existentes com a UPD. Ou seja, quando um utilizador empurra uma nova versão da sua aplicação com uma base de dados modificada, o binário da aplicação migra automaticamente o antigo formato do esquema da base de dados para o novo formato sem perder os seus dados.
As bases de dados relacionais são estruturadas utilizando tabelas, que também são conhecidas como relações. Cada tabela consiste em linhas e colunas, com cada linha representando um único registo ou instância de dados e cada coluna representando um atributo ou campo específico dos dados. Um conjunto de atributos ou tipos de dados, tais como texto, número, data, ou booleano, define as colunas de uma tabela. Cada coluna tem também um nome único, que ajuda a identificar o tipo de dados armazenados nessa coluna.
As linhas de uma tabela representam registos individuais ou instâncias de dados. Cada linha tem um identificador único, que é chamado de chave primária. A chave primária é utilizada para ligar registos através de diferentes tabelas na base de dados. As relações entre tabelas de uma base de dados relacional são definidas utilizando chaves estrangeiras. Uma chave estrangeira é uma coluna de uma tabela que se refere à chave primária de outra tabela. Isto permite que dados relacionados sejam ligados e acedidos a partir de diferentes tabelas da base de dados.
Para além das tabelas, as bases de dados relacionais também utilizam restrições para assegurar a integridade e consistência dos dados. Restrições são regras ou condições que devem ser cumpridas antes dos dados poderem ser inseridos, actualizados, ou apagados da base de dados. Exemplos de restrições incluem chaves primárias, chaves estrangeiras, restrições únicas, e restrições de verificação.
O modelo relacional é um modelo de dados que é utilizado para conceber e gerir dados numa base de dados relacional. O modelo relacional foi introduzido por Edgar F. Codd em 1970, e desde então tornou-se o modelo de dados mais amplamente utilizado para bases de dados modernas.
O modelo relacional baseia-se no conceito de tabelas, que também são conhecidas como relações. Cada tabela da base de dados representa uma colecção de dados relacionados, e cada linha da tabela representa um único registo ou instância desses dados. Cada coluna na tabela representa um atributo ou campo específico dos dados.
As relações entre tabelas na base de dados são definidas utilizando chaves. Uma chave primária é uma coluna ou conjunto de colunas de uma tabela que identifica de forma única cada linha dessa tabela. Uma chave estrangeira é uma coluna numa tabela que se refere à chave primária de outra tabela, permitindo que os dados relacionados sejam ligados entre diferentes tabelas da base de dados.
O modelo relacional também suporta operações de consulta e manipulação de dados na base de dados, tais como SELECT, INSERT, UPDATE, e DELETE. Estas operações são realizadas utilizando uma linguagem especial chamada Structured Query Language (SQL), que define consultas e declarações que interagem com a base de dados.
Um dos principais benefícios do modelo relacional é a sua flexibilidade e escalabilidade. As tabelas podem ser adicionadas, removidas ou modificadas para acomodar requisitos de dados em mudança, e as relações entre tabelas podem ser facilmente definidas ou actualizadas conforme necessário. Além disso, o modelo relacional fornece uma forma consistente e padronizada de organizar e gerir dados, facilitando a manutenção e actualização de bases de dados grandes e complexas ao longo do tempo.
Os Sistemas de Gestão de Bases de Dados Relacionais (RDBMS) oferecem inúmeros benefícios, alguns dos quais incluem o seguinte:
RDBMS fornece uma forma robusta e fiável de gerir dados e são amplamente utilizados numa variedade de aplicações, incluindo sistemas empresariais e financeiros, investigação científica, e comércio electrónico.
O modelo relacional é um modelo de dados que ajuda a reforçar a consistência dos dados num sistema de base de dados. O modelo baseia-se no conceito de tabelas ou relações, onde cada tabela representa uma colecção de dados relacionados, e cada linha da tabela representa um único registo ou instância desses dados. Cada coluna na tabela representa um atributo ou campo específico dos dados.
