
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
深入研究 Kotlin 序列化的细微差别,这是管理 Kotlin 应用程序中数据的一个关键方面。本综合指南探讨了如何使用 Kotlin 有效地序列化和反序列化数据。

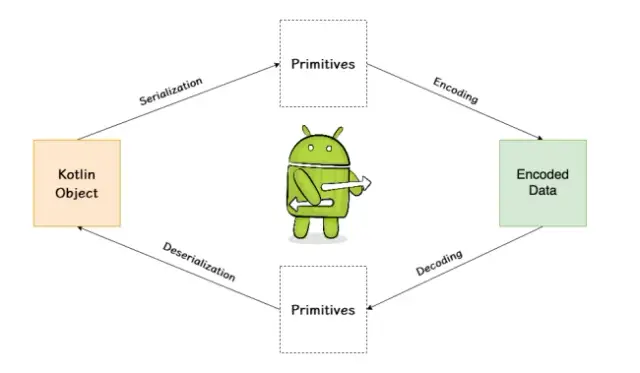
凭借其简洁的语法和强大的功能, Kotlin 正在迅速成为现代 Android 应用程序开发的首选语言。 Kotlin 序列化是显着增强开发体验的一个功能,即将 Kotlin 对象转换为可以方便存储或传输的格式,然后再重建为原始对象的过程。在应用程序频繁与 Web 服务交互、需要数据持久性并依赖复杂数据交换的世界中,这种有效编码和解码数据结构的能力至关重要。序列化不仅是此类任务的技术必要性,也是应对不同数据格式和互操作性需求所带来的挑战的实用解决方案。
Kotlin Serialization 本质上是一个官方 Kotlin 库,旨在将 Kotlin 数据类与 JSON(网络上数据交换的事实上的标准)无缝转换。然而,它的功能还不止于此。该库可以扩展以支持许多其他格式,例如 XML 、Protobuf 或 CBOR。作为 Kotlin 多平台生态系统不可或缺的一部分,它为开发者社区提供了跨多个平台(例如 JVM、 JavaScript 和 Native)处理数据的统一方法,进一步巩固了 Kotlin 作为 软件开发 领域全能玩家的地位。
当今的应用程序开发需求强调了 Kotlin 中高效序列化框架的必要性。当保存到数据库、通过网络发送或本地存储在设备上时,数据必须被序列化。在Android生态系统中,序列化数据通常用于在Activity和Fragment之间传递。 Kotlin 序列化库不仅简化了这些流程,还确保它们以类型感知的方式安全地完成,从而减少了运行时错误的机会并增强了应用程序的弹性。
该库凭借一些基础功能而脱颖而出,例如:
当我们了解 Kotlin 序列化的细微差别时,我们将探索这个库不仅是一个方便的工具,而且是 Kotlin 编程的一个重要方面,它使开发人员能够有效地管理应用程序中的数据。对于那些渴望充分利用 Kotlin 潜力以及渴望进一步改进基于 Kotlin 的应用程序中的数据处理技术的人来说,这次 Kotlin 序列化之旅尤其重要。
对于使用 AppMaster 等平台(提供强大的 无代码 解决方案来构建后端、Web 和移动应用程序)的开发人员来说,Kotlin 序列化可以成为帮助快速数据处理和存储操作的关键组件,与生成的后端流程无缝集成通过平台。
序列化将对象转换为可以存储或传输并随后重建的格式。在 Kotlin 中,这个概念对于许多应用程序至关重要,从保存用户首选项到通过网络发送对象。 Kotlin 序列化库通过直接与语言及其编译时类型系统集成来简化此过程。
有效使用 Kotlin 序列化的第一步是设置您的开发环境。无论您是在处理多平台项目还是针对 JVM 或 Native,设置过程都需要包含 Kotlin 序列化库和序列化插件。以下是如何为 Kotlin 序列化准备项目:
包含 Kotlin 序列化插件:
首先,您必须将 Kotlin 序列化插件添加到构建脚本中。如果您使用 Gradle,则可以将其包含在插件块内的 build.gradle.kts (Kotlin DSL) 或 build.gradle (Groovy DSL) 文件中:
Kotlin DSL:plugins { kotlin("multiplatform") kotlin("plugin.serialization") version "1.5.0"}Groovy DSL:plugins { id 'org.jetbrains.kotlin.multiplatform' version '1.5.0' id 'org.jetbrains.kotlin.plugin.serialization' version '1.5.0'}
添加序列化库依赖项: 添加插件后,下一步是将 Kotlin 序列化库作为依赖项包含在内。您需要在 Gradle 依赖项中指定适合您平台的序列化运行时库:
