उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
डेटा प्रकारों को समझने, बाधाओं को प्रबंधित करने और इंडेक्स के साथ प्रदर्शन को अनुकूलित करने सहित SQL डेटा संरचनाओं के अंदर और बाहर की खोज करें।

संरचित क्वेरी भाषा (एसक्यूएल) आधुनिक डेटाबेस की नींव है, और रिलेशनल डेटाबेस के साथ काम करने वाले किसी भी डेवलपर या प्रशासक के लिए एसक्यूएल में डेटा संरचनाओं को समझना आवश्यक है। किसी डेटाबेस की दक्षता और प्रदर्शन इस बात पर निर्भर करता है कि उसकी डेटा संरचनाएँ कितनी अच्छी तरह डिज़ाइन की गई हैं। इस गाइड में, हम SQL डेटा संरचनाओं से संबंधित कुछ प्रमुख अवधारणाओं को देखेंगे, जैसे डेटा प्रकार, प्राथमिक कुंजी, विदेशी कुंजी और बाधाएं। इन अवधारणाओं में महारत हासिल करके, आप अपने अनुप्रयोगों का समर्थन करने के लिए कुशल, स्केलेबल डेटाबेस बनाने और बनाए रखने के लिए बेहतर ढंग से सुसज्जित होंगे।
SQL में, डेटा प्रकार उस डेटा प्रकार को निर्धारित करते हैं जिसे एक कॉलम में संग्रहीत किया जा सकता है। तालिका में प्रत्येक कॉलम एक विशिष्ट डेटा प्रकार से जुड़ा होता है, जो स्थिरता और डेटा अखंडता सुनिश्चित करता है और भंडारण और प्रदर्शन को अनुकूलित करने में मदद करता है। SQL विभिन्न आवश्यकताओं को पूरा करने के लिए विभिन्न प्रकार के डेटा प्रकार प्रदान करता है, सरल संख्यात्मक मान और टेक्स्ट स्ट्रिंग से लेकर अधिक जटिल प्रकार जैसे दिनांक और बाइनरी ऑब्जेक्ट तक। आइए SQL में सबसे अधिक उपयोग किए जाने वाले कुछ डेटा प्रकारों का पता लगाएं:
डेटा अखंडता सुनिश्चित करने और डेटाबेस प्रदर्शन को अनुकूलित करने के लिए प्रत्येक कॉलम के लिए सही डेटा प्रकार चुनना महत्वपूर्ण है। अनुचित डेटा प्रकारों का उपयोग करने से ट्रंकेशन, राउंडिंग त्रुटियां और अन्य डेटा हेरफेर समस्याएं हो सकती हैं जो आपके एप्लिकेशन की कार्यक्षमता को प्रभावित कर सकती हैं।
रिलेशनल डेटाबेस की मुख्य विशेषताओं में से एक तालिकाओं के बीच संबंध स्थापित करने की क्षमता है। यह प्राथमिक कुंजी, विदेशी कुंजी, बाधाओं और नियमों के माध्यम से प्राप्त किया जाता है जो संदर्भात्मक अखंडता को लागू करते हैं, तालिकाओं के बीच लगातार संबंध सुनिश्चित करते हैं। आइए इन अवधारणाओं पर गौर करें:
प्राथमिक कुंजी एक स्तंभ या स्तंभों का एक समूह है जो तालिका में प्रत्येक पंक्ति को विशिष्ट रूप से पहचानता है। प्राथमिक कुंजियाँ तालिकाओं के बीच संबंध स्थापित करने और डेटा स्थिरता सुनिश्चित करने में महत्वपूर्ण हैं। प्रति तालिका केवल एक प्राथमिक कुंजी हो सकती है, और इसका मान शून्य नहीं हो सकता। अपनी तालिकाओं के लिए प्राथमिक कुंजी चुनते समय विचार करने योग्य कुछ सर्वोत्तम प्रथाएँ निम्नलिखित हैं:
विदेशी कुंजी किसी तालिका में एक स्तंभ या स्तंभों का एक समूह है जो किसी अन्य तालिका की प्राथमिक कुंजी को संदर्भित करता है। इसका उपयोग तालिकाओं के बीच संबंध स्थापित करने और संदर्भात्मक अखंडता को लागू करने के लिए किया जाता है। विदेशी कुंजी वाली तालिका को "चाइल्ड" तालिका कहा जाता है, जबकि प्राथमिक कुंजी वाली तालिका को "पैरेंट" तालिका कहा जाता है। विदेशी कुंजियाँ शून्य हो सकती हैं, जिसका अर्थ है कि चाइल्ड तालिका में एक पंक्ति को मूल तालिका में संबंधित पंक्ति की आवश्यकता नहीं है। लेकिन यदि कोई विदेशी कुंजी शून्य नहीं है, तो मूल तालिका में मेल खाने वाली प्राथमिक कुंजी मान वाली एक पंक्ति होनी चाहिए।
