Kotlin est en passe de devenir le langage de choix pour le développement d'applications Android modernes, grâce à sa syntaxe concise et ses fonctionnalités puissantes. Une fonctionnalité qui améliore considérablement l'expérience de développement est la sérialisation Kotlin, le processus de traduction des objets Kotlin dans un format qui peut être facilement stocké ou transféré, puis reconstruit en objets originaux. Cette capacité à encoder et décoder efficacement les structures de données est essentielle dans un monde où les applications interagissent fréquemment avec les services Web, nécessitent la persistance des données et s'appuient sur un échange de données complexe. La sérialisation n'est pas seulement une nécessité technique pour de telles tâches, mais également une solution pratique aux défis posés par les différents formats de données et au besoin d'interopérabilité.
Kotlin Serialization, en substance, est une bibliothèque Kotlin officielle conçue pour convertir de manière transparente les classes de données Kotlin vers et depuis JSON, la norme de facto pour l'échange de données sur le Web. Pourtant, ses capacités ne s’arrêtent pas là ; la bibliothèque peut être étendue pour prendre en charge de nombreux autres formats, tels que XML , Protobuf ou CBOR. Partie intégrante de l'écosystème Kotlin Multiplatform, il offre à la communauté des développeurs une approche unifiée pour gérer les données sur plusieurs plates-formes, telles que JVM, JavaScript et Native, renforçant ainsi la position de Kotlin en tant qu'acteur polyvalent du développement de logiciels .
Les exigences actuelles en matière de développement d'applications soulignent la nécessité d'un cadre de sérialisation efficace dans Kotlin. Les données doivent être sérialisées lors de l'enregistrement dans une base de données, de l'envoi sur le réseau ou du stockage local sur un appareil. Dans l'écosystème Android, les données sérialisées sont couramment utilisées pour passer d'une activité à l'autre et de fragments à l'autre. La bibliothèque de sérialisation Kotlin rationalise non seulement ces processus, mais garantit également qu'ils sont effectués en toute sécurité et en tenant compte du type, réduisant ainsi les risques d'erreurs d'exécution et améliorant la résilience des applications.
La bibliothèque se distingue par quelques fonctionnalités fondamentales, telles que :
- Une API intuitive qui nécessite un minimum de code passe-partout.
- Intégration transparente avec les fonctionnalités du langage Kotlin telles que les paramètres par défaut et la sécurité nulle.
- Sécurité au moment de la compilation garantissant que seules les données sérialisables sont traitées, évitant ainsi les erreurs de sérialisation au moment de l'exécution.
- Prise en charge de divers formats de sérialisation et flexibilité des sérialiseurs personnalisés pour des cas d'utilisation spécialisés.
En parcourant les nuances de la sérialisation Kotlin, nous explorerons comment cette bibliothèque n'est pas seulement un outil pratique mais un aspect essentiel de la programmation Kotlin qui permet aux développeurs de gérer efficacement les données au sein de leurs applications. Ce voyage dans la sérialisation Kotlin est particulièrement pertinent pour ceux qui aspirent à exploiter tout le potentiel de Kotlin et pour ceux désireux d'améliorer encore leurs techniques de traitement des données dans les applications basées sur Kotlin.
Pour les développeurs qui utilisent des plates-formes comme AppMaster , qui offre une puissante solution sans code pour créer des applications backend, Web et mobiles, la sérialisation Kotlin peut être un élément clé pour faciliter les opérations rapides de traitement et de stockage des données, en s'intégrant de manière transparente aux processus backend générés. par la plateforme.
Sérialisation dans Kotlin : bases et configuration
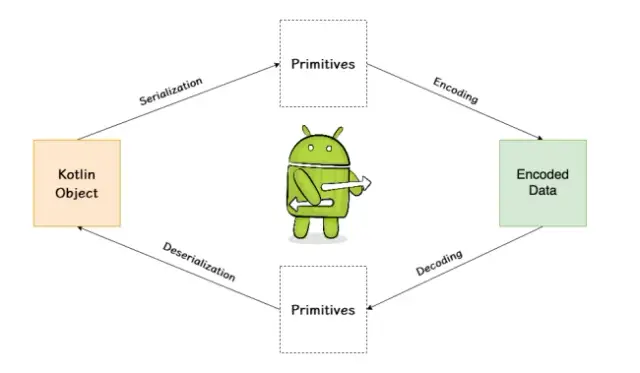
La sérialisation convertit un objet dans un format qui peut être stocké ou transmis et reconstruit ultérieurement. Dans Kotlin, ce concept est crucial pour de nombreuses applications, de la sauvegarde des préférences utilisateur à l'envoi d'objets sur le réseau. La bibliothèque de sérialisation Kotlin simplifie ce processus en s'intégrant directement au langage et à son système de types au moment de la compilation.
