
उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
जानें कि रिलेशनल डेटाबेस क्या है और यह कैसे काम करता है। डिस्कवर करें कि यह आपके डेटा को कुशलतापूर्वक व्यवस्थित और प्रबंधित करने में आपकी सहायता कैसे कर सकता है।

डेटा प्रबंधन की दुनिया में एक रिलेशनल डेटाबेस एक मौलिक अवधारणा है। यह एक प्रकार का डेटाबेस है जो तालिकाओं और उनके बीच संबंधों का उपयोग करके डेटा को संग्रहीत और प्रबंधित करता है। आज की डेटा-संचालित दुनिया में, सभी आकार के व्यवसाय और संगठन बड़ी मात्रा में डेटा को कुशलतापूर्वक संग्रहीत, व्यवस्थित और प्रबंधित करने के लिए रिलेशनल डेटाबेस पर भरोसा करते हैं।
रिलेशनल डेटाबेस मॉडल पहली बार 1970 के दशक में ब्रिटिश कंप्यूटर वैज्ञानिक एडगर एफ. कॉड द्वारा प्रस्तावित किया गया था। तब से, यह प्रमुख डेटाबेस मॉडल बन गया है और इसका उपयोग एंटरप्राइज रिसोर्स प्लानिंग (ईआरपी) सिस्टम से लेकर ई-कॉमर्स वेबसाइटों और मोबाइल एप्लिकेशन तक विभिन्न अनुप्रयोगों में किया जाता है।
इस लेख में, हम एक संबंधपरक डेटाबेस, यह कैसे काम करता है, और इसके लाभों और सीमाओं का पता लगाएगा। हम रिलेशनल डेटाबेस के विभिन्न घटकों, जैसे टेबल, कुंजियाँ और संबंध, और डेटा को प्रबंधित करने के लिए एक साथ कैसे काम करते हैं, पर भी चर्चा करेंगे। इस लेख के अंत तक, आपको संबंधपरक डेटाबेस और आधुनिक डेटा प्रबंधन में उनकी भूमिका की ठोस समझ होगी।
एक संबंधपरक डेटाबेस एक प्रकार का डेटाबेस है जो डेटा को एक या अधिक तालिकाओं या संबंधों में व्यवस्थित करता है, जिनमें से प्रत्येक का एक अद्वितीय नाम होता है और इसमें पंक्तियों और स्तंभों का एक समूह होता है। रिलेशनल डेटाबेस में डेटा संरचित और व्यवस्थित होता है, जिससे इसे खोजना, पुनर्प्राप्त करना और प्रबंधित करना आसान हो जाता है।
डेटा आमतौर पर रिलेशनल डेटाबेस में सामान्यीकृत रूप में संग्रहीत होता है। डेटा को छोटी, संबंधित तालिकाओं में विभाजित किया गया है, प्रत्येक अपनी अनूठी कुंजी या पहचानकर्ता के साथ। इन तालिकाओं के बीच संबंधों को विदेशी कुंजियों के उपयोग के माध्यम से परिभाषित किया जाता है, जो एक तालिका में डेटा को दूसरे में डेटा से लिंक करते हैं।
व्यापार और वित्तीय प्रणाली, वैज्ञानिक अनुसंधान और ई-कॉमर्स सहित विभिन्न अनुप्रयोगों में संबंधपरक डेटाबेस का व्यापक रूप से उपयोग किया जाता है। वे प्राथमिक कुंजी और विदेशी कुंजी जैसे बाधाओं के माध्यम से डेटा अखंडता और स्थिरता सुनिश्चित करते हुए बड़ी मात्रा में डेटा को स्टोर और प्रबंधित करने के लिए एक लचीला और स्केलेबल तरीका प्रदान करते हैं।
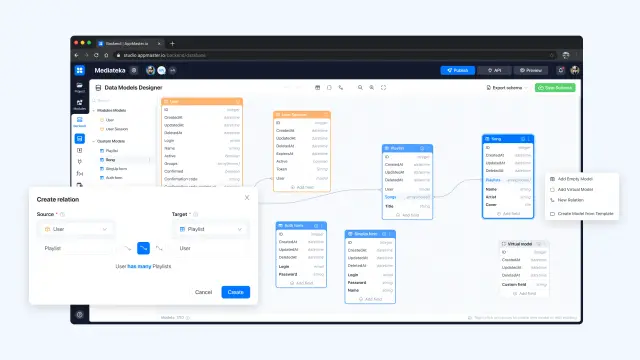
AppMaster रिलेशनल डेटाबेस का उपयोग करता है। यह DBMS पोस्टग्रेज का उपयोग करता है। AppMaster उपयोगकर्ता कई प्रकार के फ़ील्ड और संबंधों सहित संबंधपरक डेटाबेस का कोई भी स्कीमा बना सकते हैं। उपयोगकर्ता असीमित संख्या में मॉडल, संबंध और फ़ील्ड बना सकते हैं। हर बार जब वे डेटा स्कीमा बदलते हैं और इसे सहेजते हैं, तो AppMaster UPD के साथ मौजूदा स्कीमा के लिए स्वचालित रूप से माइग्रेशन लिख देगा। यही है, जब कोई उपयोगकर्ता संशोधित डेटाबेस के साथ अपने एप्लिकेशन के नए संस्करण को आगे बढ़ाता है, तो एप्लिकेशन बाइनरी अपने डेटा को खोए बिना पुराने डेटाबेस स्कीमा प्रारूप को नए प्रारूप में स्वचालित रूप से माइग्रेट कर देती है।
