App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
La prima cosa da sapere quando si codifica in SQL è l'istruzione create table. Ecco tutto ciò che si deve sapere quando si crea una tabella.

SQL è un linguaggio specifico che gli ingegneri utilizzano per gestire i dati memorizzati nei database relazionali o per l'elaborazione dei flussi nei sistemi di gestione dei flussi di dati relazionali. I dati possono essere memorizzati in un database relazionale tramite tabelle. La prima cosa da fare in questo processo è creare il database su cui si vuole lavorare. Quindi si creano le tabelle in cui verranno memorizzati i dati effettivi. Una tabella in un database di questo tipo avrà sia righe che colonne.
A ogni colonna è associato un particolare tipo di dato che determina il tipo di dati che essa può memorizzare. Durante la creazione della tabella, è necessario specificare il nome e il tipo di dati di ciascuna colonna. È possibile creare una tabella utilizzando il comando SQL CREATE TABLE sia nei database MySQL che PostgreSQL.
Diamo un'occhiata più approfondita all'istruzione SQL CREATE TABLE.
È possibile creare una tabella in MySQL con la seguente sintassi:
CREATE TABLE nome_tabella(
column_1 data_type default value column_constraint,
column_2 data_type valore predefinito column_constraint,
...,
...,
vincolo_tabella
);
Gli elementi fondamentali che si devono avere durante la creazione di una tabella sono il suo nome e almeno un nome di colonna. Deve esistere una sola tabella del database con un particolare nome di tabella. Il database mostrerà un messaggio di errore se si cerca di creare due tabelle con lo stesso nome.
All'interno delle parentesi, si specificano i nomi delle colonne che si vogliono creare nella tabella, insieme al tipo di dati che vi verranno inseriti. Le virgole separano i nomi delle colonne. Il nome, il tipo di dati, il valore predefinito della colonna e una o più restrizioni di colonna costituiscono ogni colonna.
I vincoli di colonna controllano il valore effettivo dei dati che possono essere memorizzati nella colonna. Ad esempio, il vincolo NOT NULL garantisce che non esistano valori NULL in quella particolare colonna. È possibile avere più di un vincolo per una singola colonna. Ad esempio, una colonna può contenere sia il vincolo NOT NULL che UNIQUE.
Se si vogliono applicare vincoli a tutte le colonne della tabella, si possono usare i vincoli della tabella. Alcuni esempi sono FOREIGN KEY, CHECK e UNIQUE. Ogni tabella può avere una chiave primaria composta da una o più colonne. Questa chiave primaria viene utilizzata per identificare in modo univoco ogni record di una tabella. Normalmente, si elenca prima la colonna della chiave primaria e poi le altre. È necessario dichiarare il vincolo PRIMARY KEY come vincolo di tabella se è composto da due o più colonne.
Vediamo un esempio:
CREARE UNA TABELLA CLIENTI(
ID INT NON NULL,
NOME VARCHAR (20) NON NULLO,
ETÀ INT NON NULLO,
STIPENDIO DECIMALE (18, 2),
CHIAVE PRIMARIA (ID)
);
Qui il nome della tabella è "CLIENTI" e la sua chiave primaria è ID. Le colonne ID, NAME e AGE hanno un vincolo di NOT NULL. La lunghezza del nome deve essere inferiore a 20 caratteri. Ora abbiamo creato una tabella con il comando SQL CREATE TABLE e possiamo inserire i dati pertinenti in essa e nel database.
L'inserimento di una tabella all'interno di una tabella si chiama annidamento di tabelle. Per questo, dovremmo creare una tabella all'interno di un'altra tabella con il comando SQL CREATE TABLE. Questo è un concetto che non esiste in MySQL. Tuttavia, possiamo ottenere lo stesso risultato delle tabelle annidate utilizzando una chiave primaria e una chiave esterna. In questo modo si crea una relazione genitore-figlio tra le due tabelle.
Un campo o un gruppo di campi di una tabella che fa riferimento alla CHIAVE PRIMARIA di un'altra tabella è noto come CHIAVE ESTERNA. La tabella con la chiave primaria principale viene chiamata tabella padre, mentre quella con la chiave esterna viene chiamata tabella figlio.
Ad esempio, supponiamo di avere una tabella padre, Veicolo, la cui chiave primaria è VehId. Abbiamo altre due tabelle, Car, con chiave primaria CarId, e Truck, con chiave primaria TruckId, rispettivamente. Se inseriamo VehId come chiave esterna sia in Auto che in Camion, Veicolo diventerà la sua tabella padre, creando così una relazione genitore-figlio.