La première étape pour utiliser efficacement la sérialisation Kotlin consiste à configurer votre environnement de développement. Que vous travailliez sur un projet multiplateforme ou que vous cibliez la JVM ou le Native, le processus de configuration nécessite d'inclure la bibliothèque de sérialisation Kotlin et le plugin de sérialisation. Voici comment préparer votre projet pour la sérialisation Kotlin :
-
Incluez le plugin de sérialisation Kotlin :
Tout d’abord, vous devez ajouter le plugin Kotlin Serialization à votre script de build. Si vous utilisez Gradle, vous l'incluez dans votre fichier build.gradle.kts (Kotlin DSL) ou build.gradle (Groovy DSL) dans le bloc plugins :
Kotlin DSL:plugins { kotlin("multiplatform") kotlin("plugin.serialization") version "1.5.0"}Groovy DSL:plugins { id 'org.jetbrains.kotlin.multiplatform' version '1.5.0' id 'org.jetbrains.kotlin.plugin.serialization' version '1.5.0'}
-
Ajouter des dépendances de bibliothèque de sérialisation :
Après avoir ajouté le plugin, l'étape suivante consiste à inclure la bibliothèque de sérialisation Kotlin en tant que dépendance. Vous devrez spécifier la bibliothèque d'exécution de sérialisation adaptée à votre plateforme dans vos dépendances Gradle :
// For JVMimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json:1.2.2'// For JavaScriptimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-jsLegacy:1.2.2'// For Native or Multiplatformimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-native:1.2.2'
-
Appliquez le plugin de sérialisation :
Une fois le plugin et les dépendances configurés, le plugin Serialization générera automatiquement les classes de sérialiseur nécessaires pour vos objets Kotlin lors de la compilation.
-
Annoter les classes sérialisables :
La dernière partie de la configuration consiste à annoter vos classes de données Kotlin avec l'annotation @Serializable . Cela signale au compilateur de générer du code de sérialisation et de désérialisation pour ces classes :
@Serializabledata class User(val name: String, val age: Int)
De plus, en configurant correctement la sérialisation Kotlin dans votre projet, vous vous assurez que vos classes peuvent être facilement sérialisées au format JSON, ou tout autre format pris en charge, et peuvent interagir de manière transparente avec d'autres systèmes. Cette configuration ne se limite pas à de simples objets de données. Néanmoins, il peut également être étendu à des scénarios de sérialisation personnalisés plus complexes, que vous pouvez rencontrer à mesure que la complexité de votre projet augmente.
Initialisation du sérialiseur
Une fois la configuration terminée, vous pouvez commencer à sérialiser et désérialiser les objets. Par exemple:
val user = User("John Doe", 30)val jsonString = Json.encodeToString(User.serializer(), user)val userObject = Json.decodeFromString(User.serializer(), jsonString)
Ici, nous avons utilisé l'objet Json pour encoder une instance User en chaîne JSON et la décoder en objet User . Kotlin Serialization prend en charge les subtilités de la transformation de structures de données complexes en représentations JSON et vice versa.
La maîtrise des bases de la configuration de la sérialisation Kotlin constitue une base solide pour créer des applications nécessitant la persistance des données, la communication API ou la prise en charge multiplateforme. Au fur et à mesure que vous vous familiariserez avec la bibliothèque, vous apprécierez les fonctionnalités nuancées et les optimisations qu'elle offre pour une gestion efficace des données.
Source de l'image : Kodeco
Travailler avec JSON dans la sérialisation Kotlin
Kotlin, étant un langage de programmation moderne et polyvalent, propose différentes manières de travailler avec les données JSON. JSON signifie JavaScript Object Notation et constitue une norme largement acceptée pour l'échange de données sur le Web. La bibliothèque de sérialisation Kotlin est essentielle pour analyser les données JSON en objets Kotlin et vice versa. Cela simplifie le processus de traitement des données dans les applications, car les développeurs n'ont pas besoin d'analyser manuellement les chaînes JSON ni de compiler les objets JSON.
Tout d'abord, pour sérialiser des objets en JSON, vous devez définir une classe de données Kotlin avec l'annotation `@Serializing`. Cela indique à la bibliothèque de sérialisation Kotlin que la classe est sérialisable. Par exemple:
import kotlinx.serialization.* import kotlinx.serialization.json.* @Serializable data class User(val name: String, val age: Int)
Une fois votre classe prête, vous pouvez utiliser l'objet `Json` pour sérialiser et désérialiser les données :
val user = User(name = "John Doe", age = 30) // Serialize to JSON val jsonString = Json.encodeToString(user) // Deserialize from JSON val userObj = Json.decodeFromString<User>(jsonString)
La bibliothèque de sérialisation Kotlin propose les méthodes `encodeToString` et `decodeFromString` pour ces opérations. Il est essentiel de gérer les exceptions résultant de chaînes JSON non valides ou de types de données incompatibles pendant le processus de désérialisation.
