
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
使用 SQL 编码时首先要知道的是 create table 语句。这是您在创建表时应该注意的所有内容。

SQL 是一种特定领域的语言,工程师使用它来处理存储在关系数据库中的数据或用于关系数据流管理系统中的流处理。您可以通过表将数据存储在 关系数据库 中。在此过程中要做的第一件事是创建要处理的数据库。然后我们创建将存储实际数据的表。这种数据库中的表将同时具有行和列。
将有一个特定的数据类型与每一列相关联,以确定它可以存储的数据类型。创建表时,我们必须指定每列的名称和数据类型。您可以在 MySQL 和 PostgreSQL 数据库中使用 SQL CREATE TABLE 命令创建表。
让我们更深入地了解 CREATE TABLE SQL 语句。
您可以使用以下语法在 MySQL 中创建表:
创建表表名(
column_1 data_type 默认值 column_constraint ,
column_2 data_type 默认值 column_constraint ,
...,
…,
表约束
);
创建表时应具备的基本内容是其名称和至少一个列名。应该只有一个具有特定 表名 的数据库表。如果您尝试创建两个具有相同名称的表,数据库将向您显示一条错误消息。
在括号内,我们指定要在表中创建的列的名称,以及将要输入的数据的数据类型。逗号将分隔这些列的名称。名称、数据类型、列的默认值以及一个或多个列限制构成了每一列。
列约束控制可以存储在列中的实际数据值。例如, NOT NULL 约束保证该特定列中不存在 NULL 值。单个列可以有多个约束。例如,一列可以同时包含 NOT NULL 和 UNIQUE 限制。
如果要对表中的所有列应用约束,可以使用表约束。一些相同的例子是 FOREIGN KEY 、 CHECK 和 UNIQUE 。每个表都可以有一个由一个或多个列组成的主键。此主键用于唯一标识表中的每条记录。通常,您首先列出主键列,然后再列出其他列。如果 PRIMARY KEY 约束由两列或多列组成,则必须将其声明为表约束。
让我们看一个例子:
创建表客户(
ID INT NOT NULL,
名称 VARCHAR (20) 非空,
年龄不为空,
工资小数 (18, 2),
主键 (ID)
);
这里,表名是“CUSTOMERS”,主键是ID。 ID、NAME 和 AGE 列具有 NOT NULL 约束。名称的长度应少于 20 个字符。现在,我们已经使用 SQL CREATE TABLE 命令创建了一个表,我们可以将相关数据插入到它和数据库中。
表内有表称为表嵌套。为此,我们必须使用 SQL CREATE TABLE 命令在另一个表中创建一个表。这是 MySQL 中不存在的概念。但是,我们可以通过使用主键和外键来实现与嵌套表相同的结果。这在两个表之间创建了父子关系。
一个表中引用另一个表的 PRIMARY KEY 的字段或一组字段称为 FOREIGN KEY 。具有主键的表称为父表,具有外键的表称为子表。
例如,假设我们有一个父表 Vehicle,其主键是 VehId。我们还有两个表,Car,主键为 CarId,Truck,主键分别为 TruckId。如果我们在 Car 和 Truck 中都将 VehId 作为外键,那么 Vehicle 将成为其父表,从而创建父子关系。
父表车辆 {VehId}
子表
1.汽车{VehId,CarId}
2. 卡车 {VehId,TruckId}
是否可以在不先创建 SQL 表的情况下选择它?
要从数据库中选择数据,我们使用 SELECT 语句。来自此的数据保存在称为结果集的结果表中。这用于选择表格的一部分或整个表格。当您编写代码并使用 SQL CREATE TABLE 命令创建表时,可以使用 SELECT 命令查看您创建的表。
它的语法是这样的:
选择 column_1、column_2、…
从表名;
例如,以下命令选择整个表。
选择 \* FROM 表名;
选择进入
使用 SELECT INTO 语句将一个表中的数据传输到另一个表中。它可以将一个表的所有列复制到另一个表中。这通常在数据被复制到的表已经存在时使用。
要选择表的所有列:
选择 *
INTO new_table [IN externaldb]
从旧表
WHERE 条件;
要在新表中仅选择几列:
选择 column_1,column_2,column_3,...