संबंधपरक डेटाबेस को तालिकाओं का उपयोग करके संरचित किया जाता है, जिसे संबंध के रूप में भी जाना जाता है। प्रत्येक तालिका में पंक्तियाँ और स्तंभ होते हैं, प्रत्येक पंक्ति एक एकल रिकॉर्ड या डेटा के उदाहरण का प्रतिनिधित्व करती है और प्रत्येक स्तंभ डेटा की एक विशिष्ट विशेषता या क्षेत्र का प्रतिनिधित्व करता है। विशेषताओं या डेटा प्रकारों का एक सेट, जैसे पाठ, संख्या, दिनांक या बूलियन, तालिका में स्तंभों को परिभाषित करता है। प्रत्येक कॉलम का एक विशिष्ट नाम भी होता है, जो उस कॉलम में संग्रहीत डेटा प्रकार की पहचान करने में मदद करता है।
तालिका में पंक्तियाँ व्यक्तिगत रिकॉर्ड या डेटा के उदाहरणों का प्रतिनिधित्व करती हैं। प्रत्येक पंक्ति में एक विशिष्ट पहचानकर्ता होता है, जिसे प्राथमिक कुंजी कहा जाता है। प्राथमिक कुंजी का उपयोग डेटाबेस में विभिन्न तालिकाओं में रिकॉर्ड को लिंक करने के लिए किया जाता है। संबंधपरक डेटाबेस में तालिकाओं के बीच संबंधों को विदेशी कुंजियों का उपयोग करके परिभाषित किया जाता है। एक विदेशी कुंजी एक तालिका में एक स्तंभ है जो किसी अन्य तालिका की प्राथमिक कुंजी को संदर्भित करती है। यह संबंधित डेटा को डेटाबेस में विभिन्न तालिकाओं से लिंक और एक्सेस करने की अनुमति देता है।
तालिकाओं के अलावा, संबंधपरक डेटाबेस भी डेटा अखंडता और स्थिरता सुनिश्चित करने के लिए बाधाओं का उपयोग करते हैं। प्रतिबंध ऐसे नियम या शर्तें हैं जिन्हें डेटाबेस से डेटा डालने, अपडेट करने या हटाने से पहले पूरा किया जाना चाहिए। बाधाओं के उदाहरणों में प्राथमिक कुंजियाँ, विदेशी कुंजियाँ, अद्वितीय बाधाएँ और जाँच बाधाएँ शामिल हैं।
रिलेशनल मॉडल एक डेटा मॉडल है जिसका उपयोग रिलेशनल डेटाबेस में डेटा को डिज़ाइन और प्रबंधित करने के लिए किया जाता है। रिलेशनल मॉडल को 1970 में एडगर एफ. कॉड द्वारा पेश किया गया था, और तब से यह आधुनिक डेटाबेस के लिए सबसे व्यापक रूप से उपयोग किया जाने वाला डेटा मॉडल बन गया है।
रिलेशनल मॉडल टेबल की अवधारणा पर आधारित है, जिसे रिलेशन के रूप में भी जाना जाता है। डेटाबेस में प्रत्येक तालिका संबंधित डेटा के संग्रह का प्रतिनिधित्व करती है, और तालिका में प्रत्येक पंक्ति उस डेटा के एकल रिकॉर्ड या उदाहरण का प्रतिनिधित्व करती है। तालिका में प्रत्येक स्तंभ डेटा की एक विशिष्ट विशेषता या क्षेत्र का प्रतिनिधित्व करता है।
डेटाबेस में तालिकाओं के बीच संबंधों को कुंजियों का उपयोग करके परिभाषित किया जाता है। एक प्राथमिक कुंजी एक तालिका में एक स्तंभ या स्तंभों का समूह है जो उस तालिका में प्रत्येक पंक्ति को विशिष्ट रूप से पहचानती है। एक विदेशी कुंजी एक तालिका में एक स्तंभ है जो किसी अन्य तालिका की प्राथमिक कुंजी को संदर्भित करती है, जिससे संबंधित डेटा को डेटाबेस में विभिन्न तालिकाओं से जोड़ा जा सकता है।
रिलेशनल मॉडल डेटाबेस में डेटा को क्वेरी और हेरफेर करने के लिए ऑपरेशन का भी समर्थन करता है, जैसे कि SELECT, INSERT, UPDATE, और DELETE। ये ऑपरेशन स्ट्रक्चर्ड क्वेरी लैंग्वेज ( एसक्यूएल ) नामक एक विशेष भाषा का उपयोग करके किए जाते हैं, जो डेटाबेस के साथ इंटरैक्ट करने वाले प्रश्नों और बयानों को परिभाषित करता है।