Tabella padre Veicolo {VehId}
Tabelle figlio
1. Auto {VehId,CarId}
2. Camion {VehId,TruckId}
È possibile selezionare in una tabella SQL senza prima crearla?
Per scegliere i dati da un database, si usa l'istruzione SELECT. I dati ottenuti vengono conservati in una tabella di risultati chiamata set di risultati. Questa viene utilizzata per selezionare una parte di una tabella o l'intera tabella. Dopo aver creato una tabella con il comando SQL CREATE TABLE, è possibile utilizzare il comando SELECT per visualizzare le tabelle create.
La sintassi è la seguente:
SELECT colonna_1, colonna_2, ...
FROM nome_tabella;
Ad esempio, il comando seguente seleziona l'intera tabella.
SELECT * FROM nome_tabella;
SELEZIONARE INTO
I dati di una tabella vengono trasferiti in un'altra tabella con l'istruzione SELECT INTO. Può copiare tutte le colonne di una tabella in un'altra. Di solito si usa quando la tabella in cui si vogliono copiare i dati esiste già.
Per selezionare tutte le colonne di una tabella:
SELECT *
INTO nuova_tabella [IN externaldb]
DALLA VECCHIA TABELLA
Dove la condizione;
Per selezionare solo alcune colonne nella nuova tabella:
SELECT colonna_1, colonna_2, colonna_3, ...
INTO nuova_tabella [IN externaldb]
DALLA VECCHIA TABELLA
condizione WHERE;
Quindi, possiamo selezionare in una tabella se non l'abbiamo ancora creata con SQL CREATE TABLE?
A rigor di logica, la risposta dovrebbe essere no. Ma non è così e possiamo selezionare una tabella anche se non l'abbiamo ancora creata. Quando si deve formare una tabella e i dati di una tabella devono essere trasferiti nella nuova tabella, si utilizza questo approccio. Per generare la nuova tabella si utilizzano gli stessi tipi di dati delle colonne scelte.
Una tabella prodotti in SQL può essere creata in vari modi. Un'opzione è l'utilizzo dell'istruzione SQL CREATE TABLE. Le informazioni sui prodotti saranno contenute in una tabella creata da questa istruzione. È possibile utilizzare anche il comando SELECT per visualizzare e ottenere i dati dalla tabella. La sintassi di entrambi è stata menzionata in precedenza.
Il comando INSERT può essere usato anche per inserire nuovi dati nella tabella. Grazie all'istruzione INSERT, i dati verranno inseriti nella tabella nella posizione designata. I dati possono anche essere prelevati dalla tabella con la query SELECT e poi aggiunti a un'altra tabella con l'istruzione INSERT.
INSERIMENTO INTO
L'istruzione INSERT INTO serve per aggiungere nuovi record a una tabella. La sintassi dell'istruzione INSERT è la seguente:
INSERT INTO nome_tabella (colonna_1, colonna_2, ...)
VALUES (valore_1, valore_2, ...);
Ciò che rende diversa una tabella di prodotti è solo l'aspetto progettuale della stessa. Il nome del prodotto, il modello, la classe, l'anno del modello e il prezzo di listino sono tutti memorizzati nel database dei prodotti. Ogni articolo fa parte del marchio identificato dalla colonna id del marchio. Di conseguenza, un marchio può avere un solo prodotto o molti. Ogni prodotto fa parte di una categoria, identificata dall'id della categoria nella tabella.
Quando si utilizza il comando SQL CREATE TABLE, è necessario indicare i tipi di dati delle colonne. I dati che una colonna può includere dipendono dal tipo di dati. Tra gli esempi vi sono numeri interi, caratteri, binari, data e ora e altri ancora. Una tabella di database deve avere un nome e un tipo di dati per ogni colonna.
Quando costruisce una tabella, il programmatore SQL deve stabilire quale tipo di dati sarà contenuto in ogni colonna. Il tipo di dati specifica come SQL si interfaccerà con i dati memorizzati. Aiuta a determinare il tipo di dati previsti all'interno di ogni colonna. I tre tipi di dati principali in MySQL 8.0 sono stringa, numerico e data e ora.
Tipi di dati stringa
I tipi di dati stringa sono generalmente un insieme di caratteri appartenenti all'alfabeto inglese. I principali tipi di dati stringa sono:
Qui SIZE indica la dimensione massima dei dati memorizzati. CHAR è una stringa di lunghezza fissa, mentre VARCHAR è una stringa di lunghezza variabile. Questi sono i tipi di dati stringa più utilizzati. Un BLOB è un oggetto binario di grandi dimensioni.