// For JVMimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json:1.2.2'// For JavaScriptimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-jsLegacy:1.2.2'// For Native or Multiplatformimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-native:1.2.2'
应用序列化插件: 设置插件和依赖项后,序列化插件将在编译期间自动为您的 Kotlin 对象生成必要的序列化器类。
注释可序列化的类:
设置的最后一部分涉及使用 @Serializable 注释来注释 Kotlin 数据类。这指示编译器为这些类生成序列化和反序列化代码:
@Serializabledata class User(val name: String, val age: Int)
此外,通过在项目中正确配置 Kotlin 序列化,您可以确保您的类可以轻松序列化为 JSON 或任何其他支持的格式,并且可以与其他系统无缝互操作。这种设置不仅限于简单的数据对象。尽管如此,它也可以扩展到更复杂的自定义序列化场景,随着项目复杂性的增加,您可能会遇到这种情况。
设置完成后,您就可以开始序列化和反序列化对象。例如:
val user = User("John Doe", 30)val jsonString = Json.encodeToString(User.serializer(), user)val userObject = Json.decodeFromString(User.serializer(), jsonString)
在这里,我们使用 Json 对象将 User 实例编码为 JSON 字符串,并将其解码回 User 对象。 Kotlin 序列化负责将复杂的数据结构转换为 JSON 表示,反之亦然。
掌握 Kotlin 序列化设置的基础知识为构建需要数据持久性、API 通信或多平台支持的应用程序奠定了坚实的基础。随着您越来越熟悉该库,您将欣赏它为高效数据处理提供的细致入微的功能和优化。
图片来源:Kodeco
Kotlin 是一种现代且多功能的编程语言,提供了多种处理 JSON 数据的方法。 JSON 代表 JavaScript 对象表示法,是网络上广泛接受的数据交换标准。 Kotlin 序列化库是将 JSON 数据解析为 Kotlin 对象的关键,反之亦然。这简化了应用程序中的数据处理过程,因为开发人员不需要手动解析 JSON 字符串或编译 JSON 对象。
首先,要将对象序列化为 JSON,您需要使用 @Serialized 注解定义一个 Kotlin 数据类。这告诉 Kotlin 序列化库该类是可序列化的。例如:
import kotlinx.serialization.* import kotlinx.serialization.json.* @Serializable data class User(val name: String, val age: Int)
一旦您的类准备就绪,您就可以使用“Json”对象来序列化和反序列化数据:
val user = User(name = "John Doe", age = 30) // Serialize to JSON val jsonString = Json.encodeToString(user) // Deserialize from JSON val userObj = Json.decodeFromString<User>(jsonString)
Kotlin 序列化库为这些操作提供了“encodeToString”和“decodeFromString”方法。在反序列化过程中,处理由无效 JSON 字符串或不匹配的数据类型引起的异常至关重要。
在某些情况下,您可能需要自定义 JSON 输出。 Kotlin 序列化通过“Json”对象提供配置,可以更改该对象以实现所需的行为,例如漂亮地打印 JSON 或忽略 null 值:
val json = Json { prettyPrint = true; ignoreUnknownKeys = true } val jsonString = json.encodeToString(user)
对于与 API 或任何外部 JSON 数据源的交互,Kotlin 序列化可以有效地用于数据映射。您可以定义一个表示 JSON 结构的类,该库会将传入的 JSON 转换为您的应用程序可以无缝使用的 Kotlin 对象。
另一个重要功能是处理默认值。当 JSON 数据中缺少某些字段时,Kotlin 序列化可以使用数据类中指定的默认值:
@Serializable data class Product(val id: Int, val name: String, val stock: Int = 0)
如果 JSON 输入中省略 'stock' 字段,Kotlin 序列化将使用默认值 0。
解析列表和其他集合也同样简单。通过定义适当的数据类并使用集合类型序列化器,Kotlin 序列化可自动执行数据绑定过程:
val userListJson = "[{\"name\":\"John Doe\",\"age\":30},{\"name\":\"Jane Doe\",\"age\":25}]" val users: List<User> = Json.decodeFromString(userListJson)
在上面的示例中,表示用户列表的 JSON 字符串可以轻松转换为 Kotlin List 对象。
与AppMaster互操作性可以进一步增强 Kotlin 序列化的能力。使用no-code平台生成的项目中的库,开发人员可以处理数据模型并执行快速序列化和反序列化任务,以补充可视化开发工作流程,从而在生成的代码库和数据结构之间保持有效的桥梁。
将 Kotlin 的 JSON 序列化合并到您的项目中会引入一层类型安全性和表现力,从而减少通常与此类操作相关的样板代码。它支持严重依赖 JSON 数据操作的应用程序的快速开发,并为构建数据驱动的 Kotlin 应用程序奠定了基础。
虽然 Kotlin 的序列化库在处理常见序列化需求方面做得非常出色,但有时开发人员会面临针对独特数据类型或复杂序列化逻辑自定义此过程的要求。 Kotlin 中的自定义序列化提供了巨大的灵活性,允许您调整流程以适应精确的规范,确保您的数据不仅安全持久,而且在序列化形式和 Kotlin 对象之间转换时保持完整性。
要实现自定义序列化,开发人员必须深入研究序列化库的内部工作原理并利用其一些核心组件。自定义序列化的基础在于 KSerializer 接口和 @Serializer 注释。自定义序列化程序应该重写 KSerializer 接口提供的 serialize 和 deserialize 方法,以准确指示如何写出和重建对象。
要开始自定义序列化,您必须创建一个实现 KSerializer<T> 接口的类,其中 T 是需要自定义处理的数据类型。在类中,您将重写 serialize 和 deserialize 方法来定义您的逻辑。
import kotlinx.serialization.* import kotlinx.serialization.internal.StringDescriptor @Serializer(forClass = YourDataType::class) object YourDataTypeSerializer : KSerializer<YourDataType> { override val descriptor: SerialDescriptor = StringDescriptor.withName("YourDataType") override fun serialize(encoder: Encoder, obj: YourDataType) { // custom serialization logic here } override fun deserialize(decoder: Decoder): YourDataType { // custom deserialization logic here } }
编写自定义序列化程序后,您可以通过使用 @Serializable 注解数据类来调用它,或者直接在 JSON 对象中使用它来执行临时序列化任务。