Dans certains cas, vous devrez peut-être personnaliser la sortie JSON. La sérialisation Kotlin fournit des configurations via l'objet « Json » qui peuvent être modifiées pour obtenir les comportements requis, tels que l'impression jolie du JSON ou l'ignorance des valeurs nulles :
val json = Json { prettyPrint = true; ignoreUnknownKeys = true } val jsonString = json.encodeToString(user)
Pour l'interaction avec les API ou toute source de données JSON externe, la sérialisation Kotlin peut être utilisée efficacement pour le mappage des données. Vous pouvez définir une classe représentant la structure JSON et la bibliothèque convertit le JSON entrant en objets Kotlin avec lesquels votre application peut fonctionner de manière transparente.
Une autre fonctionnalité importante concerne la gestion des valeurs par défaut. Lorsque certains champs sont manquants dans les données JSON, la sérialisation Kotlin peut utiliser les valeurs par défaut spécifiées dans la classe de données :
@Serializable data class Product(val id: Int, val name: String, val stock: Int = 0)
Si le champ « stock » est omis dans l'entrée JSON, la sérialisation Kotlin utilisera la valeur par défaut de 0.
L’analyse des listes et autres collections est tout aussi simple. En définissant la classe de données appropriée et en utilisant les sérialiseurs de type de collection, Kotlin Serialization automatise le processus de liaison de données :
val userListJson = "[{\"name\":\"John Doe\",\"age\":30},{\"name\":\"Jane Doe\",\"age\":25}]" val users: List<User> = Json.decodeFromString(userListJson)
Dans l'exemple ci-dessus, la chaîne JSON représentant une liste d'utilisateurs est facilement convertie en un objet Kotlin List.
L'interopérabilité avec AppMaster peut améliorer encore les capacités de sérialisation Kotlin. En utilisant la bibliothèque dans les projets générés par la plateforme no-code, les développeurs peuvent gérer des modèles de données et effectuer des tâches de sérialisation et de désérialisation rapides qui complètent le flux de travail de développement visuel, en maintenant un pont efficace entre la base de code générée et les structures de données.
L'intégration de la sérialisation JSON de Kotlin dans votre projet introduit une couche de sécurité de type et d'expressivité, réduisant ainsi le code passe-partout généralement associé à de telles opérations. Il prend en charge le développement rapide d'applications qui s'appuient fortement sur la manipulation de données JSON et jette les bases de la création d'applications Kotlin basées sur les données.
Sérialisation personnalisée avec Kotlin
Bien que la bibliothèque de sérialisation de Kotlin fasse un excellent travail pour répondre aux besoins courants de sérialisation, il y aura des moments où les développeurs seront confrontés à la nécessité de personnaliser ce processus pour des types de données uniques ou une logique de sérialisation sophistiquée. La sérialisation personnalisée dans Kotlin offre une immense flexibilité, vous permettant de façonner le processus en fonction de spécifications exactes, garantissant non seulement que vos données persistent en toute sécurité, mais maintiennent également leur intégrité lors de la transition entre leur forme sérialisée et les objets Kotlin.
Pour implémenter une sérialisation personnalisée, les développeurs doivent se plonger dans le fonctionnement interne de la bibliothèque de sérialisation et utiliser certains de ses composants principaux. La base de la sérialisation personnalisée réside dans l'interface KSerializer et l'annotation @Serializer . Un sérialiseur personnalisé doit remplacer les méthodes serialize et deserialize fournies par l'interface KSerializer pour dicter exactement la manière dont un objet est écrit et reconstruit.
Création de sérialiseurs personnalisés
Pour commencer avec la sérialisation personnalisée, vous devez créer une classe qui implémente l'interface KSerializer<T> , où T est le type de données qui nécessite une gestion personnalisée. Au sein de la classe, vous remplacerez les méthodes serialize et deserialize pour définir votre logique.
import kotlinx.serialization.* import kotlinx.serialization.internal.StringDescriptor @Serializer(forClass = YourDataType::class) object YourDataTypeSerializer : KSerializer<YourDataType> { override val descriptor: SerialDescriptor = StringDescriptor.withName("YourDataType") override fun serialize(encoder: Encoder, obj: YourDataType) { // custom serialization logic here } override fun deserialize(decoder: Decoder): YourDataType { // custom deserialization logic here } }
Une fois votre sérialiseur personnalisé écrit, vous pouvez l'invoquer en annotant votre classe de données avec @Serializable ou en l'utilisant directement dans l'objet JSON pour des tâches de sérialisation ad hoc.
