সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
এসকিউএল ডেটা স্ট্রাকচারের ইনস এবং আউটগুলি আবিষ্কার করুন, যার মধ্যে ডেটার ধরন বোঝা, সীমাবদ্ধতাগুলি পরিচালনা করা এবং সূচীগুলির সাথে পারফরম্যান্স অপ্টিমাইজ করা৷

স্ট্রাকচার্ড কোয়েরি ল্যাঙ্গুয়েজ (SQL) হল আধুনিক ডাটাবেসের ভিত্তি, এবং রিলেশনাল ডাটাবেসের সাথে কাজ করা যেকোনো ডেভেলপার বা অ্যাডমিনিস্ট্রেটরের জন্য SQL-এ ডেটা স্ট্রাকচার বোঝা অপরিহার্য। একটি ডাটাবেসের দক্ষতা এবং কর্মক্ষমতা নির্ভর করে তার ডেটা স্ট্রাকচার কতটা ভালোভাবে ডিজাইন করা হয়েছে তার উপর। এই নির্দেশিকায়, আমরা এসকিউএল ডেটা স্ট্রাকচারের সাথে সম্পর্কিত কিছু মূল ধারণা দেখব, যেমন ডেটা প্রকার, প্রাথমিক কী, বিদেশী কী এবং সীমাবদ্ধতা। এই ধারণাগুলি আয়ত্ত করার মাধ্যমে, আপনি আপনার অ্যাপ্লিকেশনগুলিকে সমর্থন করার জন্য দক্ষ, মাপযোগ্য ডেটাবেস তৈরি এবং বজায় রাখতে আরও ভালভাবে সজ্জিত হবেন।
এসকিউএল-এ, ডেটা টাইপগুলি ডেটা টাইপ নির্ধারণ করে যা একটি কলামে সংরক্ষণ করা যেতে পারে। একটি টেবিলের প্রতিটি কলাম একটি নির্দিষ্ট ডেটা টাইপের সাথে যুক্ত, যা ধারাবাহিকতা এবং ডেটা অখণ্ডতা নিশ্চিত করে এবং স্টোরেজ এবং কর্মক্ষমতা অপ্টিমাইজ করতে সহায়তা করে। এসকিউএল বিভিন্ন প্রয়োজন মেটাতে বিভিন্ন ধরনের ডেটা প্রদান করে, সাধারণ সংখ্যাসূচক মান এবং টেক্সট স্ট্রিং থেকে শুরু করে আরও জটিল ধরনের যেমন তারিখ এবং বাইনারি অবজেক্ট। এসকিউএল-এ সবচেয়ে বেশি ব্যবহৃত কিছু ডেটা টাইপ অন্বেষণ করা যাক:
প্রতিটি কলামের জন্য সঠিক ডেটা টাইপ নির্বাচন করা ডাটা অখণ্ডতা নিশ্চিত করার জন্য এবং ডাটাবেসের কর্মক্ষমতা অপ্টিমাইজ করার জন্য অত্যন্ত গুরুত্বপূর্ণ। অনুপযুক্ত ডেটা টাইপ ব্যবহার করলে ছেদন, রাউন্ডিং ত্রুটি এবং অন্যান্য ডেটা ম্যানিপুলেশন সমস্যা হতে পারে যা আপনার অ্যাপ্লিকেশনের কার্যকারিতাকে প্রভাবিত করতে পারে।
রিলেশনাল ডাটাবেসের মূল বৈশিষ্ট্যগুলির মধ্যে একটি হল টেবিলের মধ্যে সম্পর্ক স্থাপন করার ক্ষমতা। এটি প্রাথমিক কী, বিদেশী কী, সীমাবদ্ধতা এবং নিয়মগুলির মাধ্যমে অর্জন করা হয় যা রেফারেন্সিয়াল অখণ্ডতা প্রয়োগ করে, টেবিলের মধ্যে সামঞ্জস্যপূর্ণ সম্পর্ক নিশ্চিত করে। আসুন এই ধারণাগুলির মধ্যে অনুসন্ধান করা যাক:
একটি প্রাথমিক কী হল একটি কলাম বা কলামের একটি সেট যা একটি টেবিলের প্রতিটি সারিকে স্বতন্ত্রভাবে চিহ্নিত করে। প্রাথমিক কীগুলি টেবিলের মধ্যে সম্পর্ক স্থাপন এবং ডেটা সামঞ্জস্য নিশ্চিত করতে গুরুত্বপূর্ণ। প্রতি টেবিলে শুধুমাত্র একটি প্রাথমিক কী থাকতে পারে এবং এর মান NULL হতে পারে না। আপনার টেবিলের জন্য একটি প্রাথমিক কী নির্বাচন করার সময় বিবেচনা করার জন্য নিম্নলিখিত কিছু সেরা অনুশীলনগুলি রয়েছে:
একটি বিদেশী কী হল একটি কলাম বা একটি টেবিলের কলামের একটি সেট যা অন্য টেবিলের প্রাথমিক কীকে নির্দেশ করে। এটি টেবিলের মধ্যে সম্পর্ক স্থাপন এবং রেফারেন্সিয়াল অখণ্ডতা প্রয়োগ করতে ব্যবহৃত হয়। বিদেশী কী সহ টেবিলটিকে "শিশু" টেবিল বলা হয়, যখন প্রাথমিক কী সহ টেবিলটিকে "প্যারেন্ট" টেবিল বলা হয়। বিদেশী কীগুলি NULL হতে পারে, যার অর্থ হল চাইল্ড টেবিলের একটি সারির জন্য প্যারেন্ট টেবিলে একটি সংশ্লিষ্ট সারি প্রয়োজন নেই৷ কিন্তু যদি একটি বিদেশী কী NULL না হয়, তাহলে প্যারেন্ট টেবিলে একটি সারি থাকতে হবে যার সাথে একটি মিলে যাওয়া প্রাথমিক কী মান থাকবে।
সীমাবদ্ধতা এমন নিয়ম যা একটি রিলেশনাল ডাটাবেসের মধ্যে ডেটা অখণ্ডতা প্রয়োগ করে। তারা শর্তগুলি নির্দিষ্ট করে যেগুলি একটি টেবিলের ডেটা অবশ্যই পূরণ করবে এবং এই শর্তগুলি লঙ্ঘন করবে এমন ক্রিয়াকলাপগুলিকে প্রতিরোধ করবে৷ এসকিউএল বিভিন্ন ধরনের সীমাবদ্ধতা প্রদান করে যা ডেটা স্ট্রাকচার পরিচালনা করতে কলাম এবং টেবিলে প্রয়োগ করা যেতে পারে, যার মধ্যে রয়েছে:
আপনার ডাটাবেসের অখণ্ডতা, ধারাবাহিকতা এবং কর্মক্ষমতা বজায় রাখার জন্য সীমাবদ্ধতাগুলিকে সঠিকভাবে সংজ্ঞায়িত করা এবং পরিচালনা করা অপরিহার্য। তারা ডেটা ম্যানিপুলেশন ত্রুটি এবং অসঙ্গতিগুলি প্রতিরোধ করে যা আপনার অ্যাপ্লিকেশনের কার্যকারিতা এবং ব্যবহারকারীর অভিজ্ঞতাকে নেতিবাচকভাবে প্রভাবিত করতে পারে।
এসকিউএল-এ, টেবিলগুলি একটি ডাটাবেসের প্রধান উপাদান এবং তারা একটি কাঠামোগত বিন্যাসে ডেটা সংরক্ষণ করে। টেবিল তৈরি করার সময়, আপনার অ্যাপ্লিকেশনের প্রয়োজনীয়তার সাথে মেলে ডেটা স্ট্রাকচার সংজ্ঞায়িত করা অপরিহার্য। এখানে, আমরা আলোচনা করব কিভাবে টেবিল তৈরি করা যায় এবং এসকিউএল-এ তাদের ডেটা স্ট্রাকচার সংজ্ঞায়িত করা যায়।
SQL-এ একটি টেবিল তৈরি করতে, আপনি CREATE TABLE স্টেটমেন্ট ব্যবহার করবেন। এই বিবৃতিটি আপনাকে টেবিলের নাম, কলাম এবং তাদের নিজ নিজ ডেটা প্রকার উল্লেখ করার পাশাপাশি ডেটা অখণ্ডতা বজায় রাখার জন্য সীমাবদ্ধতা যোগ করার অনুমতি দেয়।
এখানে একটি সাধারণ টেবিল তৈরির একটি উদাহরণ রয়েছে:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100) UNIQUE, hire_date DATE );