更复杂的序列化场景可能包括处理多态性,或者需要序列化无法直接注释的第三方类。在多态性的情况下,Kotlin 序列化使用 @Polymorphic 注释或在模块中注册子类为开箱即用的类层次结构提供支持。然而,对于第三方类,开发人员必须构建自定义序列化器,并在需要这些类型的序列化或反序列化时手动应用它。
定义自定义序列化行为的能力特别有利于:
自定义序列化确保您可以有效地处理任何类型的数据结构或要求,从而实现高精度和对序列化过程的控制。通过对 Kotlin 序列化机制的基本了解,您可以以类型安全和独立的方式解决几乎任何数据处理挑战。
一旦实施,将自定义序列化器集成到项目的工作流程中就非常简单。鉴于 Kotlin 注重互操作性和简洁的语法,自定义序列化自然适合代码。作为一个额外的优势,序列化定义可以是模块化的,可以在不同的模块甚至项目之间共享,从而增强代码的重用性和可维护性。
Kotlin 的序列化功能与自定义序列化器的灵活性相结合,为开发人员处理各种形式的数据带来了新的效率和可靠性水平。对于那些利用AppMaster等平台(通过no-code方法加速后端和应用程序开发)的人来说,Kotlin 序列化通过允许高效的数据交换和存储策略来增强后端,并根据服务的特定需求进行定制。
对于需要超越传统序列化解决方案的开发人员来说,使用 Kotlin 进行自定义序列化是一项强大的功能。无论是专门的数据格式、优化还是与遗留系统的兼容性,Kotlin 提供的灵活性都可确保您的数据处理有效并满足应用程序的独特要求。
开发人员在使用现代应用程序时通常需要管理复杂的数据结构。这些范围可以从嵌套对象和集合到具有复杂序列化逻辑的自定义数据类型。 Kotlin 序列化提供了工具和注释,使我们能够轻松序列化即使是最复杂的数据模型。
首先,考虑嵌套类。当数据类包含另一个类或类列表时,Kotlin 序列化会自动处理它们,前提是涉及的所有类都是可序列化的。您只需使用 @Serializable 注释父类和子类,序列化库就会处理其余的事情。但是,如果您正在处理 Kotlin 序列化不知道如何处理的属性,则可能需要提供自定义序列化器。
对于集合,Kotlin 序列化对于标准库集合(例如列表、集合和映射)开箱即用。集合中的每个元素或键值对都根据其自己的序列化程序进行序列化。这种无缝集成可确保高效、直观地处理集合,而无需额外的开销。
然而,处理自定义集合或数据类型变得更加复杂。在这种情况下,您可以通过为您的类型实现 KSerializer 接口来定义自定义序列化器。在这里,您可以完全控制序列化和反序列化过程,从而可以采用适合您的特定用例的定制方法。例如,需要将数据类型序列化为与默认格式不同的格式,或者需要在此过程中强制执行某些验证规则。
多态序列化是另一个在处理复杂层次结构时增加灵活性的功能。当您有一个具有多个子类的超类并且您想要序列化可能是这些子类中的任何一个的对象时,Kotlin 序列化提供了 @Polymorphic 注解。这样,您可以处理不同子类的集合,同时在序列化和反序列化过程中维护它们的特定类型和属性。
上下文序列化也值得一提。使用 @Contextual 注释,可以根据上下文更改序列化行为,而无需为每种情况编写自定义序列化程序。这一强大的功能允许开发人员抽象重复的序列化逻辑并在各种数据结构中重用它,从而保持干净且可维护的代码。
Kotlin 的序列化库可以通过各种注释和自定义序列化器来处理复杂的数据处理场景。这些功能使开发人员能够自信地处理复杂的序列化任务,确保其数据模型的所有方面都得到适当的保存和传输。因此,无论人们可能遇到多么复杂的数据结构,Kotlin 序列化都提供了必要的灵活性和功能来熟练地管理它们。
性能是任何应用程序功能的关键方面,在处理 Kotlin 序列化时也不例外。应用程序处理数据序列化和反序列化的效率会极大地影响其速度和响应能力。开发人员应该了解影响 Kotlin 应用程序中序列化性能的各种因素。
被序列化的数据对象的大小和复杂性会显着影响性能。具有许多字段或嵌套结构的较大对象比较简单、较小的对象需要更长的时间来处理。同样,数据结构的复杂性(例如递归关系或复杂的层次结构)可能会引入额外的序列化开销。