A coerência dos dados refere-se à exactidão e fiabilidade dos dados armazenados numa base de dados. No modelo relacional, a coerência dos dados é reforçada através da utilização de restrições. Restrições são regras ou condições que devem ser satisfeitas antes dos dados poderem ser inseridos, actualizados, ou apagados de uma tabela. Vários tipos de restrições podem ser utilizados no modelo relacional, tais como chaves primárias, chaves estrangeiras, e restrições de verificação.
Uma chave primária é um identificador único para cada linha de uma tabela. Ela assegura que cada registo na tabela pode ser identificado e acedido sem confusão ou erros. Uma chave estrangeira é uma coluna de uma tabela que se refere à chave primária de outra tabela. Assegura que os dados relacionados em diferentes tabelas são ligados correctamente. São utilizadas restrições de verificação para assegurar que os valores dos dados satisfazem critérios ou condições específicas.
Para além das restrições, o modelo relacional suporta transacções. Uma transacção é uma série de operações de base de dados realizadas em conjunto como uma única unidade de trabalho. Se qualquer parte da transacção falhar, a totalidade da transacção é retrocedida, assegurando que a base de dados permanece consistente.
A utilização de restrições e transacções no modelo relacional ajuda a assegurar a consistência dos dados numa base de dados. As restrições garantem que os dados são introduzidos e armazenados de forma consistente e fiável, enquanto as transacções garantem que as modificações de dados são feitas de uma forma atómica e consistente.
Além disso, o RDBMS implementa um mecanismo denominado "ACID", assegurando a fiabilidade das transacções. ACID significa Atomicidade, Consistência, Isolamento, e Durabilidade. Atomicidade assegura que uma transacção é tratada como uma única unidade de trabalho, o que significa que todas as alterações são cometidas, ou nenhuma o é. A coerência assegura que a base de dados se mantém num estado consistente após cada transacção. O isolamento assegura que múltiplas transacções podem ser executadas simultaneamente sem interferirem umas com as outras. A durabilidade assegura que as alterações feitas à base de dados persistem mesmo durante uma falha ou interrupção do sistema.
O modelo relacional proporciona uma forma robusta e fiável de gerir os dados, assegurando a consistência dos dados numa base de dados. Ao impor a consistência dos dados, o modelo relacional ajuda a manter a precisão e fiabilidade dos dados, o que é crítico para uma vasta gama de aplicações.
Compromisso e atomicidade são dois conceitos-chave nos sistemas de bases de dados, particularmente no contexto do processamento de transacções. Uma transacção é uma sequência de operações de base de dados que são tratadas como uma única unidade lógica de trabalho. As transacções podem envolver múltiplas operações, tais como leitura, escrita e actualização de dados, e são frequentemente utilizadas para assegurar que as alterações às bases de dados sejam feitas de forma consistente e fiável.
Atomicidade refere-se à propriedade de uma transacção que assegura que todas as suas operações são tratadas como uma unidade de trabalho única e indivisível. Isto significa que ou todas as operações da transacção são concluídas com sucesso ou nenhuma delas o é. Se qualquer parte de uma transacção falhar ou encontrar um erro, toda a transacção é retrocedida, e todas as alterações feitas à base de dados durante a transacção são desfeitas.
O compromisso refere-se à propriedade de uma transacção que assegura que, uma vez concluída com êxito, as suas alterações são permanentemente guardadas na base de dados. Após uma transacção ter sido comprometida, as suas alterações não podem ser desfeitas ou revertidas. O compromisso é tipicamente implementado utilizando uma declaração de compromisso ou mecanismo semelhante, que assinala o fim da transacção e faz com que as suas alterações sejam guardadas na base de dados.
A combinação de atomicidade e compromisso assegura que as transacções da base de dados são fiáveis e consistentes. A atomicidade assegura que as transacções são executadas de uma maneira tudo ou nada, o que ajuda a prevenir inconsistências ou corrupção de dados. O compromisso assegura que uma vez concluída com sucesso uma transacção, as suas alterações são permanentes e podem ser confiadas por outras transacções ou aplicações.
Nos sistemas de bases de dados, a implementação da atomicidade e do compromisso é frequentemente conseguida através de um gestor de transacções ou sistema de processamento de transacções, que é responsável pela coordenação e gestão das transacções. O gestor de transacções assegura que as transacções são executadas de forma atómica e consistente e que as suas alterações são comprometidas com a base de dados uma vez concluídas com sucesso.