Gestion de scénarios complexes
Des scénarios de sérialisation plus complexes peuvent inclure la gestion du polymorphisme ou la nécessité de sérialiser des classes tierces qui ne peuvent pas être annotées directement. Dans le cas du polymorphisme, la sérialisation Kotlin fournit une prise en charge prête à l'emploi des hiérarchies de classes en utilisant l'annotation @Polymorphic ou en enregistrant des sous-classes dans un module. Néanmoins, pour les classes tierces, les développeurs doivent créer un sérialiseur personnalisé et l'appliquer manuellement chaque fois que la sérialisation ou la désérialisation de ces types est requise.
Avantages de la sérialisation personnalisée
La possibilité de définir un comportement de sérialisation personnalisé est particulièrement bénéfique pour :
- Gérer les systèmes existants où les formats de données ne correspondent pas aux normes modernes.
- Interopérer avec des services externes qui peuvent utiliser des formats non standards ou nécessiter des structures de données spécifiques.
- Optimisation des performances en adaptant la sortie sérialisée pour une efficacité en termes de taille ou de vitesse.
La sérialisation personnalisée garantit que vous pouvez travailler efficacement avec tout type de structure ou d'exigence de données, permettant une haute précision et un contrôle élevé sur le processus de sérialisation. Grâce à la compréhension fondamentale des mécanismes de sérialisation dans Kotlin, vous pouvez relever pratiquement tous les défis de gestion des données de manière sécurisée et autonome.
Intégration de sérialiseurs personnalisés
L'intégration de sérialiseurs personnalisés dans le flux de travail de votre projet est simple une fois mise en œuvre. Étant donné l'accent mis par Kotlin sur l'interopérabilité et la syntaxe concise, la sérialisation personnalisée s'intègre naturellement dans le code. Comme avantage supplémentaire, les définitions de sérialisation peuvent être modulaires, partagées entre différents modules ou même projets, améliorant ainsi la réutilisation et la maintenabilité du code.
Les capacités de sérialisation de Kotlin, associées à la flexibilité des sérialiseurs personnalisés, ouvrent de nouveaux niveaux d'efficacité et de fiabilité aux développeurs gérant diverses formes de données. Et pour ceux qui exploitent des plates-formes comme AppMaster, qui accélèrent le développement du backend et des applications grâce à une approche no-code, la sérialisation Kotlin améliore le backend en permettant des stratégies efficaces d'échange de données et de stockage, adaptées aux besoins spécifiques du service.
La sérialisation personnalisée avec Kotlin est une fonctionnalité puissante pour les développeurs qui doivent aller au-delà des solutions de sérialisation conventionnelles. Qu'il s'agisse de formats de données spécialisés, d'optimisation ou de compatibilité avec les systèmes existants, la flexibilité offerte par Kotlin garantit que votre traitement de données est puissant et répond aux exigences uniques de votre application.
Gestion de structures de données complexes
Les développeurs doivent souvent gérer des structures de données complexes lorsqu'ils travaillent avec des applications modernes. Ceux-ci peuvent aller des objets et collections imbriqués aux types de données personnalisés avec une logique de sérialisation sophistiquée. Kotlin Serialization fournit des outils et des annotations qui nous permettent de sérialiser facilement même les modèles de données les plus complexes.
Tout d’abord, considérons les classes imbriquées. Lorsqu'une classe de données contient une autre classe ou une liste de classes, la sérialisation Kotlin les gère automatiquement à condition que toutes les classes impliquées soient sérialisables. Vous annotez simplement les classes parent et enfant avec @Serializable , et la bibliothèque de sérialisation s'occupe du reste. Mais si vous avez affaire à une propriété que Kotlin Serialization ne sait pas gérer, vous devrez peut-être fournir un sérialiseur personnalisé.
Pour les collections, la sérialisation Kotlin fonctionne immédiatement pour les collections de bibliothèques standard telles que les listes, les ensembles et les cartes. Chaque élément ou paire clé-valeur de la collection est sérialisé conformément à son propre sérialiseur. Cette intégration transparente garantit que les collections sont gérées de manière efficace et intuitive sans frais supplémentaires.