बाधाएँ ऐसे नियम हैं जो एक रिलेशनल डेटाबेस के भीतर डेटा अखंडता को लागू करते हैं। वे शर्तें निर्दिष्ट करते हैं कि तालिका में डेटा को पूरा करना होगा और उन संचालन को रोकना होगा जो इन शर्तों का उल्लंघन करेंगे। SQL कई प्रकार की बाधाएँ प्रदान करता है जिन्हें डेटा संरचनाओं को प्रबंधित करने के लिए कॉलम और तालिकाओं पर लागू किया जा सकता है, जिनमें शामिल हैं:
आपके डेटाबेस की अखंडता, स्थिरता और प्रदर्शन को बनाए रखने के लिए बाधाओं को उचित रूप से परिभाषित करना और प्रबंधित करना आवश्यक है। वे डेटा हेरफेर त्रुटियों और विसंगतियों को रोकते हैं जो आपके एप्लिकेशन की कार्यक्षमता और उपयोगकर्ता अनुभव को नकारात्मक रूप से प्रभावित कर सकते हैं।
SQL में, टेबल डेटाबेस के मुख्य घटक होते हैं, और वे डेटा को एक संरचित प्रारूप में संग्रहीत करते हैं। तालिकाएँ बनाते समय, आपके एप्लिकेशन की आवश्यकताओं से मेल खाने वाली डेटा संरचनाओं को परिभाषित करना आवश्यक है। यहां, हम चर्चा करेंगे कि SQL में टेबल कैसे बनाएं और उनकी डेटा संरचनाओं को कैसे परिभाषित करें।
SQL में एक तालिका बनाने के लिए, आप CREATE TABLE कथन का उपयोग करेंगे। यह कथन आपको तालिका के नाम, कॉलम और उनके संबंधित डेटा प्रकारों को निर्दिष्ट करने के साथ-साथ डेटा अखंडता बनाए रखने के लिए बाधाओं को जोड़ने की अनुमति देता है।
यहां एक सरल तालिका बनाने का एक उदाहरण दिया गया है:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100) UNIQUE, hire_date DATE );
इस उदाहरण में, हम निम्नलिखित कॉलम के साथ एक employees तालिका बनाते हैं: employee_id , first_name , last_name , email , और hire_date । हम employee_id कॉलम पर एक PRIMARY KEY बाधा और email कॉलम के लिए एक UNIQUE बाधा भी निर्दिष्ट करते हैं।
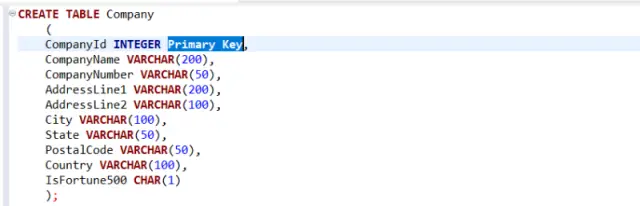
छवि स्रोत: ऑल थिंग्स एसक्यूएल
तालिका बनाने के बाद, आपको अपने एप्लिकेशन की उभरती आवश्यकताओं से मेल खाने के लिए इसकी संरचना को संशोधित करने की आवश्यकता हो सकती है। SQL ALTER TABLE स्टेटमेंट प्रदान करता है, जो आपको अपने मौजूदा टेबल में कॉलम जोड़ने, संशोधित करने या हटाने के साथ-साथ बाधाओं को जोड़ने, अपडेट करने या हटाने की अनुमति देता है।
किसी तालिका को संशोधित करने के तरीके के कुछ उदाहरण यहां दिए गए हैं:
-- Add a column ALTER TABLE employees ADD COLUMN job_title VARCHAR(50); -- Modify a column ALTER TABLE employees ALTER COLUMN job_title SET DATA TYPE VARCHAR(100); -- Drop a column ALTER TABLE employees DROP COLUMN job_title; -- Add a foreign key constraint ALTER TABLE employees ADD CONSTRAINT fk_department_id FOREIGN KEY (department_id) REFERENCES departments (department_id);