এই উদাহরণে, আমরা নিম্নলিখিত কলামগুলির সাথে একটি employees টেবিল তৈরি করি: employee_id , first_name , last_name , email , এবং hire_date । employee_id কলামে একটি PRIMARY KEY সীমাবদ্ধতা এবং email কলামের জন্য একটি UNIQUE সীমাবদ্ধতাও উল্লেখ করি।
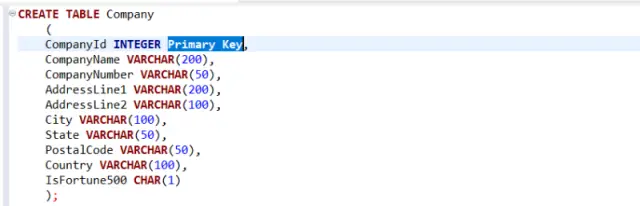
ইমেজ সোর্স: অল থিংস এসকিউএল
একটি টেবিল তৈরি করার পরে, আপনার অ্যাপ্লিকেশনের ক্রমবর্ধমান প্রয়োজনীয়তার সাথে মেলে তার গঠন পরিবর্তন করতে হতে পারে। SQL ALTER TABLE স্টেটমেন্ট প্রদান করে, যা আপনাকে আপনার বিদ্যমান টেবিলে কলাম যোগ, পরিবর্তন বা ড্রপ করার পাশাপাশি সীমাবদ্ধতা যোগ, আপডেট বা ড্রপ করতে দেয়।
এখানে একটি টেবিল পরিবর্তন করার কয়েকটি উদাহরণ রয়েছে:
-- Add a column ALTER TABLE employees ADD COLUMN job_title VARCHAR(50); -- Modify a column ALTER TABLE employees ALTER COLUMN job_title SET DATA TYPE VARCHAR(100); -- Drop a column ALTER TABLE employees DROP COLUMN job_title; -- Add a foreign key constraint ALTER TABLE employees ADD CONSTRAINT fk_department_id FOREIGN KEY (department_id) REFERENCES departments (department_id);
এই উদাহরণগুলি দেখায় কিভাবে employees টেবিল পরিবর্তন করতে ALTER TABLE স্টেটমেন্ট ব্যবহার করতে হয়। ALTER , ADD , এবং UPDATE কমান্ডগুলি টেবিলের কাঠামোর বিভিন্ন দিক পরিবর্তন করে, যেমন কলাম ডেটা টাইপ এবং সীমাবদ্ধতা যোগ করা।
সূচীগুলি হল ডাটাবেস বস্তু যা ডেটা পুনরুদ্ধার প্রক্রিয়াকে গতিশীল করতে সাহায্য করে, এইভাবে ডাটাবেসের কর্মক্ষমতা বৃদ্ধি করে। একটি সূচক তৈরি করার সময়, ডাটাবেস ইঞ্জিন সূচীকৃত কলামগুলির একটি অনুলিপি সংরক্ষণ করবে এবং এটিকে একটি সাজানো ক্রমে বজায় রাখবে, যাতে দ্রুত অনুসন্ধান এবং আরও দক্ষ ক্যোয়ারী সম্পাদনের অনুমতি দেওয়া হয়। মনে রাখবেন যে সূচীগুলি ডেটা পরিবর্তনের ক্রিয়াকলাপগুলির বিষয়ে কিছু ওভারহেডও প্রবর্তন করতে পারে, যেমন সন্নিবেশ, আপডেট এবং মুছে ফেলা, যার জন্য সূচীগুলি পুনর্গঠনের প্রয়োজন হতে পারে।
একটি সূচক তৈরি করতে, আপনি CREATE INDEX ব্যবহার করবেন। এই বিবৃতিটির জন্য আপনাকে সূচির নাম উল্লেখ করতে হবে, আপনি যে টেবিলের সাথে সূচীটি যুক্ত করতে চান এবং কলাম(গুলি) সূচিবদ্ধ করতে চান।
এখানে একটি সূচক তৈরির একটি উদাহরণ:
CREATE INDEX idx_last_name ON employees (last_name);
এই উদাহরণে, আমরা employees টেবিলে idx_last_name নামে একটি সূচী তৈরি করি এবং সূচীকরণের জন্য last_name কলামটি নির্বাচন করি।