数据格式是另一个考虑因素。 JSON 是一种基于文本的格式,虽然它具有人类可读性且广泛兼容,但它在性能方面并不总是最有效的,特别是对于大型数据集或性能关键型应用程序。 Protocol Buffers 或 CBOR 等二进制格式可能会提供更好的性能,因为它们更加紧凑并且专为提高效率而设计,尽管它们牺牲了人类可读性。
序列化操作的频率也可以发挥作用。如果应用程序经常将数据序列化作为其核心功能的一部分,那么对性能的累积影响可能会很大。在这种情况下,缓存序列化数据或对临时对象使用不同的序列化策略等策略可能会有所帮助。
选择正确的序列化器至关重要。 Kotlin 序列化提供了一系列内置序列化器,但在某些情况下可能需要自定义序列化器。自定义序列化器可以针对特定类型的数据进行优化,从而提高性能,但它们也需要仔细设计以避免可扩展性较差的解决方案。
序列化操作中的错误处理可能会带来额外的性能成本,尤其是在序列化逻辑中频繁引发异常的情况下。可靠的验证和错误捕获机制可以减少性能影响。
最后,序列化运行的平台和环境会影响性能。不同的环境可能对序列化过程有不同的优化或限制,注意这些可以帮助微调性能。
当我们考虑将 Kotlin 序列化集成到AppMaster这样的平台中(这有助于跨各个领域快速开发应用程序)时,序列化性能的影响就更加明显。鉴于AppMaster生成注重可扩展性和效率的应用程序,确保有效处理序列化有助于实现该平台交付高性能应用程序的承诺。
回顾一下,考虑数据的大小和结构、选择正确的数据格式和序列化器、优化序列化操作的频率和机制、有效的错误处理以及了解运行时环境对于在 Kotlin 序列化过程中实现最佳性能至关重要。
Kotlin 跨多个平台的能力是其最著名的功能之一,而序列化在确保跨所有这些平台的数据处理一致方面发挥着基础作用。 Kotlin 中的多平台项目旨在在不同模块之间共享代码(例如,用于后端的 JVM、用于 Web 的 Kotlin/JS 以及用于桌面或移动应用程序的 Kotlin/Native),这需要采用通用的数据模型和业务逻辑方法。
Kotlin 序列化通过提供单一、一致的方式来序列化和反序列化对象,从而提供了急需的一致性。它抽象了特定于平台的特性,确保来自一个模块的序列化数据可以被另一个模块理解,无论目标平台如何。对于想要为不同环境维护共享代码库的开发人员来说,这一基本特征成为关键的促进因素。
在多平台项目中,您通常在共享模块中定义共同的期望,而实际的特定于平台的实现则位于各自的平台模块中。 Kotlin 序列化通过提供普遍易于理解的 KSerializer 接口和注释,与该模型无缝结合。这意味着您可以在通用代码中定义序列化策略,这将适用于所有平台。
此外,Kotlin 序列化与 Kotlin 的多平台工具集成,允许您根据需要指定特定于平台的序列化格式。例如,虽然 JSON 被普遍使用,但在使用 Kotlin/Native 来提高性能时,您可能希望采用更紧凑的二进制格式,例如 ProtoBuf 或 CBOR。
尽管多平台序列化很方便,但它也并非没有挑战。特定于平台的限制可能会对数据的构造或处理方式施加限制。尽管如此,Kotlin 序列化在设计时就考虑到了可扩展性。开发人员可以通过编写自定义序列化程序或将替代库与标准序列化框架结合使用来克服这些问题,以满足每个平台的特定需求。
一项常见的挑战是处理在其他平台上没有直接等效项的特定于平台的类型。在这种情况下,会出现共享的预期类型与使用特定于平台的类型的实际实现,从而允许您以与平台无关的方式进行序列化和反序列化。
开源 Kotlin 项目的 GitHub 存储库提供了在多平台设置中利用 Kotlin 序列化的真实示例。这些项目受益于统一的数据处理方法,降低了代码库的复杂性,并减少了潜在的错误。
查看 Kotlin 自己的“kotlinx.serialization”库,您可以找到进一步说明如何实现多平台序列化的示例和测试。该库展示了处理针对 JVM、JS 和本机二进制文件的项目中可能出现的序列化问题的技术。
作为多平台项目的关键工具,Kotlin 序列化的作用不仅仅是简化数据处理。它使开发人员能够专注于业务逻辑,而不是陷入数据格式兼容性的复杂性中——这是 Kotlin 努力实现的开发乌托邦。