ये उदाहरण दर्शाते हैं कि employees तालिका को संशोधित करने के लिए ALTER TABLE कथन का उपयोग कैसे करें। ALTER , ADD , और UPDATE कमांड तालिका संरचना के विभिन्न पहलुओं को संशोधित करते हैं, जैसे कॉलम डेटा प्रकार और बाधाएं जोड़ना।
इंडेक्स डेटाबेस ऑब्जेक्ट हैं जो डेटा पुनर्प्राप्ति प्रक्रिया को तेज़ करने में मदद करते हैं, इस प्रकार डेटाबेस प्रदर्शन को बढ़ाते हैं। इंडेक्स बनाते समय, डेटाबेस इंजन अनुक्रमित कॉलम की एक प्रति संग्रहीत करेगा और इसे क्रमबद्ध क्रम में बनाए रखेगा, जिससे तेज़ खोज और अधिक कुशल क्वेरी निष्पादन की अनुमति मिलेगी। याद रखें कि इंडेक्स डेटा संशोधन संचालन, जैसे कि इंसर्ट, अपडेट और डिलीट के संबंध में कुछ ओवरहेड भी पेश कर सकते हैं, जिसके लिए इंडेक्स को पुनर्गठित करने की आवश्यकता हो सकती है।
एक इंडेक्स बनाने के लिए, आप CREATE INDEX स्टेटमेंट का उपयोग करेंगे। इस कथन के लिए आपको सूचकांक का नाम, वह तालिका निर्दिष्ट करनी होगी जिसके साथ आप सूचकांक को संबद्ध करना चाहते हैं, और स्तंभ(स्तंभों) को अनुक्रमित करना होगा।
यहां इंडेक्स बनाने का एक उदाहरण दिया गया है:
CREATE INDEX idx_last_name ON employees (last_name);
इस उदाहरण में, हम employees तालिका पर idx_last_name नामक एक इंडेक्स बनाते हैं और अनुक्रमित किए जाने वाले last_name कॉलम को चुनते हैं।
सूचकांकों को दो मुख्य प्रकारों में वर्गीकृत किया जा सकता है: क्लस्टर्ड इंडेक्स और गैर-क्लस्टर इंडेक्स। एक क्लस्टर्ड इंडेक्स एक तालिका के भीतर डेटा का भौतिक क्रम निर्धारित करता है और प्रति तालिका केवल एक ही हो सकता है। इसके विपरीत, गैर-क्लस्टर इंडेक्स अनुक्रमित कॉलम द्वारा क्रमबद्ध डेटा की एक अलग प्रतिलिपि संग्रहीत करते हैं, जिससे प्रति तालिका कई गैर-क्लस्टर इंडेक्स की अनुमति मिलती है।
गैर-क्लस्टर्ड इंडेक्स आम तौर पर रीड-हेवी अनुप्रयोगों के लिए बेहतर प्रदर्शन लाभ प्रदान करते हैं, जबकि क्लस्टर्ड इंडेक्स लगातार अपडेट और डिलीट और रेंज क्वेरीज़ के साथ तालिकाओं को लाभ पहुंचाते हैं।
आपके डेटाबेस के लिए सही इंडेक्स चुनने के लिए क्वेरी पैटर्न, डेटा वितरण और तालिका संरचना सहित कई कारकों पर सावधानीपूर्वक विचार करने की आवश्यकता होती है। उपयुक्त सूचकांक निर्धारित करते समय अनुसरण करने योग्य कुछ दिशानिर्देश हैं:
WHERE क्लॉज में उपयोग किया जाता है।WHERE क्लॉज में एकाधिक कॉलम का उपयोग करते हैं।डेटाबेस बनाना और प्रबंधित करना समय लेने वाला और जटिल हो सकता है, खासकर उन लोगों के लिए जिनके पास व्यापक SQL ज्ञान नहीं है। यहीं पर ऐपमास्टर no-code प्लेटफॉर्म आपकी सहायता के लिए आता है। AppMaster के साथ, आप कोड की एक भी पंक्ति लिखे बिना दृश्य रूप से डेटा मॉडल बना सकते हैं, व्यावसायिक प्रक्रियाओं को डिज़ाइन कर सकते हैं और REST API और WSS endpoints उत्पन्न कर सकते हैं।
AppMaster का प्लेटफ़ॉर्म कई लाभ प्रदान करता है, जिनमें शामिल हैं:

AppMaster नो-कोड प्लेटफ़ॉर्म का उपयोग करके, आप पारंपरिक कोडिंग विधियों की तुलना में 10 गुना तेज़ और 3 गुना अधिक लागत प्रभावी वेब, मोबाइल और बैकएंड एप्लिकेशन बना सकते हैं। AppMaster के शक्तिशाली no-code प्लेटफ़ॉर्म की खोज करके अपने डेटाबेस प्रबंधन और एप्लिकेशन विकास को अगले स्तर पर ले जाएं।
