Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Entdecken Sie die Besonderheiten von SQL-Datenstrukturen, einschließlich des Verständnisses von Datentypen, der Verwaltung von Einschränkungen und der Optimierung der Leistung mit Indizes.

Structured Query Language (SQL) ist die Grundlage moderner Datenbanken, und das Verständnis der Datenstrukturen in SQL ist für jeden Entwickler oder Administrator, der mit relationalen Datenbanken arbeitet, von entscheidender Bedeutung. Die Effizienz und Leistung einer Datenbank hängen davon ab, wie gut ihre Datenstrukturen gestaltet sind. In diesem Leitfaden betrachten wir einige der Schlüsselkonzepte im Zusammenhang mit SQL-Datenstrukturen, wie z. B. Datentypen, Primärschlüssel, Fremdschlüssel und Einschränkungen. Wenn Sie diese Konzepte beherrschen, sind Sie besser in der Lage, effiziente, skalierbare Datenbanken zur Unterstützung Ihrer Anwendungen zu erstellen und zu verwalten.
In SQL bestimmen Datentypen den Datentyp, der in einer Spalte gespeichert werden kann. Jede Spalte in einer Tabelle ist einem bestimmten Datentyp zugeordnet, was Konsistenz und Datenintegrität gewährleistet und zur Optimierung von Speicher und Leistung beiträgt. SQL bietet eine Vielzahl von Datentypen, um unterschiedlichen Anforderungen gerecht zu werden, von einfachen numerischen Werten und Textzeichenfolgen bis hin zu komplexeren Typen wie Datumsangaben und binären Objekten. Sehen wir uns einige der am häufigsten verwendeten Datentypen in SQL an:
Die Auswahl des richtigen Datentyps für jede Spalte ist entscheidend für die Gewährleistung der Datenintegrität und die Optimierung der Datenbankleistung. Die Verwendung ungeeigneter Datentypen kann zu Kürzungen, Rundungsfehlern und anderen Datenmanipulationsproblemen führen, die sich auf die Funktionalität Ihrer Anwendung auswirken können.
Eine der Kernfunktionen relationaler Datenbanken ist die Fähigkeit, Beziehungen zwischen Tabellen herzustellen. Dies wird durch Primärschlüssel, Fremdschlüssel, Einschränkungen und Regeln erreicht, die die referenzielle Integrität erzwingen und konsistente Beziehungen zwischen Tabellen gewährleisten. Schauen wir uns diese Konzepte genauer an:
Ein Primärschlüssel ist eine Spalte oder eine Reihe von Spalten, die jede Zeile in einer Tabelle eindeutig identifizieren. Primärschlüssel sind entscheidend für den Aufbau von Beziehungen zwischen Tabellen und die Gewährleistung der Datenkonsistenz. Es kann nur einen Primärschlüssel pro Tabelle geben und sein Wert darf nicht NULL sein. Im Folgenden finden Sie einige Best Practices, die Sie bei der Auswahl eines Primärschlüssels für Ihre Tabellen berücksichtigen sollten:
Ein Fremdschlüssel ist eine Spalte oder eine Reihe von Spalten in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist. Es wird verwendet, um Beziehungen zwischen Tabellen herzustellen und die referenzielle Integrität durchzusetzen. Die Tabelle mit dem Fremdschlüssel wird als „untergeordnete“ Tabelle bezeichnet, während die Tabelle mit dem Primärschlüssel als „übergeordnete“ Tabelle bezeichnet wird. Fremdschlüssel können NULL sein, was bedeutet, dass eine Zeile in der untergeordneten Tabelle keine entsprechende Zeile in der übergeordneten Tabelle benötigt. Wenn ein Fremdschlüssel jedoch nicht NULL ist, muss es in der übergeordneten Tabelle eine Zeile mit einem passenden Primärschlüsselwert geben.
Einschränkungen sind Regeln, die die Datenintegrität innerhalb einer relationalen Datenbank erzwingen. Sie geben Bedingungen an, die die Daten in einer Tabelle erfüllen müssen, und verhindern Vorgänge, die gegen diese Bedingungen verstoßen würden. SQL bietet verschiedene Arten von Einschränkungen, die auf Spalten und Tabellen angewendet werden können, um Datenstrukturen zu verwalten, darunter:
Die ordnungsgemäße Definition und Verwaltung von Einschränkungen ist für die Aufrechterhaltung der Integrität, Konsistenz und Leistung Ihrer Datenbank von entscheidender Bedeutung. Sie verhindern Fehler und Inkonsistenzen bei der Datenmanipulation, die sich negativ auf die Funktionalität und Benutzererfahrung Ihrer Anwendung auswirken könnten.