संबंधपरक मॉडल के प्रमुख लाभों में से एक इसका लचीलापन और मापनीयता है। बदलती डेटा आवश्यकताओं को समायोजित करने के लिए तालिकाओं को जोड़ा, हटाया या संशोधित किया जा सकता है, और तालिकाओं के बीच संबंधों को आसानी से परिभाषित या आवश्यकतानुसार अद्यतन किया जा सकता है। इसके अतिरिक्त, रिलेशनल मॉडल डेटा को व्यवस्थित और प्रबंधित करने का एक सुसंगत और मानकीकृत तरीका प्रदान करता है, जिससे समय के साथ बड़े और जटिल डेटाबेस को बनाए रखना और अपडेट करना आसान हो जाता है।
रिलेशनल डाटाबेस मैनेजमेंट सिस्टम्स (आरडीबीएमएस) कई लाभ प्रदान करते हैं, जिनमें से कुछ में निम्नलिखित शामिल हैं:
RDBMS डेटा को प्रबंधित करने के लिए एक मजबूत और विश्वसनीय तरीका प्रदान करता है और व्यापार और वित्तीय प्रणालियों, वैज्ञानिक अनुसंधान और ई-कॉमर्स सहित विभिन्न प्रकार के अनुप्रयोगों में व्यापक रूप से उपयोग किया जाता है।
रिलेशनल मॉडल एक डेटा मॉडल है जो डेटाबेस सिस्टम में डेटा स्थिरता को लागू करने में मदद करता है। मॉडल तालिकाओं या संबंधों की अवधारणा पर आधारित है, जहां प्रत्येक तालिका संबंधित डेटा के संग्रह का प्रतिनिधित्व करती है, और तालिका में प्रत्येक पंक्ति उस डेटा के एकल रिकॉर्ड या उदाहरण का प्रतिनिधित्व करती है। तालिका में प्रत्येक स्तंभ डेटा की एक विशिष्ट विशेषता या क्षेत्र का प्रतिनिधित्व करता है।
डेटा संगति डेटाबेस में संग्रहीत डेटा की सटीकता और विश्वसनीयता को संदर्भित करती है। संबंधपरक मॉडल में, डेटा संगति को बाधाओं के उपयोग के माध्यम से लागू किया जाता है। प्रतिबन्ध वे नियम या शर्तें हैं जिन्हें किसी तालिका में डेटा डालने, अद्यतन करने या हटाने से पहले पूरा किया जाना चाहिए। रिलेशनल मॉडल में कई प्रकार की बाधाओं का उपयोग किया जा सकता है, जैसे प्राथमिक कुंजी, विदेशी कुंजी और चेक बाधा।
तालिका में प्रत्येक पंक्ति के लिए एक प्राथमिक कुंजी एक अद्वितीय पहचानकर्ता है। यह सुनिश्चित करता है कि तालिका में प्रत्येक रिकॉर्ड को बिना भ्रम या त्रुटियों के पहचाना और एक्सेस किया जा सकता है। एक विदेशी कुंजी एक तालिका में एक स्तंभ है जो किसी अन्य तालिका की प्राथमिक कुंजी को संदर्भित करती है। यह सुनिश्चित करता है कि विभिन्न तालिकाओं में संबंधित डेटा सही ढंग से जुड़ा हुआ है। चेक बाधाओं का उपयोग यह सुनिश्चित करने के लिए किया जाता है कि डेटा मान विशिष्ट मानदंडों या शर्तों को पूरा करते हैं।
बाधाओं के अतिरिक्त, रिलेशनल मॉडल लेनदेन का समर्थन करता है। एक लेन-देन डेटाबेस संचालन की एक श्रृंखला है जो कार्य की एक इकाई के रूप में एक साथ किया जाता है। यदि लेन-देन का कोई भी भाग विफल हो जाता है, तो यह सुनिश्चित करते हुए कि डेटाबेस सुसंगत रहता है, संपूर्ण लेन-देन वापस ले लिया जाता है।
संबंधपरक मॉडल की बाधाओं और लेनदेन का उपयोग डेटाबेस में डेटा स्थिरता सुनिश्चित करने में मदद करता है। बाधाएं सुनिश्चित करती हैं कि डेटा दर्ज किया गया है और लगातार और भरोसेमंद रूप से संग्रहीत किया गया है, जबकि लेनदेन सुनिश्चित करता है कि डेटा संशोधन एक परमाणु और सुसंगत तरीके से किए जाते हैं।
इसके अलावा, RDBMS लेन-देन की विश्वसनीयता सुनिश्चित करने के लिए "ACID" गुण नामक एक तंत्र को लागू करता है। एसीआईडी परमाणुता, संगति, अलगाव और स्थायित्व के लिए खड़ा है। परमाणु सुनिश्चित करता है कि लेनदेन को कार्य की एक इकाई के रूप में माना जाता है, जिसका अर्थ है कि सभी परिवर्तन प्रतिबद्ध हैं या कोई भी नहीं है। संगति यह सुनिश्चित करती है कि डेटाबेस प्रत्येक लेनदेन के बाद एक सुसंगत स्थिति में रहे। अलगाव यह सुनिश्चित करता है कि एक दूसरे के साथ हस्तक्षेप किए बिना कई लेनदेन समवर्ती रूप से निष्पादित किए जा सकते हैं। स्थायित्व यह सुनिश्चित करता है कि सिस्टम विफलता या रुकावट के दौरान भी डेटाबेस में किए गए परिवर्तन बने रहें।