像AppMaster这样的平台经常模糊传统编码和no-code开发之间的界限。虽然 Kotlin 本身是一种成熟的编码语言,但让开发更容易的基本理念与no-code运动产生了共鸣。通过简化跨多个平台的数据序列化,Kotlin 提供了一个可以与no-code工具共存并补充的后端解决方案。

例如,使用AppMaster加快开发流程与 Kotlin 序列化完美契合。开发人员可以在 Kotlin 中为其应用程序的后端制作 数据模型 和业务逻辑,而前端和 UI 组件可以使用AppMaster的 Web 或移动应用程序可视化构建器来构建。软件开发过程中代码和no-code工具的集成证明了 Kotlin 序列化中嵌入的灵活性和面向未来的思维方式。
安全性是任何应用程序开发过程的一个重要方面,特别是在处理数据的序列化和反序列化时。序列化本质上是将对象的状态转换为可以存储或传输的格式,而反序列化则将此数据转换回对象。在 Kotlin 中,Kotlinx.serialization 库高效且有效地执行此操作,但与任何数据处理操作一样,需要记住重要的安全注意事项。关于安全性,序列化过程可能会带来多种风险,特别是在处理不受信任的数据或将序列化数据暴露给外部实体时。以下是开发人员应警惕的与 Kotlin 序列化相关的一些关键安全问题:
@Transient 注解来注释 Kotlin 类中的敏感字段,以将其排除在序列化之外,从而降低暴露私有数据的风险。为了防范这些风险并确保 Kotlin 序列化的安全,开发人员应遵循以下几个最佳实践:
除了这些预防措施之外,与AppMaster等解决方案集成可以简化数据处理,同时遵守安全最佳实践。 AppMaster的no-code平台生成 后端应用程序,包括序列化和反序列化过程,这些应用程序可以高效、安全地执行,而无需深入研究低级实现细节。关键要点是将安全性视为一个连续的过程,而不是一次性的检查表。正确保护 Kotlin 序列化需要持续保持警惕、了解最新的安全实践知识以及在应用程序的整个生命周期中采取主动的保护方法。
使用任何库或框架时,遵循既定的最佳实践可以大大提高代码的效率和可靠性。 Kotlin 序列化也不例外。无论您处理的是小型项目还是企业级应用程序,遵守指南都可以确保正确处理序列化数据,使您的系统具有互操作性且易于维护。以下是在项目中使用 Kotlin 序列化的一些最佳实践:
也许最简单也是最重要的实践是有效利用 Kotlin 的内置注释:
@Serializable :使用 @Serializable 注解你的数据类,告诉 Kotlin 该类可以自动序列化。@Transient :不应序列化的字段可以用 @Transient 标记,这会在序列化过程中默默地忽略它们。@SerialName :如果需要更改序列化表单中的字段名称,请使用 @SerialName 定义自定义名称。@Required :您可以使用 @Required 标记必须始终出现在 JSON 数据中的不可为空字段;这可确保该字段在缺失时不会默认为 null 。注解是 Kotlin Serialization 提供的强大工具,可以使序列化和反序列化过程变得清晰直观。
充分利用 Kotlin 作为一门语言的优势:
val 而不是 var 来尽可能拥抱不变性。这提高了跨序列化状态的线程安全性和可预测性。仔细记录您的数据模型:
这种做法对于团队和维护长期项目尤其重要,其他人可能需要了解您的序列化设计选择背后的原因。
序列化可能因多种原因而失败。优雅地处理这些场景至关重要:
虽然 Kotlin 序列化可以开箱即用地处理许多情况,但有时您需要更多控制:
自定义序列化程序可以为您提供对过程的细粒度控制,但仅应在必要时使用,因为它们会使您的代码库变得复杂。
与任何活跃的库一样,Kotlin 序列化也在不断改进:
Kotlin 序列化插件有几个配置选项:
build.gradle 文件中调整这些设置,以根据项目的需求定制插件的行为。通过遵循这些最佳实践,您将确保对 Kotlin 序列化的使用有效并针对未来的开发进行了优化。当这些实践应用于AppMaster这样的no-code平台时,您可以进一步提高工作效率并充分利用 Kotlin 的全部潜力,与平台的强大应用程序开发功能同步。
复杂技术的无缝集成对于现代软件开发的发展至关重要。 Kotlin Serialization 是一个强大的数据处理工具包,与旨在加快开发过程的平台(例如AppMaster具有非常好的协同作用。这种协同关系支撑了以数据为中心的应用程序的动态特性。