In SQL sind Tabellen die Hauptbestandteile einer Datenbank und speichern Daten in einem strukturierten Format. Beim Erstellen von Tabellen ist es wichtig, Datenstrukturen zu definieren, die den Anforderungen Ihrer Anwendung entsprechen. Hier besprechen wir, wie man Tabellen erstellt und ihre Datenstrukturen in SQL definiert.
Um eine Tabelle in SQL zu erstellen, verwenden Sie die CREATE TABLE Anweisung. Mit dieser Anweisung können Sie den Namen, die Spalten und die jeweiligen Datentypen der Tabelle angeben sowie Einschränkungen hinzufügen, um die Datenintegrität aufrechtzuerhalten.
Hier ist ein Beispiel für die Erstellung einer einfachen Tabelle:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100) UNIQUE, hire_date DATE );
In diesem Beispiel erstellen wir eine employees mit den folgenden Spalten: employee_id , first_name , last_name , email und hire_date . Wir legen außerdem eine PRIMARY KEY Einschränkung für die Spalte employee_id und eine UNIQUE Einschränkung für die email Spalte fest.
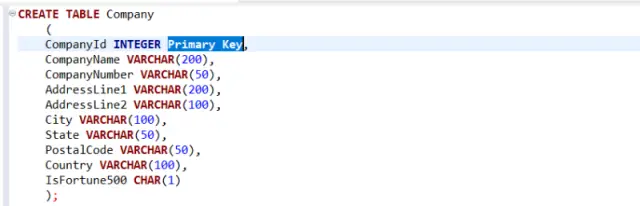
Bildquelle: All Things SQL
Nachdem Sie eine Tabelle erstellt haben, müssen Sie möglicherweise deren Struktur ändern, um sie an die sich ändernden Anforderungen Ihrer Anwendung anzupassen. SQL stellt die ALTER TABLE Anweisung bereit, mit der Sie Spalten zu Ihren vorhandenen Tabellen hinzufügen, ändern oder löschen sowie Einschränkungen hinzufügen, aktualisieren oder löschen können.
Hier sind einige Beispiele, wie Sie eine Tabelle ändern können:
-- Add a column ALTER TABLE employees ADD COLUMN job_title VARCHAR(50); -- Modify a column ALTER TABLE employees ALTER COLUMN job_title SET DATA TYPE VARCHAR(100); -- Drop a column ALTER TABLE employees DROP COLUMN job_title; -- Add a foreign key constraint ALTER TABLE employees ADD CONSTRAINT fk_department_id FOREIGN KEY (department_id) REFERENCES departments (department_id);
Diese Beispiele veranschaulichen, wie Sie mit der ALTER TABLE Anweisung die employees ändern. Die Befehle ALTER , ADD und UPDATE ändern verschiedene Aspekte der Tabellenstruktur, wie z. B. den Spaltendatentyp und das Hinzufügen von Einschränkungen.
Indizes sind Datenbankobjekte, die dazu beitragen, den Datenabrufprozess zu beschleunigen und so die Datenbankleistung zu verbessern. Beim Erstellen eines Index speichert die Datenbank-Engine eine Kopie der indizierten Spalten und verwaltet sie in sortierter Reihenfolge, was schnellere Suchvorgänge und eine effizientere Abfrageausführung ermöglicht. Bedenken Sie, dass Indizes auch einen gewissen Mehraufwand bei Datenänderungsvorgängen wie Einfügungen, Aktualisierungen und Löschungen verursachen können, die möglicherweise eine Neuorganisation der Indizes erfordern.
Um einen Index zu erstellen, verwenden Sie die CREATE INDEX Anweisung. Für diese Anweisung müssen Sie den Namen des Index, die Tabelle, mit der der Index verknüpft werden soll, und die zu indizierenden Spalten angeben.
Hier ist ein Beispiel für die Erstellung eines Index:
CREATE INDEX idx_last_name ON employees (last_name);
In diesem Beispiel erstellen wir einen Index mit dem Namen idx_last_name für die employees und wählen die Spalte last_name aus, die indiziert werden soll.
Indizes können in zwei Haupttypen eingeteilt werden: Clustered-Indizes und Nicht-Clustered-Indizes. Ein Clustered-Index bestimmt die physische Reihenfolge der Daten innerhalb einer Tabelle und kann nur einen pro Tabelle haben. Im Gegensatz dazu speichern nicht gruppierte Indizes eine separate Kopie der Daten, sortiert nach den indizierten Spalten, sodass mehrere nicht gruppierte Indizes pro Tabelle möglich sind.
Nicht gruppierte Indizes bieten im Allgemeinen bessere Leistungsvorteile für leseintensive Anwendungen, während gruppierte Indizes tendenziell Tabellen mit häufigen Aktualisierungen und Löschvorgängen sowie Bereichsabfragen begünstigen.