रिलेशनल मॉडल डेटा को प्रबंधित करने के लिए एक मजबूत और विश्वसनीय तरीका प्रदान करता है, डेटाबेस में डेटा स्थिरता सुनिश्चित करता है। डेटा संगति को लागू करके, संबंधपरक मॉडल डेटा की सटीकता और विश्वसनीयता बनाए रखने में मदद करता है, जो अनुप्रयोगों की एक विस्तृत श्रृंखला के लिए महत्वपूर्ण है।
विशेष रूप से लेन-देन प्रसंस्करण के संदर्भ में डेटाबेस सिस्टम में प्रतिबद्धता और परमाणुता दो प्रमुख अवधारणाएं हैं। लेन-देन डेटाबेस संचालन का एक क्रम है जिसे कार्य की एकल तार्किक इकाई के रूप में माना जाता है। लेन-देन में कई ऑपरेशन शामिल हो सकते हैं, जैसे डेटा पढ़ना, लिखना और अपडेट करना, और उनका उपयोग अक्सर यह सुनिश्चित करने के लिए किया जाता है कि डेटाबेस परिवर्तन लगातार और मज़बूती से किए जाते हैं।
परमाणुता एक लेन-देन की संपत्ति को संदर्भित करती है जो यह सुनिश्चित करती है कि इसके सभी कार्यों को कार्य की एकल, अविभाज्य इकाई के रूप में माना जाता है। इसका मतलब है कि या तो लेन-देन में सभी ऑपरेशन सफलतापूर्वक पूरे हो गए हैं या उनमें से कोई भी नहीं है। यदि लेन-देन का कोई भाग विफल हो जाता है या कोई त्रुटि सामने आती है, तो संपूर्ण लेन-देन वापस ले लिया जाता है, और लेन-देन के दौरान डेटाबेस में किए गए सभी परिवर्तन पूर्ववत कर दिए जाते हैं।
प्रतिबद्धता एक लेन-देन की संपत्ति को संदर्भित करती है जो यह सुनिश्चित करती है कि एक बार सफलतापूर्वक पूरा हो जाने के बाद, इसके परिवर्तन डेटाबेस में स्थायी रूप से सहेजे जाते हैं। लेन-देन प्रतिबद्ध होने के बाद, इसके परिवर्तन पूर्ववत या वापस नहीं किए जा सकते। प्रतिबद्धता आमतौर पर एक कमिट स्टेटमेंट या समान तंत्र का उपयोग करके कार्यान्वित की जाती है, जो लेनदेन के अंत का संकेत देती है और इसके परिवर्तनों को डेटाबेस में सहेजे जाने का कारण बनती है।
परमाणुता और प्रतिबद्धता का संयोजन सुनिश्चित करता है कि डेटाबेस लेनदेन विश्वसनीय और सुसंगत हैं। परमाणुता यह सुनिश्चित करती है कि लेन-देन सभी या कुछ भी नहीं तरीके से निष्पादित किया जाता है, जो डेटा विसंगतियों या भ्रष्टाचार को रोकने में मदद करता है। प्रतिबद्धता सुनिश्चित करती है कि एक बार लेन-देन सफलतापूर्वक पूरा हो जाने के बाद, इसके परिवर्तन स्थायी होते हैं और अन्य लेनदेन या अनुप्रयोगों पर भरोसा किया जा सकता है।
डेटाबेस सिस्टम में, परमाणुता और प्रतिबद्धता का कार्यान्वयन अक्सर लेन-देन प्रबंधक या लेनदेन प्रसंस्करण प्रणाली के माध्यम से प्राप्त किया जाता है, जो लेनदेन के समन्वय और प्रबंधन के लिए जिम्मेदार होता है। लेन-देन प्रबंधक यह सुनिश्चित करता है कि लेन-देन एक परमाणु और सुसंगत तरीके से निष्पादित किए जाते हैं और उनके परिवर्तन सफलतापूर्वक पूरा होने के बाद डेटाबेस के लिए प्रतिबद्ध होते हैं।
ACID (परमाणुता, संगति, अलगाव और स्थायित्व) गुण विशेषताओं का एक समूह है जो डेटाबेस लेनदेन में विश्वसनीयता और स्थिरता सुनिश्चित करता है। रिलेशनल डाटाबेस मैनेजमेंट सिस्टम्स (आरडीबीएमएस) को एसीआईडी गुणों का समर्थन करने के लिए डिज़ाइन किया गया है, जो डेटा पर भरोसा करने वाले कई अनुप्रयोगों और प्रणालियों के उचित कामकाज के लिए महत्वपूर्ण हैं।