AppMaster是一个先进的no-code平台,可为后端、Web 和移动应用程序生成真正的源代码,其核心在于高效数据序列化的需求。由于其简洁性和互操作性,Kotlin 在很多场景下都是后端开发的首选,而对于AppMaster内部的数据交换,Kotlin 序列化是必不可少的工具。
序列化是AppMaster使用 Go 的 后端生成器以及依赖 Kotlin 和 Swift 的 移动应用程序创建的一个重要方面。虽然后端主要使用 Go,但在将移动应用程序桥接到各种后端服务时,Kotlin 的作用就开始发挥作用。在这里,Kotlin 序列化简化了 Kotlin 对象到 JSON 格式字符串的转换,从而确保移动应用程序和后端服务之间顺利的数据处理和交换。
当用户通过AppMaster设计数据模型或配置业务逻辑时,该平台可以利用 Kotlin 序列化来实现移动endpoints 。序列化(将对象转换为 JSON)和反序列化(JSON 返回 Kotlin 对象)的循环过程通常是自动化的,从而提高了开发效率并最大限度地减少了人为错误的范围。
此外,由于能够处理包括嵌套类和集合在内的复杂数据结构,Kotlin Serialization 完美补充了AppMaster的数据建模功能。无论是简单的 CRUD操作 还是复杂的事务,结构化数据都可以轻松地序列化和反序列化,确保在应用程序的整个生命周期中保持数据完整性。
与AppMaster平台集成还允许在无缝连续交付系统中利用 Kotlin 序列化。随着应用程序随着需求的变化而发展, AppMaster从头开始重新生成应用程序,在这个过程中,Kotlin 序列化可以重新绑定对象和数据模式,而不会积累 技术债务。
就多平台功能而言,Kotlin 序列化是值得称赞的盟友。虽然AppMaster倡导跨平台应用程序的快速开发,但 Kotlin 序列化提供了跨这些平台一致处理数据所需的灵活性和可靠性。这使得从概念化到部署的路径大大简化,并且更符合支持多平台策略的现代开发协议。
将 Kotlin 序列化集成到AppMaster生态系统中,增强了该平台的承诺,即提供一个环境,即使没有传统编码经验的人也可以创建高性能、可扩展且复杂的应用程序。它证明了将现代序列化技术的功能与创新开发平台相结合的力量,可以真正实现应用程序创建体验的民主化。
Kotlin Serialization 是一个库,它提供了一种将 Kotlin 对象转换为字符串格式(例如 JSON)的方法,以便可以轻松地存储或传输它们,然后将其重构回对象。
要设置 Kotlin 序列化,您需要将适当的插件和依赖项添加到 build.gradle 文件中。同步项目后,您可以使用该库来序列化和反序列化对象。
是的,Kotlin 序列化可以根据需要使用各种注释和自定义序列化器来管理复杂的数据结构,包括嵌套类、集合和自定义类型。
Kotlin 序列化在设计时就考虑到了多平台支持。它可以跨不同平台使用,例如 JVM、JavaScript、Native,并且跨这些平台支持 JSON 等常见格式。
Kotlin Serialization 在后端服务的开发中可以与AppMaster等平台集成,提高构建 Web、移动和后端应用程序的效率。数据模型可以使用 Kotlin 进行序列化和反序列化,有助于有效的数据处理和存储。
Kotlin 序列化的最佳实践包括使用最新版本的库、遵守惯用的 Kotlin 代码、利用内置序列化器、在需要时编写自定义序列化器以及确保正确的错误处理。
自定义序列化是通过为复杂或非标准类型定义您自己的序列化器来处理的,通过使用注释和实现 KSerializer 接口提供控制数据序列化和反序列化方式的灵活性。
数据序列化很重要,因为它允许将数据转换为易于存储、传输和重构的格式,从而促进不同系统或应用程序部分之间的有效通信。
虽然 Kotlin 序列化主要关注 JSON,但它可以扩展以支持其他格式,例如 Protobuf、CBOR,甚至具有自定义序列化器和格式实现的 XML。
注意事项包括序列化数据的大小和复杂性、对象的数量以及使用的格式。分析和优化序列化过程以防止应用程序出现瓶颈非常重要。