INTO new_table [IN externaldb]
从旧表
WHERE 条件;
那么,如果我们还没有使用 SQL CREATE TABLE 创建一个表,我们可以选择它吗?
从逻辑上讲,答案应该是否定的。但事实并非如此,即使我们还没有创建它,我们也可以选择到一个表中。当必须形成一个表,并且需要将一个表中的数据传输到新生成的表中时,就会使用这种方法。与所选列相同的数据类型用于生成新表。
SQL 中的产品表可以通过多种方式创建。利用 SQL CREATE TABLE 语句是一种选择。产品信息将包含在此语句将创建的表中。 SELECT 命令还可用于查看和获取表中的数据。上面已经提到了这两种语法。
INSERT 命令也可用于将新数据插入表中。由于 INSERT 语句,数据将被插入到表中的指定位置。也可以使用 SELECT 查询从表中取出数据,然后使用 INSERT 语句将数据添加到另一个表中。
插入
我们使用 INSERT INTO 语句将新记录添加到表中。 INSERT 语句的语法是:
INSERT INTO table_name (column_1, column_2, ...)
值(值_1,值_2,...);
使产品表不同的只是相同的设计方面。产品的名称、型号、类别、型号年份和标价都存储在产品数据库中。每个项目都是品牌 ID 列标识的品牌的一部分。因此,一个品牌可以拥有一种或多种产品。每个产品都是一个类别的成员,该类别由表中的类别 ID 标识。
在使用 SQL CREATE TABLE 命令时,我们不得不提到列的数据类型。列可以包含的数据取决于此数据类型。示例包括整数、字符、二进制、日期和时间等。数据库表必须具有名称以及每一列的数据类型。
在构建表时,SQL 程序员必须确定每列将包含哪种数据。数据类型指定 SQL 将如何与存储的数据交互。它有助于确定每列中预期的数据类型。 MySQL 8.0 中的三种主要数据类型是字符串、数字以及日期和时间。
字符串数据类型
字符串数据类型通常是一组属于英文字母表的字符。主要的字符串数据类型有:
这里的 SIZE 代表存储数据可以采用的最大大小。 CHAR 是固定长度的字符串,而 VARCHAR 是可变字符串长度的字符串。这些是最常用的字符串数据类型。 BLOB 是二进制大对象。
数值数据类型
数值数据类型变量用于保存数值数据。它们进一步分为两种数据类型——精确和近似。精确数据类型用于以文字形式保存数据值。虽然实数包含在近似数据类型中,但信息并没有真正保存为真实值的副本。主要的数值数据类型有:
最常用的数值数据类型是 INT 。它用于保存非十进制数,而数据类型为 FLOAT 的变量用于保存十进制数。在 BOOL 数据类型中,零被认为是 FALSE ,非零值被认为是 TRUE 。
日期和时间
日期和时间数据类型用于保存日期数据。主要的日期和时间数据类型有:
SQL Server 数据类型与上面给出的数据类型相似,但在语法上略有不同。
MS SQL 服务器中存在两类变量:
用户声明一个局部变量。它总是以@开头。每个局部变量的范围都被限制在当前在特定会话中运行的批处理或进程中。 Transact-SQL 局部变量是一种对象,它只能存储一种特定类型的数据值。脚本和批处理经常使用变量:
系统保持全局变量。用户不能将它们公开。 @@ 是全局变量开始的地方。它保存有关会话的数据。
如果您在批量或过程中使用它之前定义了任何变量,这将有所帮助。内存位置替换变量是使用 DECLARE 命令声明的。变量只有在随后的批处理或过程步骤中声明后才能使用。
声明变量的 TSQL 语法如下所示:
声明 {@LOCAL_VARIABLE[AS] 数据类型 [= 值] }
程序员还可以通过以下方式确定已定义变量的值:
数据类型是任何编码语言的基本组成部分之一,无论是 C 等编程语言还是 SQL 等数据操作语言。实际上,SQL 支持超过 30 种数据类型,可以存储各种形式的实际数据。最好在开始处理数据之前牢牢掌握各种 SQL 数据类型。
可以在数据库对象(如表)中保存的信息类型由 SQL 数据类型指定。表中的每一列都有名称和数据类型,每张表都有列。它们构成了任何语言的支柱,因为不使用它们就无法操作数据。
您应该知道,并非所有数据类型都受数据库系统支持。因此,您必须在使用任何特定数据类型之前进行检查。例如,您不能在 Oracle 中使用 DateTime,因为它不允许这种数据类型。
同样,MySQL 也不使用 Unicode 作为数据类型。您可以使用某些数据库具有的额外数据类型。例如,Microsoft SQL Server 中的“money”和“smallmoney”可以代替“float”和“real”,但这些术语是特定于数据库的,在其他数据库系统中不存在。有时,特定的数据类型在某些数据库中具有不同的名称。例如,Oracle 将“十进制”称为“数字”,将“blob”称为“原始”。
是的。在多个表中,主键可以共享相同的列名。在表中,列名必须是不同的。因为它决定了实体的完整性,所以一张表只能包含一个主键。每个表都可能包含一个主键,但这不是必需的。由于指定为主键的一列或多列,没有两行可以共享相同的主键。一个表的主键可用于标识另一个表的记录,并成为第二个表的主键的一部分。
ORDER BY 命令可用于对结果集进行排序。这可以是升序或降序。记录通常使用 ORDER BY 关键字按升序排序。您可以使用 DESC 关键字按降序排列条目。
order 的语法如下所示:
选择 column_1,column_2,...
FROM 表名
按 column_1、column_2、... ASC|DESC 排序;
例如,假设有一个名为 Users 的表;您可以根据用户所在的城市按升序或降序对其进行排序。
从用户中选择 *
按城市订购;
要按降序对相同的内容进行排序:
从用户中选择 *
按城市 DESC 排序;
只需像往常一样在主键的名称上使用 ORDER BY,例如“RollID”:
SELECT * FROM my_table WHERE col_1 < 5 ORDER BY RollID;
查询优化器可能会或可能不会决定使用主键索引结构来分析排序,而不是对查询结果集进行主动排序以根据其决定评估查询的方式来处理 ORDER BY。
大多数没有 ORDER BY 子句的单表查询将按主键顺序返回结果,因为 MySQL InnoDB 以接近原生主键顺序的方式存储表。但是,如果您的应用程序确实需要主键排序,您仍然可以使用 ORDER BY。
无代码开发 方法是促进编码民主化的主要因素之一。如今,更多的人原则上可以在不知道任何编码的情况下使用计算。它有助于构建响应式网站以及移动应用程序。
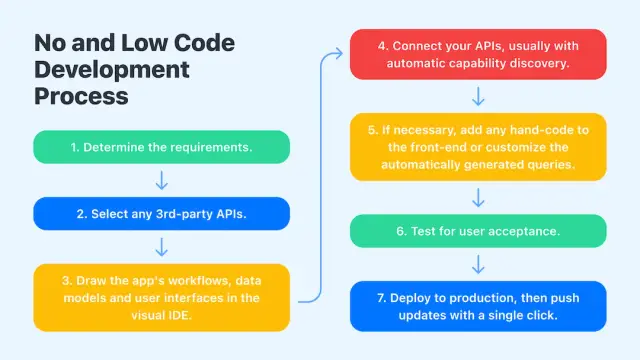
AppMaster 可以帮助您自动生成源代码。该代码始终可供您查看和检查。您可以选择使用带有 AppMaster 的编程语言修改项目详细信息。我们还为用户提供导出代码的选项。这是一个承诺,即您使用 AppMaster 开发的软件完全在您的控制和所有权之内。
SQL 有几个应用程序使其非常有吸引力。创建数据集成脚本、设计和执行分析查询以及访问数据库中的数据子集以获取洞察和事务处理是其最突出的目的。它还可用于插入、修改和删除数据库中的数据行和列。
在深入 SQL 之前,我们需要熟悉它的基本命令和语法。通过上面的文章,我们可以了解更多关于 SQL 中使用的基本语句,如 CREATE TABLE、INSERT INTO、SELECT 等。