एटमॉसिटी इस विचार को संदर्भित करता है कि एक लेनदेन को कार्य की एकल, अविभाज्य इकाई के रूप में माना जाना चाहिए। इसका अर्थ यह है कि यदि लेन-देन का कोई भाग विफल हो जाता है, तो पूरे लेन-देन को वापस ले लिया जाना चाहिए, और लेन-देन के दौरान डेटाबेस में किए गए सभी परिवर्तन पूर्ववत किए जाने चाहिए। परमाणुता यह सुनिश्चित करती है कि डेटाबेस परिवर्तन बिना किसी आंशिक या अधूरे अपडेट के लगातार और मज़बूती से किए जाते हैं।
संगति इस विचार को संदर्भित करती है कि एक लेन-देन डेटाबेस को एक सुसंगत स्थिति में छोड़ देना चाहिए जहां सभी डेटा परिभाषित नियमों और बाधाओं को पूरा करते हैं। इसका मतलब यह है कि लेनदेन को किसी भी डेटाबेस की अखंडता बाधाओं का उल्लंघन नहीं करना चाहिए, जैसे अद्वितीय कुंजी या विदेशी कुंजी। संगति यह सुनिश्चित करती है कि डेटाबेस विश्वसनीय और सटीक बना रहे।
अलगाव इस विचार को संदर्भित करता है कि कई लेनदेन एक दूसरे के साथ हस्तक्षेप किए बिना समवर्ती रूप से निष्पादित करने में सक्षम होने चाहिए। आइसोलेशन यह सुनिश्चित करता है कि पहला लेन-देन पूरा होने तक एक लेन-देन का प्रभाव दूसरे लेन-देन को दिखाई न दे। यह संपत्ति डेटा विसंगतियों और संघर्षों को उत्पन्न होने से रोकती है जब कई लेन-देन एक ही डेटा को एक साथ एक्सेस या संशोधित करने का प्रयास करते हैं।
टिकाउपन इस विचार को संदर्भित करता है कि एक बार लेन-देन किए जाने के बाद, इसके परिवर्तन स्थायी और लगातार होने चाहिए, यहां तक कि सिस्टम विफलता की स्थिति में भी। टिकाउपन आमतौर पर राइट-फॉरवर्ड लॉगिंग जैसी तकनीकों का उपयोग करके कार्यान्वित किया जाता है, जहां लेन-देन के दौरान किए गए सभी परिवर्तन डेटाबेस पर लागू होने से पहले एक लॉग फ़ाइल में रिकॉर्ड किए जाते हैं। यह सुनिश्चित करता है कि भले ही सिस्टम क्रैश हो जाए या बिजली की विफलता का अनुभव हो, लेनदेन के दौरान किए गए परिवर्तनों को पुनर्प्राप्त किया जा सकता है।
RDBMS सिस्टम जैसे कि MySQL , Oracle, और SQL सर्वर ACID गुणों के लिए अंतर्निहित समर्थन प्रदान करते हैं, यह सुनिश्चित करते हुए कि डेटाबेस लेनदेन मज़बूती से और लगातार निष्पादित किए जाते हैं। ये गुण डेटाबेस की अखंडता और विश्वसनीयता सुनिश्चित करने में मदद करते हैं, जिससे उन्हें सटीक और सुसंगत डेटा पर भरोसा करने वाले अनुप्रयोगों की एक विस्तृत श्रृंखला के लिए उपयुक्त बनाया जा सकता है।
संग्रहीत कार्यविधियाँ एक संबंधपरक डेटाबेस प्रबंधन प्रणाली (RDBMS) के भीतर संग्रहीत प्रोग्राम हैं और सर्वर साइड पर निष्पादित होती हैं। उनका उपयोग डेटाबेस में संग्रहीत डेटा पर जटिल संचालन करने के लिए किया जाता है और उन्हें एप्लिकेशन प्रोग्राम या सीधे डेटाबेस प्रबंधन प्रणाली से बुलाया जा सकता है।
संग्रहीत कार्यविधियाँ आमतौर पर एक प्रोग्रामिंग भाषा में लिखी जाती हैं जो डेटाबेस प्रबंधन प्रणाली, जैसे SQL या PL/SQL द्वारा समर्थित होती हैं। उन्हें डेटाबेस में संकलित और संग्रहीत किया जाता है और उन्हें नाम से बुलाकर निष्पादित किया जा सकता है।
संगृहीत कार्यविधियाँ संबंधपरक डेटाबेस वातावरण में कई लाभ प्रदान करती हैं। एक लाभ यह है कि वे डेटाबेस और एप्लिकेशन के बीच स्थानांतरित किए जाने वाले डेटा की मात्रा को कम करके प्रदर्शन में सुधार कर सकते हैं। ऐसा इसलिए है क्योंकि संग्रहीत कार्यविधियाँ सर्वर साइड पर निष्पादित की जाती हैं, जिससे नेटवर्क ट्रैफ़िक और विलंबता कम हो जाती है।