Cependant, gérer des collections ou des types de données personnalisés devient plus complexe. Dans de tels scénarios, vous définissez un sérialiseur personnalisé en implémentant l'interface KSerializer pour votre type. Ici, vous avez un contrôle total sur le processus de sérialisation et de désérialisation, permettant une approche sur mesure adaptée à votre cas d'utilisation spécifique. Un exemple serait un type de données qui doit être sérialisé dans un format différent de celui par défaut, ou lorsque vous devez appliquer certaines règles de validation pendant le processus.
La sérialisation polymorphe est une autre fonctionnalité qui ajoute de la flexibilité lors de la gestion de hiérarchies complexes. Lorsque vous disposez d'une superclasse avec plusieurs sous-classes et que vous souhaitez sérialiser un objet qui pourrait être l'une de ces sous-classes, Kotlin Serialization fournit l'annotation @Polymorphic . Avec cela, vous pouvez gérer une collection de différentes sous-classes tout en conservant leurs types et propriétés spécifiques lors de la sérialisation et de la désérialisation.
La sérialisation contextuelle mérite également d'être mentionnée. Avec l'annotation @Contextual , le comportement de la sérialisation peut être modifié en fonction du contexte sans avoir à écrire de sérialiseurs personnalisés pour chaque cas. Cette fonctionnalité puissante permet aux développeurs d'abstraire la logique de sérialisation répétitive et de la réutiliser dans diverses structures de données, conservant ainsi un code propre et maintenable.
La bibliothèque de sérialisation de Kotlin est équipée pour gérer des scénarios complexes de gestion de données via diverses annotations et sérialiseurs personnalisés. Ces fonctionnalités permettent aux développeurs d'aborder en toute confiance des tâches de sérialisation complexes, en garantissant que tous les aspects de leur modèle de données sont correctement préservés et transmis. En conséquence, quelle que soit la complexité des structures de données que l'on peut rencontrer, la sérialisation Kotlin offre la flexibilité et la puissance nécessaires pour les gérer efficacement.
Les performances sont un aspect essentiel de la fonctionnalité de toute application, ce qui n'est pas différent lorsqu'il s'agit de la sérialisation Kotlin. L'efficacité avec laquelle une application gère la sérialisation et la désérialisation des données peut avoir un impact considérable sur sa vitesse et sa réactivité. Les développeurs doivent connaître divers facteurs affectant les performances de sérialisation dans leurs applications Kotlin.
La taille et la complexité des objets de données sérialisés peuvent affecter considérablement les performances. Les objets plus grands comportant de nombreux champs ou structures imbriquées prennent plus de temps à traiter que les objets plus simples et plus petits. De même, les subtilités de la structure des données, telles que les relations récursives ou les hiérarchies complexes, peuvent introduire une surcharge de sérialisation supplémentaire.
Le format des données est une autre considération. JSON est un format texte et, bien qu'il soit lisible par l'homme et largement compatible, il n'est pas toujours le plus efficace en termes de performances, en particulier pour les grands ensembles de données ou dans les applications critiques en termes de performances. Les formats binaires tels que Protocol Buffers ou CBOR peuvent offrir de meilleures performances car ils sont plus compacts et conçus pour l'efficacité, même s'ils sacrifient la lisibilité humaine.
La fréquence des opérations de sérialisation peut également jouer un rôle. Les effets cumulatifs sur les performances peuvent être substantiels si une application sérialise fréquemment les données dans le cadre de ses fonctionnalités de base. Dans de tels cas, des stratégies telles que la mise en cache des données sérialisées ou l'utilisation d'une stratégie de sérialisation différente pour les objets temporaires pourraient être bénéfiques.
Choisir les bons sérialiseurs est crucial. Kotlin Serialization fournit une gamme de sérialiseurs intégrés, mais il peut y avoir des scénarios dans lesquels des sérialiseurs personnalisés sont nécessaires. Les sérialiseurs personnalisés peuvent être optimisés pour des types spécifiques de données, ce qui entraîne des améliorations de performances, mais ils nécessitent également une conception minutieuse pour éviter des solutions peu évolutives.
La gestion des erreurs dans les opérations de sérialisation peut entraîner des coûts de performances supplémentaires, en particulier si des exceptions sont fréquemment générées dans la logique de sérialisation. Un mécanisme solide de validation et de détection des erreurs peut réduire l’impact sur les performances.
Enfin, la plate-forme et l'environnement dans lesquels s'effectue la sérialisation peuvent avoir un impact sur les performances. Différents environnements peuvent avoir différentes optimisations ou limitations pour les processus de sérialisation, et en tenir compte peut aider à affiner les performances.