इस व्यापक गाइड में, हमने SQL में डेटा संरचनाओं के विभिन्न पहलुओं का पता लगाया, जिसमें डेटा प्रकार, प्राथमिक और विदेशी कुंजी, बाधाएं, तालिकाएं और अनुक्रमण शामिल हैं। इन अवधारणाओं में महारत हासिल करने से आप कुशल और स्केलेबल डेटाबेस बनाने में सक्षम होंगे जो जटिल अनुप्रयोगों को आसानी से संभाल सकते हैं।
जब आप SQL डेटाबेस के साथ काम करते हैं, तो भंडारण को अनुकूलित करने और डेटा अखंडता सुनिश्चित करने के लिए डेटा प्रकारों के महत्व पर विचार करना याद रखें। इसके अलावा, प्राथमिक और विदेशी कुंजी के माध्यम से तालिकाओं के बीच संबंध स्थापित करें, और बाधाओं का उपयोग करके डेटा अखंडता नियमों को लागू करें। अंत में, तेजी से डेटा पुनर्प्राप्ति सक्षम करने और क्वेरी निष्पादन योजनाओं को अनुकूलित करने के लिए इंडेक्स का उपयोग करके अपने डेटाबेस प्रदर्शन को बढ़ाएं।
मान लीजिए कि आप SQL डेटा संरचनाओं की बारीकियों में पड़े बिना एप्लिकेशन बनाने का कोई तरीका ढूंढ रहे हैं। उस स्थिति में, AppMaster एक शक्तिशाली no-code प्लेटफ़ॉर्म प्रदान करता है जो आपको डेटा मॉडल और वेब और मोबाइल एप्लिकेशन को दृश्य रूप से बनाने की अनुमति देता है। AppMaster के साथ, आप तकनीकी ऋण को खत्म कर सकते हैं और बेहतर प्रोजेक्ट स्केलेबिलिटी का आनंद ले सकते हैं। AppMaster आज़माएं और no-code ऐप डेवलपमेंट की सरलता और दक्षता का अनुभव करें। SQL डेटा संरचनाओं की ठोस समझ और AppMaster, you're now better equipped to create, manage, and optimize databases for your projects.
SQL में डेटा संरचनाओं की कुछ मुख्य विशेषताओं में डेटा प्रकार, प्राथमिक और विदेशी कुंजी, बाधाएँ, तालिकाएँ और अनुक्रमणिकाएँ शामिल हैं।
SQL में डेटा प्रकार महत्वपूर्ण हैं क्योंकि वे उस डेटा के प्रकार को परिभाषित करते हैं जिसे एक कॉलम में संग्रहीत किया जा सकता है, डेटा अखंडता सुनिश्चित करते हैं, और भंडारण और प्रदर्शन को अनुकूलित करने में मदद करते हैं।
प्राथमिक कुंजियाँ और विदेशी कुंजियाँ तालिकाओं के बीच संबंध स्थापित करके, संदर्भात्मक अखंडता को लागू करके और तालिका में प्रत्येक पंक्ति के लिए एक अद्वितीय पहचानकर्ता प्रदान करके SQL डेटा संरचनाओं में महत्वपूर्ण भूमिका निभाती हैं।
बाधाएँ डेटा अखंडता नियमों को लागू करके SQL में डेटा संरचनाओं को प्रबंधित करने में मदद करती हैं, यह सुनिश्चित करती हैं कि डेटाबेस में डेटा विशिष्ट शर्तों का अनुपालन करता है, और डेटा हेरफेर त्रुटियों को रोकता है।
SQL में इंडेक्स तेजी से डेटा पुनर्प्राप्ति की अनुमति देकर, डिस्क से पढ़ने के लिए आवश्यक डेटा की मात्रा को कम करके और क्वेरी निष्पादन योजना को अनुकूलित करके डेटाबेस प्रदर्शन को बढ़ा सकते हैं।
AppMaster का नो-कोड प्लेटफ़ॉर्म विज़ुअल डेटा मॉडल, बिजनेस प्रोसेस डिज़ाइनर, REST API और WSS एंडपॉइंट, तेज़ एप्लिकेशन विकास, तकनीकी ऋण का उन्मूलन और डेटाबेस प्रबंधन के लिए बेहतर स्केलेबिलिटी जैसे लाभ प्रदान करता है।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