संग्रहीत कार्यविधियाँ सुरक्षा और अभिगम नियंत्रण का एक स्तर भी प्रदान करती हैं। उनका उपयोग व्यावसायिक नियमों और सुरक्षा नीतियों को लागू करने के लिए किया जा सकता है और केवल अधिकृत उपयोगकर्ताओं को उन्हें निष्पादित करने की अनुमति देकर संवेदनशील डेटा तक पहुंच को सीमित कर सकते हैं। इसके अतिरिक्त, क्योंकि संग्रहीत कार्यविधियाँ पूर्व-संकलित और डेटाबेस में संग्रहीत हैं, वे एड-हॉक SQL कथनों की तुलना में SQL इंजेक्शन हमलों के लिए कम असुरक्षित हैं।
संग्रहीत प्रक्रियाओं का एक अन्य लाभ यह है कि वे डेटाबेस स्थिरता और रखरखाव में सुधार कर सकते हैं। एक संग्रहीत कार्यविधि के भीतर जटिल व्यावसायिक तर्क को समाहित करके, एप्लिकेशन डेवलपर यह सुनिश्चित कर सकते हैं कि तर्क डेटाबेस में लगातार लागू होता है। इसके अतिरिक्त, संग्रहीत प्रक्रियाओं को एप्लिकेशन कोड से स्वतंत्र रूप से अपडेट किया जा सकता है, जिससे डेटाबेस लॉजिक को बनाए रखना और अपडेट करना आसान हो जाता है।
सारांश में, संग्रहीत कार्यविधियाँ संबंधपरक डेटाबेस वातावरण में कई लाभ प्रदान करती हैं, जिसमें बेहतर प्रदर्शन, सुरक्षा, अभिगम नियंत्रण, निरंतरता और रखरखाव शामिल हैं। वे डेवलपर्स और डेटाबेस प्रशासकों के लिए एक शक्तिशाली उपकरण हैं और आधुनिक डेटाबेस सिस्टम में व्यापक रूप से उपयोग किए जाते हैं।
संगामिति नियंत्रण रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS) का एक महत्वपूर्ण पहलू है जो यह सुनिश्चित करता है कि एक ही डेटा तक पहुँचने वाले कई लेन-देन गलत परिणाम उत्पन्न किए बिना समवर्ती रूप से निष्पादित हो सकते हैं। समवर्ती नियंत्रण प्राप्त करने के लिए उपयोग की जाने वाली तकनीकों में से एक डेटाबेस लॉकिंग है, जिसमें डेटाबेस ऑब्जेक्ट्स जैसे टेबल, रो या कॉलम पर लॉक प्राप्त करना और जारी करना शामिल है।
लॉकिंग एक तंत्र है जो एक ही डेटा को कई लेनदेन द्वारा समवर्ती पहुंच से रोकता है। जब कोई लेन-देन किसी विशेष डेटाबेस ऑब्जेक्ट तक पहुँच का अनुरोध करता है, जैसे कि तालिका में एक पंक्ति, तो यह उस ऑब्जेक्ट पर लॉक प्राप्त कर लेता है। लॉक अन्य लेन-देन को ऑब्जेक्ट तक पहुंचने से रोकता है जब तक कि पहला लेनदेन लॉक जारी नहीं करता। एक बार लेन-देन पूरा हो जाने के बाद, लॉक जारी हो जाता है, जिससे अन्य लेन-देन ऑब्जेक्ट तक पहुंच सकते हैं।
डेटाबेस लॉकिंग में, दो श्रेणियां साझा ताले और अनन्य ताले मौजूद हैं। साझा ताले एक ही समय में एक ही डेटा को पढ़ने के लिए कई लेन-देन को सक्षम करते हैं, जबकि अनन्य ताले अन्य लेनदेन को डेटा तक पहुंचने से रोकते हैं जब तक कि लॉक जारी नहीं हो जाता। जब कोई लेन-देन डेटाबेस ऑब्जेक्ट पर एक विशेष लॉक प्राप्त करता है, तो उसका ऑब्जेक्ट पर पूर्ण नियंत्रण होता है और इसे आवश्यकतानुसार संशोधित कर सकता है।
डेटाबेस लॉकिंग समवर्ती डेटाबेस लेनदेन में डेटा स्थिरता बनाए रखने के लिए आवश्यक है। हालाँकि, यह प्रदर्शन समस्याओं को भी जन्म दे सकता है, विशेष रूप से उच्च-संगामिति वातावरण में। यदि बहुत अधिक लेन-देन लॉक के रिलीज़ होने की प्रतीक्षा कर रहे हैं, तो इसका परिणाम लंबे समय तक प्रतीक्षा समय और थ्रूपुट में कमी हो सकता है।