Lorsque l’on considère l’intégration de la sérialisation Kotlin dans des plateformes comme AppMaster, qui facilite le développement rapide d’applications sur différents segments, les implications des performances de sérialisation sont encore plus prononcées. Étant donné AppMaster génère des applications axées sur l'évolutivité et l'efficacité, garantir que la sérialisation est gérée efficacement contribue à la promesse de la plate-forme de fournir des applications hautes performances.
Pour récapituler, compte tenu de la taille et de la structure des données, la sélection du format de données et du sérialiseur appropriés, l'optimisation de la fréquence et du mécanisme des opérations de sérialisation, une gestion efficace des erreurs et la compréhension de l'environnement d'exécution sont essentielles pour obtenir des performances optimales dans les processus de sérialisation Kotlin.
La capacité de Kotlin à chevaucher plusieurs plates-formes est l'une de ses fonctionnalités les plus célèbres, et la sérialisation joue un rôle fondamental pour garantir une gestion cohérente des données sur toutes ces plates-formes. Les projets multiplateformes dans Kotlin visent à partager du code entre différents modules (par exemple, JVM pour le backend, Kotlin/JS pour le Web et Kotlin/Native pour les applications de bureau ou mobiles), ce qui nécessite une approche commune des modèles de données et de la logique métier.
La sérialisation Kotlin offre l'uniformité indispensable en fournissant un moyen unique et cohérent de sérialiser et de désérialiser des objets. Il élimine les particularités spécifiques à la plate-forme, garantissant que les données sérialisées d'un module peuvent être comprises par un autre, quelle que soit la plate-forme cible. Cette caractéristique essentielle devient un facilitateur essentiel pour les développeurs qui souhaitent maintenir une base de code partagée pour différents environnements.
Implémentation de la sérialisation dans un contexte multiplateforme
Dans un projet multiplateforme, vous définissez généralement des attentes communes dans le module partagé, tandis que les implémentations réelles spécifiques à la plateforme résident dans les modules de plateforme respectifs. La sérialisation Kotlin s'aligne parfaitement sur ce modèle en offrant des interfaces et des annotations KSerializer universellement intelligibles. Cela signifie que vous pouvez définir des stratégies de sérialisation dans votre code commun, qui s'appliqueront sur toutes les plateformes.
De plus, Kotlin Serialization s'intègre aux outils multiplateformes de Kotlin, vous permettant de spécifier des formats de sérialisation spécifiques à la plateforme si nécessaire. Par exemple, bien que JSON soit universellement utilisé, vous souhaiterez peut-être recourir à des formats binaires plus compacts comme ProtoBuf ou CBOR lorsque vous travaillez avec Kotlin/Native pour gagner en performances.
Défis et solutions
Malgré ses commodités, la sérialisation multiplateforme n'est pas sans défis. Les limitations spécifiques à la plate-forme peuvent imposer des contraintes sur la manière dont les données sont structurées ou traitées. Néanmoins, la sérialisation Kotlin est conçue dans un souci d’extensibilité. Les développeurs peuvent surmonter ces problèmes en écrivant des sérialiseurs personnalisés ou en utilisant des bibliothèques alternatives en conjonction avec le cadre de sérialisation standard pour répondre aux besoins spécifiques de chaque plate-forme.
Un défi courant consiste à gérer des types spécifiques à une plate-forme qui n’ont pas d’équivalents directs sur d’autres plates-formes. Dans de tels cas, un type attendu partagé avec des implémentations réelles utilisant des types spécifiques à la plate-forme s'ensuit, vous permettant de sérialiser et de désérialiser d'une manière indépendante de la plate-forme.
Études de cas et exemples
Les référentiels GitHub des projets Kotlin open source fournissent des exemples concrets d'utilisation de la sérialisation Kotlin dans des paramètres multiplateformes. Ces projets bénéficient d'une approche unifiée de la gestion des données, réduisant la complexité de la base de code et réduisant le risque d'erreurs.
En consultant la bibliothèque « kotlinx.serialization » de Kotlin, vous pouvez trouver des exemples et des tests qui illustrent davantage comment implémenter la sérialisation multiplateforme. La bibliothèque présente des techniques permettant de résoudre les problèmes de sérialisation pouvant survenir dans les projets ciblant JVM, JS et les binaires natifs.
En tant qu'outil essentiel pour les projets multiplateformes, la sérialisation Kotlin fait plus que simplement simplifier la gestion des données. Il permet aux développeurs de se concentrer sur la logique métier plutôt que de s’enliser dans les subtilités de la compatibilité des formats de données – une utopie de développement que Kotlin s’efforce de réaliser.