As propriedades ACID (Atomicidade, Consistência, Isolamento e Durabilidade) são um conjunto de características que garantem fiabilidade e consistência nas transacções das bases de dados. Os Sistemas Relacionais de Gestão de Bases de Dados (RDBMS) são concebidos para apoiar as propriedades ACID, que são cruciais para o bom funcionamento de muitas aplicações e sistemas que dependem de dados.
A atomicidade refere-se à ideia de que uma transacção deve ser tratada como uma unidade de trabalho única e indivisível. Isto significa que se qualquer parte de uma transacção falhar, toda a transacção deve ser revertida, e todas as alterações feitas à base de dados durante a transacção devem ser desfeitas. A atomicidade assegura que as alterações à base de dados são feitas de forma consistente e fiável, sem quaisquer actualizações parciais ou incompletas.
A coerência refere-se à ideia de que uma transacção deve deixar a base de dados num estado consistente em que todos os dados satisfazem as regras e restrições definidas. Isto significa que uma transacção não deve violar nenhuma das restrições de integridade da base de dados, tais como chaves únicas ou chaves estrangeiras. A coerência assegura que a base de dados permanece fiável e exacta.
O isolamento refere-se à ideia de que múltiplas transacções devem ser capazes de executar simultaneamente sem interferir umas com as outras. O isolamento assegura que os efeitos de uma transacção não sejam visíveis para outras transacções até que a primeira transacção tenha sido concluída. Esta propriedade impede que surjam inconsistências e conflitos de dados quando múltiplas transacções tentam aceder ou modificar os mesmos dados simultaneamente.
A durabilidade refere-se à ideia de que, uma vez efectuada uma transacção, as suas alterações devem ser permanentes e persistentes, mesmo no caso de uma falha do sistema. A durabilidade é tipicamente implementada utilizando técnicas tais como o registo de dados de registo, em que todas as alterações feitas durante uma transacção são registadas num ficheiro de registo antes de serem aplicadas à base de dados. Isto assegura que mesmo que o sistema falhe ou sofra uma falha de energia, as alterações feitas durante a transacção podem ser recuperadas.
Sistemas RDBMS tais como MySQL, Oracle, e SQL Server fornecem suporte integrado para propriedades ACID, assegurando que as transacções da base de dados são executadas de forma fiável e consistente. Estas propriedades ajudam a assegurar a integridade e fiabilidade da base de dados, tornando-as adequadas para uma vasta gama de aplicações que dependem de dados precisos e consistentes.
Os procedimentos armazenados são programas armazenados num sistema de gestão de bases de dados relacional (RDBMS) e executados no lado do servidor. São utilizados para executar operações complexas sobre os dados armazenados na base de dados e podem ser chamados a partir de programas de aplicação ou directamente do sistema de gestão de bases de dados.
Os procedimentos armazenados são tipicamente escritos numa linguagem de programação que é suportada pelo sistema de gestão de bases de dados, tais como SQL ou PL/SQL. São compilados e armazenados na base de dados e podem ser executados chamando-os pelo nome.
Os procedimentos armazenados proporcionam vários benefícios num ambiente de base de dados relacional. Um benefício é que podem melhorar o desempenho reduzindo a quantidade de dados que precisam de ser transferidos entre a base de dados e a aplicação. Isto porque os procedimentos armazenados são executados no lado do servidor, reduzindo o tráfego e a latência da rede.
Os procedimentos armazenados também proporcionam um nível de segurança e controlo de acesso. Podem ser utilizados para aplicar regras comerciais e políticas de segurança e podem limitar o acesso a dados sensíveis, permitindo apenas a sua execução por utilizadores autorizados. Além disso, como os procedimentos armazenados são pré-compilados e armazenados na base de dados, são menos vulneráveis a ataques de injecção SQL do que instruções SQL ad-hoc.
Outro benefício dos procedimentos armazenados é que podem melhorar a consistência e a capacidade de manutenção da base de dados. Ao encapsular lógica empresarial complexa dentro de um procedimento armazenado, os criadores de aplicações podem assegurar que a lógica é aplicada de forma consistente em toda a base de dados. Além disso, os procedimentos armazenados podem ser actualizados independentemente do código da aplicação, facilitando a manutenção e actualização da lógica da base de dados.