इस समस्या को हल करने के लिए, कई आरडीबीएमएस सिस्टम विभिन्न लॉकिंग तकनीकों का उपयोग करते हैं, जैसे आशावादी लॉकिंग, जो एक ही डेटा को समवर्ती रूप से एक्सेस करने के लिए कई लेन-देन की अनुमति देता है और विरोध होने पर ही हल करता है। एक अन्य दृष्टिकोण बहु-संस्करण संगामिति नियंत्रण (एमवीसीसी) का उपयोग करना है, जो डेटाबेस में डेटा के कई संस्करण बनाता है, जिससे कई लेन-देन बिना लॉक किए समवर्ती रूप से डेटा को पढ़ने और संशोधित करने की अनुमति देता है।
समवर्ती डेटाबेस लेनदेन में निरंतरता बनाए रखने के लिए डेटाबेस लॉकिंग एक महत्वपूर्ण तकनीक है। जबकि यह प्रदर्शन की समस्याओं को जन्म दे सकता है, आधुनिक RDBMS सिस्टम प्रतीक्षा समय को कम करने और संगामिति में सुधार करने के लिए विभिन्न लॉकिंग तकनीकों और एल्गोरिदम का उपयोग करते हैं।
संबंधपरक डेटाबेस का चयन करते समय, विचार करने के लिए कई कारक हैं, जिनमें निम्न शामिल हैं:
एक रिलेशनल डेटाबेस का चयन करने के लिए मापनीयता, प्रदर्शन, उपलब्धता, सुरक्षा, उपयोग में आसानी, अनुकूलता, लागत, समुदाय, सुविधाओं और क्षमताओं और विक्रेता समर्थन सहित कई कारकों पर विचार करने की आवश्यकता होती है। इन कारकों का सावधानीपूर्वक मूल्यांकन एक डेटाबेस के चयन को सुनिश्चित करने में मदद कर सकता है जो एप्लिकेशन की आवश्यकताओं को पूरा करता है और डेटा तक विश्वसनीय, कुशल और सुरक्षित पहुंच प्रदान करता है।
रिलेशनल डेटाबेस का इतिहास 1960 के दशक के अंत में शुरू होता है जब एडगर कॉड नाम के एक कंप्यूटर वैज्ञानिक ने डेटाबेस के लिए एक रिलेशनल मॉडल की अवधारणा का प्रस्ताव रखा था। Codd का विचार डेटा को तालिकाओं या संबंधों में व्यवस्थित करना था, प्रत्येक में पंक्तियों और स्तंभों का समावेश होता है, जिसमें प्रत्येक पंक्ति एक अद्वितीय रिकॉर्ड का प्रतिनिधित्व करती है और प्रत्येक स्तंभ एक डेटा विशेषता का प्रतिनिधित्व करता है। उन्होंने गणितीय सिद्धांतों का एक सेट भी प्रस्तावित किया, जिसे संबंधपरक बीजगणित के रूप में जाना जाता है, डेटा में हेरफेर और क्वेरी करने के लिए।
1970 के दशक की शुरुआत में, IBM के शोधकर्ता डोनाल्ड चेम्बरलिन और रेमंड बॉयस ने स्ट्रक्चर्ड इंग्लिश क्वेरी लैंग्वेज (SEQUEL) नामक रिलेशनल डेटाबेस को क्वेरी करने के लिए एक भाषा विकसित की, जिसे बाद में SQL नाम दिया गया। SQL रिलेशनल डेटाबेस के लिए मानक भाषा बन गई और आज भी व्यापक रूप से उपयोग की जाती है।
1970 के दशक के अंत और 1980 के दशक की शुरुआत में आईबीएम के सिस्टम आर, ओरेकल और इंग्रेस सहित कई व्यावसायिक संबंधपरक डेटाबेस सिस्टम विकसित किए गए थे। इन डेटाबेस ने रिलेशनल मॉडल को लागू किया और लेनदेन, इंडेक्सिंग और क्वेरी ऑप्टिमाइज़ेशन के लिए समर्थन जैसी सुविधाएँ प्रदान कीं।
1990 के दशक में, क्लाइंट-सर्वर कंप्यूटिंग और इंटरनेट के उद्भव के साथ रिलेशनल डेटाबेस की लोकप्रियता बढ़ती रही। संबंधपरक डेटाबेस डेटा भंडारण और पुनर्प्राप्ति के लिए एक मजबूत और स्केलेबल प्लेटफॉर्म प्रदान करते हैं, जो वित्तीय प्रणालियों से लेकर ई-कॉमर्स साइटों तक के अनुप्रयोगों का समर्थन करते हैं।
2000 के दशक की शुरुआत में, ओपन-सोर्स सॉफ़्टवेयर के उदय ने MySQL, PostgreSQL और SQLite सहित कई लोकप्रिय ओपन-सोर्स रिलेशनल डेटाबेस का विकास किया। ये डेटाबेस व्यावसायिक डेटाबेस के लिए एक लागत प्रभावी विकल्प प्रदान करते हैं और डेवलपर्स और संगठनों द्वारा व्यापक रूप से अपनाए जाते हैं।