Le rôle de la sérialisation Kotlin dans le mouvement No-code
Les plates-formes comme AppMaster brouillent souvent les frontières entre le codage traditionnel et le développement no-code. Bien que Kotlin lui-même soit un langage de codage à part entière, la philosophie sous-jacente consistant à rendre le développement plus accessible résonne avec le mouvement no-code. En simplifiant la sérialisation des données sur plusieurs plates-formes, Kotlin fournit une solution backend qui peut coexister et compléter les outils no-code.

Avec AppMaster, par exemple, l'accélération du processus de développement s'aligne parfaitement avec la sérialisation Kotlin. Les développeurs peuvent créer les modèles de données et la logique métier pour le backend de leur application dans Kotlin, tandis que les composants frontend et UI peuvent être construits à l'aide des constructeurs visuels d' AppMaster pour les applications Web ou mobiles. Cette intégration d'outils de code et no-code dans le processus de développement logiciel témoigne de la flexibilité et de l'esprit d'avenir intégrés à la sérialisation Kotlin.
Sérialisation et sécurité Kotlin
Lorsque vous travaillez avec n'importe quelle bibliothèque ou framework, suivre les meilleures pratiques établies peut considérablement augmenter l'efficacité et la fiabilité de votre code. La sérialisation Kotlin ne fait pas exception. Que vous ayez affaire à un petit projet ou à une application d'entreprise, le respect des directives garantit que vos données sérialisées sont traitées correctement, ce qui rend vos systèmes interopérables et faciles à entretenir. Voici plusieurs bonnes pratiques pour utiliser la sérialisation Kotlin dans vos projets :
Utiliser la sérialisation basée sur les annotations
La pratique la plus simple et la plus importante consiste peut-être à utiliser efficacement les annotations intégrées de Kotlin :
@Serializable : Annotez votre classe de données avec @Serializable pour indiquer à Kotlin que cette classe peut être sérialisée automatiquement.@Transient : les champs qui ne doivent pas être sérialisés peuvent être marqués avec @Transient , qui les omet silencieusement du processus de sérialisation.@SerialName : Si vous devez modifier le nom d'un champ dans le formulaire sérialisé, utilisez @SerialName pour définir un nom personnalisé.@Required : Vous pouvez marquer les champs non nullables qui doivent toujours être présents dans les données JSON en utilisant @Required ; cela garantit que le champ ne sera pas null par défaut s'il est manquant.
Les annotations sont des outils puissants fournis par Kotlin Serialization pour rendre les processus de sérialisation et de désérialisation clairs et intuitifs.
Adhérer aux normes de codage Kotlin
Exploitez les atouts de Kotlin en tant que langage :
- Préférez les classes de données pour la sérialisation car elles ont une compatibilité innée avec les processus de sérialisation.
- Adoptez l'immuabilité lorsque cela est possible en utilisant
val sur var pour les propriétés sérialisées. Cela favorise la sécurité des threads et la prévisibilité entre les états sérialisés.
- Profitez de l’inférence de type pour garder votre code concis et lisible.
Gardez les modèles de sérialisation bien documentés
Documentez soigneusement vos modèles de données :
- Utilisez des commentaires pour décrire le but de chaque propriété, surtout si le nom sous la forme sérialisée ne reflète pas clairement son utilisation.
- Documentez toute logique de sérialisation personnalisée ou pourquoi certains champs peuvent être marqués comme transitoires.
Cette pratique est particulièrement importante pour les équipes et pour gérer des projets à long terme où d'autres pourraient avoir besoin de comprendre le raisonnement qui sous-tend vos choix de conception de sérialisation.
Gérer les exceptions avec élégance
La sérialisation peut échouer pour de nombreuses raisons. Il est crucial de gérer ces scénarios avec élégance :
- Utilisez les blocs try-catch de Kotlin pour gérer les exceptions levées lors des processus de sérialisation ou de désérialisation.
- Fournissez des messages d'erreur clairs pour faciliter le débogage et informer les utilisateurs de ce qui n'a pas fonctionné.
- Envisagez des mécanismes de secours ou des valeurs par défaut si les erreurs de sérialisation peuvent être résolues de manière non critique.
Tirez parti des sérialiseurs génériques et personnalisés lorsque cela est nécessaire
Même si la sérialisation Kotlin gère de nombreux cas directement, vous aurez parfois besoin de plus de contrôle :
- Pour les classes génériques, utilisez des sérialiseurs de contexte pour fournir à Kotlin Serialization les informations dont il a besoin pour sérialiser ces structures.
- Lorsque vous traitez un type qui n'a pas de représentation sérialisée simple, ou lors de l'interface avec des systèmes externes avec des exigences uniques, vous devrez peut-être implémenter un sérialiseur personnalisé.
Les sérialiseurs personnalisés peuvent vous donner un contrôle précis sur le processus, mais ne doivent être utilisés que lorsque cela est nécessaire car ils peuvent compliquer votre base de code.