Em resumo, os procedimentos armazenados proporcionam vários benefícios num ambiente de base de dados relacional, incluindo melhor desempenho, segurança, controlo de acesso, consistência, e capacidade de manutenção. São uma ferramenta poderosa para programadores e administradores de bases de dados e são amplamente utilizados em sistemas modernos de bases de dados.
O controlo da simultaneidade é um aspecto crítico dos sistemas de gestão de bases de dados relacionais (RDBMS) que assegura que múltiplas transacções com acesso aos mesmos dados possam ser executadas simultaneamente sem produzir resultados incorrectos. Uma das técnicas utilizadas para alcançar o controlo de simultaneidade é o bloqueio de bases de dados, que envolve a aquisição e libertação de bloqueios em objectos de bases de dados, tais como tabelas, linhas ou colunas.
O bloqueio é um mecanismo que impede o acesso simultâneo aos mesmos dados através de múltiplas transacções. Quando uma transacção solicita acesso a um determinado objecto de base de dados, tal como uma linha numa tabela, adquire um bloqueio sobre esse objecto. O bloqueio impede o acesso de outras transacções ao objecto até que a primeira transacção liberte o bloqueio. Uma vez concluída a transacção, o cadeado é libertado, permitindo que outras transacções acedam ao objecto.
No bloqueio de bases de dados, existem duas categorias de bloqueios partilhados e bloqueios exclusivos. Os bloqueios partilhados permitem que várias transacções leiam os mesmos dados ao mesmo tempo, enquanto os bloqueios exclusivos bloqueiam o acesso de outras transacções aos dados até que o bloqueio seja desbloqueado. Quando uma transacção adquire um bloqueio exclusivo sobre um objecto de base de dados, tem controlo total sobre o objecto e pode modificá-lo conforme necessário.
O bloqueio de bases de dados é essencial para manter a consistência dos dados em transacções simultâneas de bases de dados. No entanto, também pode levar a problemas de desempenho, especialmente em ambientes de alta moeda. Se demasiadas transacções estiverem à espera que os bloqueios sejam libertados, pode resultar em longos tempos de espera e diminuição do rendimento.
Para resolver este problema, muitos sistemas RDBMS utilizam várias técnicas de bloqueio, tais como o bloqueio optimista, que permite que múltiplas transacções acedam aos mesmos dados simultaneamente e resolve conflitos apenas quando estes ocorrem. Outra abordagem é a utilização do controlo concomitante multi-versões (MVCC), que cria múltiplas versões de dados na base de dados, permitindo que múltiplas transacções leiam e modifiquem os dados simultaneamente sem bloqueio.
O bloqueio de bases de dados é uma técnica crítica para manter a consistência nas transacções de bases de dados simultâneas. Embora possa levar a problemas de desempenho, os modernos sistemas RDBMS utilizam várias técnicas e algoritmos de bloqueio para minimizar os tempos de espera e melhorar a simultaneidade.
Ao seleccionar uma base de dados relacional, há vários factores a considerar, incluindo
A selecção de uma base de dados relacional requer a consideração de vários factores, incluindo escalabilidade, desempenho, disponibilidade, segurança, facilidade de utilização, compatibilidade, custo, comunidade, características e capacidades, e apoio a fornecedores. Uma avaliação cuidadosa destes factores pode ajudar a assegurar a selecção de uma base de dados que satisfaça os requisitos da aplicação e forneça um acesso fiável, eficiente e seguro aos dados.
A história das bases de dados relacionais começa no final dos anos 60, quando um informático chamado Edgar Codd propôs o conceito de um modelo relacional para bases de dados. A ideia do Codd era organizar os dados em tabelas ou relações, cada uma consistindo em linhas e colunas, com cada linha representando um registo único e cada coluna representando um atributo de dados. Propôs também um conjunto de princípios matemáticos, conhecidos como álgebra relacional, para manipular e consultar os dados.