সূচীগুলি দুটি প্রধান প্রকারে শ্রেণীবদ্ধ করা যেতে পারে: ক্লাস্টারযুক্ত সূচক এবং অ-ক্লাস্টার সূচক। একটি গুচ্ছ সূচক একটি টেবিলের মধ্যে ডেটার প্রকৃত ক্রম নির্ধারণ করে এবং প্রতি টেবিলে শুধুমাত্র একটি থাকতে পারে। বিপরীতে, নন-ক্লাস্টারড ইনডেক্সগুলি সূচীকৃত কলাম দ্বারা বাছাই করা ডেটার একটি পৃথক অনুলিপি সংরক্ষণ করে, প্রতি টেবিলে একাধিক নন-ক্লাস্টারড ইনডেক্সের অনুমতি দেয়।
নন-ক্লাস্টারড ইনডেক্সগুলি সাধারণত রিড-হেভি অ্যাপ্লিকেশনগুলির জন্য আরও ভাল পারফরম্যান্স সুবিধা প্রদান করে, যখন ক্লাস্টারযুক্ত সূচীগুলি ঘন ঘন আপডেট এবং মুছে ফেলা এবং পরিসরের প্রশ্নগুলির সাথে টেবিলগুলিকে উপকৃত করে।
আপনার ডাটাবেসের জন্য সঠিক সূচী নির্বাচন করার জন্য ক্যোয়ারী প্যাটার্ন, ডাটা ডিস্ট্রিবিউশন এবং টেবিল স্ট্রাকচার সহ বেশ কয়েকটি বিষয়ের সতর্কতা অবলম্বন করা প্রয়োজন। উপযুক্ত সূচক নির্ধারণ করার সময় অনুসরণ করতে হবে এমন কিছু নির্দেশিকা হল:
WHERE ধারাগুলিতে ব্যবহৃত হয়৷WHERE ক্লজে একাধিক কলাম ব্যবহার করে এমন প্রশ্নের জন্য যৌগিক সূচী বিবেচনা করুন।ডেটাবেস তৈরি করা এবং পরিচালনা করা সময়সাপেক্ষ এবং জটিল হতে পারে, বিশেষ করে তাদের জন্য যাদের বিস্তৃত SQL জ্ঞান নেই। এখানেই অ্যাপমাস্টার no-code প্ল্যাটফর্ম আপনার সাহায্যে আসে। AppMaster এর মাধ্যমে, আপনি দৃশ্যত ডেটা মডেল তৈরি করতে পারেন, ব্যবসায়িক প্রক্রিয়াগুলি ডিজাইন করতে পারেন এবং কোডের একটি লাইন না লিখে REST API এবং WSS endpoints তৈরি করতে পারেন৷
AppMaster প্ল্যাটফর্ম অনেক সুবিধা প্রদান করে, যার মধ্যে রয়েছে:

AppMaster নো-কোড প্ল্যাটফর্ম ব্যবহার করে, আপনি প্রথাগত কোডিং পদ্ধতির তুলনায় 10x দ্রুত এবং 3x বেশি খরচে ওয়েব, মোবাইল এবং ব্যাকএন্ড অ্যাপ্লিকেশন তৈরি করতে পারেন। AppMaster শক্তিশালী no-code প্ল্যাটফর্ম অন্বেষণ করে আপনার ডাটাবেস ব্যবস্থাপনা এবং অ্যাপ্লিকেশন বিকাশকে পরবর্তী স্তরে নিয়ে যান।
এই বিস্তৃত নির্দেশিকাটিতে, আমরা SQL-এ ডেটা স্ট্রাকচারের বিভিন্ন দিক অনুসন্ধান করেছি, যার মধ্যে ডেটার ধরন, প্রাথমিক এবং বিদেশী কী, সীমাবদ্ধতা, টেবিল এবং ইন্ডেক্সিং রয়েছে। এই ধারণাগুলি আয়ত্ত করা আপনাকে দক্ষ এবং মাপযোগ্য ডেটাবেস তৈরি করতে সক্ষম করবে যা সহজেই জটিল অ্যাপ্লিকেশনগুলি পরিচালনা করতে পারে।