Bei der Auswahl der richtigen Indizes für Ihre Datenbank müssen mehrere Faktoren sorgfältig berücksichtigt werden, darunter Abfragemuster, Datenverteilung und Tabellenstruktur. Bei der Bestimmung der geeigneten Indizes sind folgende Richtlinien zu beachten:
WHERE Klauseln verwendet werden.WHERE Klausel mehrere Spalten verwenden.Der Aufbau und die Verwaltung von Datenbanken können zeitaufwändig und komplex sein, insbesondere für Personen ohne umfassende SQL-Kenntnisse. Hier kommt Ihnen die no-code Plattform AppMaster zu Hilfe. Mit AppMaster können Sie Datenmodelle visuell erstellen, Geschäftsprozesse entwerfen und REST-API- und WSS- endpoints generieren, ohne eine einzige Codezeile schreiben zu müssen.
Die Plattform von AppMaster bietet viele Vorteile, darunter:

Mit der AppMaster No-Code- Plattform können Sie Web-, Mobil- und Backend-Anwendungen bis zu 10-mal schneller und 3-mal kostengünstiger erstellen als mit herkömmlichen Codierungsmethoden. Bringen Sie Ihr Datenbankmanagement und Ihre Anwendungsentwicklung auf die nächste Ebene, indem Sie die leistungsstarke no-code Plattform von AppMaster erkunden.
In diesem umfassenden Leitfaden haben wir die verschiedenen Aspekte von Datenstrukturen in SQL untersucht, einschließlich Datentypen, Primär- und Fremdschlüssel, Einschränkungen, Tabellen und Indizierung. Wenn Sie diese Konzepte beherrschen, können Sie effiziente und skalierbare Datenbanken erstellen, die komplexe Anwendungen problemlos verarbeiten können.
Denken Sie bei der Arbeit mit SQL-Datenbanken daran, die Bedeutung der Datentypen für die Optimierung der Speicherung und die Gewährleistung der Datenintegrität zu berücksichtigen. Stellen Sie außerdem Beziehungen zwischen Tabellen über Primär- und Fremdschlüssel her und erzwingen Sie Datenintegritätsregeln mithilfe von Einschränkungen. Verbessern Sie schließlich die Leistung Ihrer Datenbank mithilfe von Indizes, um einen schnelleren Datenabruf zu ermöglichen und die Ausführungspläne für Abfragen zu optimieren.
Angenommen, Sie suchen nach einer Möglichkeit, Anwendungen zu erstellen, ohne sich mit den Einzelheiten der SQL-Datenstrukturen auseinanderzusetzen. In diesem Fall bietet AppMaster eine leistungsstarke no-code Plattform, mit der Sie Datenmodelle sowie Web- und Mobilanwendungen visuell erstellen können. Mit AppMaster können Sie technische Schulden beseitigen und von einer verbesserten Projektskalierbarkeit profitieren. Probieren Sie AppMaster aus und erleben Sie die Einfachheit und Effizienz der no-code App-Entwicklung. Mit einem soliden Verständnis der SQL-Datenstrukturen und der Hilfe von Tools wie AppMaster, you're now better equipped to create, manage, and optimize databases for your projects.
Zu den Hauptmerkmalen von Datenstrukturen in SQL gehören Datentypen, Primär- und Fremdschlüssel, Einschränkungen, Tabellen und Indizes.
Datentypen in SQL sind wichtig, da sie die Art der Daten definieren, die in einer Spalte gespeichert werden können, die Datenintegrität sicherstellen und zur Optimierung von Speicher und Leistung beitragen.
Primärschlüssel und Fremdschlüssel spielen in SQL-Datenstrukturen eine entscheidende Rolle, indem sie Beziehungen zwischen Tabellen herstellen, referenzielle Integrität erzwingen und für jede Zeile in einer Tabelle eine eindeutige Kennung bereitstellen.
Einschränkungen helfen bei der Verwaltung von Datenstrukturen in SQL, indem sie Datenintegritätsregeln durchsetzen, sicherstellen, dass die Daten in der Datenbank bestimmte Bedingungen erfüllen, und Datenmanipulationsfehler verhindern.
Indizes in SQL können die Datenbankleistung verbessern, indem sie einen schnelleren Datenabruf ermöglichen, die Datenmenge reduzieren, die von der Festplatte gelesen werden muss, und den Abfrageausführungsplan optimieren.
Die No-Code-Plattform von AppMaster bietet Vorteile wie visuelle Datenmodelle, Geschäftsprozessdesigner, REST-API und WSS-Endpunkte, schnelle Anwendungsentwicklung, Beseitigung technischer Schulden und verbesserte Skalierbarkeit für die Datenbankverwaltung.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