आज, वितरित कंप्यूटिंग, क्लाउड इंटीग्रेशन और मशीन लर्निंग सपोर्ट जैसी नई सुविधाओं और क्षमताओं के साथ रिलेशनल डेटाबेस सबसे व्यापक रूप से इस्तेमाल किया जाने वाला डेटाबेस है। जबकि अन्य प्रकार के डेटाबेस, जैसे कि NoSQL और ग्राफ़ डेटाबेस, उभरे हैं, रिलेशनल डेटाबेस कई संगठनों के लिए डेटा इन्फ्रास्ट्रक्चर का एक महत्वपूर्ण हिस्सा बने हुए हैं।
अंत में, एक संबंधपरक डेटाबेस संरचित और संगठित तरीके से बड़ी मात्रा में डेटा के प्रबंधन के लिए एक शक्तिशाली उपकरण है। पंक्तियों और स्तंभों के साथ तालिकाओं का उपयोग करके और उनके बीच संबंध स्थापित करके, एक रिलेशनल डेटाबेस विभिन्न प्रकार के अनुप्रयोगों के लिए सूचनाओं को कुशलतापूर्वक संग्रहीत और पुनः प्राप्त कर सकता है। रिलेशनल डेटाबेस के प्रबंधन के लिए एक मानक भाषा के रूप में SQL के उपयोग ने डेवलपर्स और उपयोगकर्ताओं के लिए डेटा के साथ इंटरैक्ट करना और हेरफेर करना आसान बना दिया है। डेटा-संचालित अनुप्रयोगों की निरंतर वृद्धि के साथ, रिलेशनल डेटाबेस को समझने और उपयोग करने का महत्व केवल बढ़ता रहेगा। चाहे आप एक प्रोग्रामर हों, डेटा विश्लेषक हों, या केवल कोई व्यक्ति जो अपनी जानकारी को अधिक प्रभावी ढंग से प्रबंधित करना चाहता हो, रिलेशनल डेटाबेस के बारे में सीखना आपके समय और प्रयास का एक मूल्यवान निवेश हो सकता है।
एक संबंधपरक डेटाबेस एक प्रकार का डेटाबेस है जो डेटा को एक या अधिक तालिकाओं या संबंधों में नियमों के एक विशिष्ट सेट के आधार पर व्यवस्थित करता है। तालिकाएँ एक सामान्य फ़ील्ड या कुंजी से जुड़ी या संबंधित होती हैं, जिससे उपयोगकर्ता डेटा तक आसानी से पहुँच और हेरफेर कर सकते हैं।
संबंधपरक डेटाबेस का उपयोग करने के लाभों में शामिल हैं:
एक संबंधपरक डेटाबेस के घटकों में शामिल हैं:
रिलेशनल डेटाबेस में उपयोग की जाने वाली कुंजियों में शामिल हैं:
एक प्राथमिक कुंजी तालिका में प्रत्येक पंक्ति या रिकॉर्ड के लिए एक विशिष्ट पहचानकर्ता है। इसका उपयोग डेटा अखंडता सुनिश्चित करने और कई तालिकाओं में डेटा को लिंक करने के लिए किया जाता है।
एक विदेशी कुंजी एक तालिका में एक फ़ील्ड है जो किसी अन्य तालिका में प्राथमिक कुंजी को संदर्भित करती है। इसका उपयोग तालिकाओं के बीच संबंध स्थापित करने के लिए किया जाता है।
कैंडिडेट कुंजी तालिका में प्रत्येक पंक्ति या रिकॉर्ड के लिए एक अद्वितीय पहचानकर्ता है। इसका उपयोग तालिका के लिए प्राथमिक कुंजी निर्धारित करने के लिए किया जाता है।
समग्र कुंजी दो या दो से अधिक क्षेत्रों का एक संयोजन है जो एक साथ एक तालिका में प्रत्येक पंक्ति या रिकॉर्ड के लिए एक विशिष्ट पहचानकर्ता के रूप में कार्य करता है।
सामान्यीकरण अतिरेक को कम करने और डेटा अखंडता में सुधार करने के लिए डेटाबेस में डेटा को व्यवस्थित करने की प्रक्रिया है। इसमें बड़ी तालिकाओं को छोटी, अधिक विशिष्ट तालिकाओं में तोड़ना और उनके बीच संबंध स्थापित करना शामिल है।
प्रदर्शन को बेहतर बनाने के लिए डीनॉर्मलाइजेशन एक डेटाबेस में अनावश्यक डेटा जोड़ रहा है। इसमें महंगे जुड़ाव और प्रश्नों से बचने के लिए कई तालिकाओं में डेटा की नकल करना शामिल है।
संबंधपरक डेटाबेस प्रबंधन प्रणालियों के उदाहरणों में शामिल हैं:
स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) एक प्रोग्रामिंग लैंग्वेज है जिसका इस्तेमाल रिलेशनल डेटाबेस के साथ संवाद करने के लिए किया जाता है। इसका उपयोग डेटाबेस से डेटा बनाने, संशोधित करने और पुनर्प्राप्त करने के लिए किया जाता है।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