No início dos anos 70, os investigadores da IBM Donald Chamberlin e Raymond Boyce desenvolveram uma linguagem para consulta de bases de dados relacionais chamada Structured English Query Language (SEQUEL), mais tarde rebaptizada SQL. SQL tornou-se a linguagem padrão para bases de dados relacionais e é ainda hoje amplamente utilizada.
Vários sistemas de bases de dados relacionais comerciais foram desenvolvidos no final dos anos 70 e início dos anos 80, incluindo o System R da IBM, Oracle, e Ingres. Estas bases de dados implementaram o modelo relacional e forneceram características tais como apoio a transacções, indexação, e optimização de consultas.
Nos anos 90, a popularidade das bases de dados relacionais continuou a crescer com o aparecimento da computação cliente-servidor e da Internet. As bases de dados relacionais fornecem uma plataforma robusta e escalável para armazenamento e recuperação de dados, apoiando aplicações que vão desde sistemas financeiros a sites de comércio electrónico.
No início dos anos 2000, o crescimento do software de código aberto levou ao desenvolvimento de várias bases de dados relacionais populares de código aberto, incluindo MySQL, PostgreSQL, e SQLite. Estas bases de dados constituíram uma alternativa rentável às bases de dados comerciais e foram amplamente adoptadas por programadores e organizações.
Actualmente, as bases de dados relacionais continuam a ser o tipo de base de dados mais amplamente utilizado, com novas características e capacidades, tais como computação distribuída, integração de nuvens, e apoio à aprendizagem de máquinas. Enquanto outros tipos de bases de dados, tais como NoSQL e bases de dados gráficos, surgiram, as bases de dados relacionais continuam a ser uma parte crítica da infra-estrutura de dados para muitas organizações.
Em conclusão, uma base de dados relacional é uma ferramenta poderosa para gerir grandes quantidades de dados de uma forma estruturada e organizada. Ao utilizar tabelas com linhas e colunas e estabelecer relações entre elas, uma base de dados relacional pode armazenar e recuperar eficazmente informações para uma variedade de aplicações. O uso de SQL como linguagem padrão para gerir bases de dados relacionais facilitou a interacção e manipulação de dados por parte de programadores e utilizadores. Com o crescimento contínuo das aplicações baseadas em dados, a importância de compreender e utilizar bases de dados relacionais só vai continuar a aumentar. Quer seja um programador, um analista de dados, ou simplesmente alguém que procura gerir a sua informação de forma mais eficaz, aprender sobre bases de dados relacionais pode ser um investimento valioso do seu tempo e esforço.
Uma base de dados relacional é um tipo de base de dados que organiza os dados em uma ou mais tabelas ou relações, com base num conjunto específico de regras. As tabelas são ligadas ou relacionadas por um campo ou chave comum, permitindo aos utilizadores acederem e manipularem os dados facilmente.
As vantagens da utilização de uma Base de Dados Relacionais incluem:
Os componentes de uma Base de Dados Relacionais incluem:
Os tipos de chaves utilizadas numa Base de Dados Relacionais incluem:
Uma Chave Primária é um identificador único para cada linha ou registo numa tabela. É utilizada para garantir a integridade dos dados e para ligar dados através de múltiplas tabelas.
Uma Chave Estrangeira é um campo numa tabela que se refere à Chave Primária noutra tabela. É utilizada para estabelecer relações entre tabelas.
Uma Chave de Candidato é um identificador único para cada linha ou registo de uma tabela. É utilizada para determinar a Chave Primária da tabela.
Uma Chave Composta é uma combinação de dois ou mais campos que juntos servem como identificador único para cada linha ou registo numa tabela.
Normalização é o processo de organização de dados numa base de dados para reduzir a redundância e melhorar a integridade dos dados. Envolve a decomposição de grandes tabelas em tabelas mais pequenas e especializadas e o estabelecimento de relações entre elas.
A desnormalização é acrescentar dados redundantes a uma base de dados para melhorar o desempenho. Envolve a duplicação de dados em múltiplas tabelas para evitar junções e consultas dispendiosas.
Exemplos de Sistemas de Gestão de Bases de Dados Relacionais incluem:
A Structured Query Language (SQL) é uma linguagem de programação utilizada para comunicar com Bases de Dados Relacionais. É utilizada para criar, modificar, e recuperar dados de bases de dados.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