Restez à jour avec les dernières versions
Comme toute bibliothèque active, la sérialisation Kotlin est constamment améliorée :
- Mettez régulièrement à jour vos dépendances pour profiter des optimisations, des nouvelles fonctionnalités et des corrections de bugs importants.
- Observez les modifications dans les notes de version pour ajuster votre code en fonction des modifications importantes ou des dépréciations.
Optimiser la configuration du plugin du compilateur
Le plugin Kotlin Serialization propose plusieurs options de configuration :
- Ajustez ces paramètres dans le fichier
build.gradle de votre module pour adapter le comportement du plugin aux besoins de votre projet.
En suivant ces bonnes pratiques, vous vous assurerez que votre utilisation de la sérialisation Kotlin est efficace et optimisée pour le développement futur. Lorsque ces pratiques sont appliquées au sein d'une plate no-code comme AppMaster, vous pouvez améliorer encore la productivité et exploiter tout le potentiel de Kotlin en synchronisation avec les puissantes fonctionnalités de la plate-forme pour le développement d'applications.
Intégration de la sérialisation Kotlin avec AppMaster
L'intégration transparente de technologies sophistiquées est essentielle à l'évolution du développement de logiciels modernes. La sérialisation Kotlin, étant une boîte à outils puissante pour le traitement des données, s'intègre exceptionnellement bien avec les plates-formes conçues pour accélérer le processus de développement, telles que AppMaster. Cette relation synergique sous-tend la nature dynamique des applications centrées sur les données.
Au cœur d' AppMaster, une plate no-code qui génère du code source réel pour les applications backend, Web et mobiles, se trouve le besoin d'une sérialisation efficace des données. En raison de sa concision et de son interopérabilité, Kotlin est un choix privilégié pour le développement back-end dans de nombreux scénarios, et pour l'échange de données au sein AppMaster, la sérialisation Kotlin est un outil indispensable.
La sérialisation est un aspect crucial des générateurs backend d' AppMaster qui utilisent Go , et de la création d'applications mobiles qui s'appuient sur Kotlin et Swift . Alors que le backend utilise principalement Go, le rôle de Kotlin vient jouer lors de la liaison des applications mobiles avec divers services backend. Ici, la sérialisation Kotlin simplifie la conversion des objets Kotlin en chaînes au format JSON, garantissant ainsi une gestion et un échange fluides des données entre l'application mobile et les services backend.
Lorsqu'un utilisateur conçoit un modèle de données ou configure une logique métier via AppMaster, la plateforme peut exploiter la sérialisation Kotlin pour endpoints mobiles. Le processus cyclique de sérialisation (conversion d'objets en JSON) et de désérialisation (retour de JSON en objets Kotlin) est souvent automatisé, ce qui améliore l'efficacité du développement et minimise les risques d'erreur humaine.
De plus, grâce à sa capacité à gérer des structures de données complexes, notamment des classes et des collections imbriquées, Kotlin Serialization complète parfaitement les capacités de modélisation de données d' AppMaster. Qu'il s'agisse d'une simple opération CRUD ou d'une transaction sophistiquée, les données structurées peuvent être facilement sérialisées et désérialisées, garantissant ainsi le maintien de l'intégrité des données tout au long du cycle de vie de l'application.
L'intégration avec la plate-forme AppMaster permet également d'exploiter la sérialisation Kotlin dans un système de livraison continue et transparent. À mesure que les applications évoluent avec des exigences changeantes, AppMaster régénère les applications à partir de zéro, un processus dans lequel la sérialisation Kotlin peut relier des objets et des schémas de données sans accumuler de dette technique .
Concernant les capacités multiplateformes, Kotlin Serialization constitue un allié louable. Alors AppMaster favorise le développement rapide d'applications multiplateformes, la sérialisation Kotlin offre la flexibilité et la fiabilité nécessaires pour gérer les données de manière cohérente sur ces plateformes. Cela rend le cheminement depuis la conceptualisation jusqu'au déploiement beaucoup moins compliqué et plus conforme aux protocoles de développement modernes qui favorisent les stratégies multiplateformes.
L'intégration de la sérialisation Kotlin dans l'écosystème d' AppMaster renforce l'engagement de la plateforme à fournir un environnement dans lequel même ceux qui n'ont pas d'expérience en codage traditionnel peuvent créer des applications performantes, évolutives et complexes. Cela témoigne de la puissance de la combinaison des capacités des techniques de sérialisation modernes avec des plates-formes de développement innovantes pour véritablement démocratiser l'expérience de création d'applications.