আপনি SQL ডাটাবেসের সাথে কাজ করার সময়, স্টোরেজ অপ্টিমাইজ করার জন্য এবং ডেটা অখণ্ডতা নিশ্চিত করার জন্য ডেটা প্রকারের গুরুত্ব বিবেচনা করতে ভুলবেন না। তদ্ব্যতীত, প্রাথমিক এবং বিদেশী কীগুলির মাধ্যমে টেবিলের মধ্যে সম্পর্ক স্থাপন করুন এবং সীমাবদ্ধতা ব্যবহার করে ডেটা অখণ্ডতার নিয়মগুলি প্রয়োগ করুন। অবশেষে, দ্রুত ডেটা পুনরুদ্ধার সক্ষম করতে এবং ক্যোয়ারী এক্সিকিউশন প্ল্যান অপ্টিমাইজ করতে সূচী ব্যবহার করে আপনার ডাটাবেসের কর্মক্ষমতা বাড়ান।
ধরুন আপনি এসকিউএল ডাটা স্ট্রাকচারের নিট্টি-কষ্টে না গিয়ে অ্যাপ্লিকেশন তৈরি করার উপায় খুঁজছেন। সেই ক্ষেত্রে, AppMaster একটি শক্তিশালী no-code প্ল্যাটফর্ম অফার করে যা আপনাকে দৃশ্যত ডেটা মডেল এবং ওয়েব এবং মোবাইল অ্যাপ্লিকেশন তৈরি করতে দেয়। AppMaster এর মাধ্যমে, আপনি প্রযুক্তিগত ঋণ দূর করতে পারেন এবং উন্নত প্রকল্পের মাপযোগ্যতা উপভোগ করতে পারেন। AppMaster চেষ্টা করে দেখুন এবং no-code অ্যাপ ডেভেলপমেন্টের সরলতা এবং দক্ষতার অভিজ্ঞতা নিন। SQL ডেটা স্ট্রাকচারের দৃঢ় বোধগম্যতা এবং AppMaster, you're now better equipped to create, manage, and optimize databases for your projects.
এসকিউএল-এ ডেটা স্ট্রাকচারের কিছু প্রধান বৈশিষ্ট্যের মধ্যে রয়েছে ডেটা টাইপ, প্রাথমিক এবং বিদেশী কী, সীমাবদ্ধতা, টেবিল এবং সূচী।
এসকিউএল-এ ডেটা প্রকারগুলি গুরুত্বপূর্ণ কারণ তারা একটি কলামে সংরক্ষণ করা যেতে পারে এমন ডেটার ধরন নির্ধারণ করে, ডেটা অখণ্ডতা নিশ্চিত করে এবং সঞ্চয়স্থান এবং কর্মক্ষমতা অপ্টিমাইজ করতে সহায়তা করে।
প্রাথমিক কী এবং বিদেশী কীগুলি টেবিলের মধ্যে সম্পর্ক স্থাপন করে, রেফারেন্সিয়াল অখণ্ডতা প্রয়োগ করে এবং একটি টেবিলের প্রতিটি সারির জন্য একটি অনন্য শনাক্তকারী প্রদান করে SQL ডেটা স্ট্রাকচারে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে।
সীমাবদ্ধতাগুলি ডেটা অখণ্ডতার নিয়মগুলি প্রয়োগ করে, ডেটাবেসের ডেটা নির্দিষ্ট শর্তগুলির সাথে সম্মত হয় তা নিশ্চিত করে এবং ডেটা ম্যানিপুলেশন ত্রুটিগুলি প্রতিরোধ করে এসকিউএল-এ ডেটা কাঠামো পরিচালনা করতে সহায়তা করে।
এসকিউএল-এর সূচীগুলি দ্রুত ডেটা পুনরুদ্ধারের অনুমতি দিয়ে, ডিস্ক থেকে পড়তে হবে এমন ডেটার পরিমাণ হ্রাস করে এবং ক্যোয়ারী এক্সিকিউশন প্ল্যানকে অপ্টিমাইজ করে ডাটাবেসের কর্মক্ষমতা বাড়াতে পারে।
AppMaster নো-কোড প্ল্যাটফর্ম ভিজ্যুয়াল ডেটা মডেল, ব্যবসায়িক প্রক্রিয়া ডিজাইনার, REST API এবং WSS এন্ডপয়েন্ট, দ্রুত অ্যাপ্লিকেশন বিকাশ, প্রযুক্তিগত ঋণ দূরীকরণ এবং ডাটাবেস পরিচালনার জন্য উন্নত স্কেলেবিলিটির মতো সুবিধা প্রদান করে।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