Tipi di dati numerici
Le variabili di tipo numerico sono utilizzate per contenere dati numerici. Si dividono in due tipi di dati: esatti e approssimativi. I tipi di dati esatti sono utilizzati per contenere il valore dei dati nella sua forma letterale. Mentre i numeri reali sono contenuti nei tipi di dati approssimativi, le informazioni non vengono salvate letteralmente come copia dei valori reali. I principali tipi di dati numerici sono:
Il tipo di dati numerici più comunemente utilizzato è INT. Viene utilizzato per contenere numeri non decimali, mentre le variabili con tipo di dati FLOAT vengono utilizzate per contenere numeri decimali. Nel tipo di dati BOOL, lo zero è considerato FALSO e i valori non nulli sono considerati VERO.
Data e ora
I tipi di dati data e ora sono utilizzati per contenere dati relativi alla data. I principali tipi di dati di data e ora sono:
I tipi di dati del server SQL sono simili ai tipi di dati sopra indicati, ma con piccole differenze sintattiche.
Nel server MS SQL esistono due categorie di variabili:
Un utente dichiara una variabile locale. Essa inizia sempre con @. L'ambito di ciascuna variabile locale è limitato al batch o al processo in esecuzione all'interno di una particolare sessione. Una variabile locale Transact-SQL è una sorta di oggetto che può memorizzare solo un particolare tipo di valore di dati. Gli script e i batch utilizzano spesso le variabili:
Il sistema tiene traccia delle variabili globali. Gli utenti non possono renderle pubbliche. @@ è il punto in cui inizia la variabile globale. Conserva i dati relativi alle sessioni.
È utile definire una variabile prima di utilizzarla in un batch o in un processo. La variabile sostitutiva della posizione di memoria viene dichiarata con il comando DECLARE. Una variabile può essere utilizzata solo dopo essere stata dichiarata nella fase successiva del batch o della procedura.
La sintassi TSQL per dichiarare una variabile è la seguente:
DECLARE { @LOCAL_VARIABLE[AS] data_type [ = value ] }
Il programmatore può anche decidere il valore di una variabile definita da :
Il tipo di dati è uno dei componenti essenziali di qualsiasi linguaggio di codifica, sia esso un linguaggio di programmazione come il C o un linguaggio di manipolazione dei dati come SQL. In realtà, SQL supporta oltre 30 tipi di dati che possono memorizzare varie forme di dati reali. Prima di iniziare a trattare i dati, sarebbe meglio avere una conoscenza approfondita dei vari tipi di dati SQL.
I tipi di informazioni che possono essere contenute in oggetti di database come le tabelle sono specificati dai tipi di dati SQL. Ogni colonna di una tabella ha un nome e un tipo di dati e ogni tabella ha delle colonne. Questi tipi di dati costituiscono la spina dorsale di qualsiasi linguaggio, poiché non è possibile manipolare i dati senza utilizzarli.
È bene sapere che non tutti i tipi di dati sono supportati dai sistemi di database. Pertanto, è necessario verificare prima di utilizzare un particolare tipo di dati. Per esempio, non si può usare DateTime in Oracle, perché non consente questo tipo di dati.
Allo stesso modo, MySQL non utilizza Unicode come tipo di dati. È possibile utilizzare i tipi di dati extra che alcuni database hanno. Per esempio, "money" e "smallmoney" in Microsoft SQL Server possono essere sostituiti da "float" e "real", ma questi termini sono specifici del database e non sono presenti in altri sistemi di database. A volte, alcuni tipi di dati specifici hanno nomi diversi in alcuni database. Oracle, ad esempio, chiama "decimal" "number" e "blob" "raw".
Sì. In più tabelle, la chiave primaria può avere lo stesso nome di colonna. All'interno di una tabella, i nomi delle colonne devono essere distinti. Poiché determina l'integrità delle Entità, una tabella può contenere una sola chiave primaria. Ogni tabella può contenere una chiave primaria, ma non è obbligatorio. Due righe non possono condividere la stessa chiave primaria, grazie alla colonna o alle colonne designate come chiave primaria. La chiave primaria di una tabella può essere utilizzata per identificare i record di un'altra tabella ed essere parte della chiave primaria della seconda.
Il comando ORDER BY può essere utilizzato per ordinare l'insieme dei risultati. L'ordinamento può essere ascendente o discendente. In genere, i record vengono ordinati con la parola chiave ORDER BY in ordine crescente. È possibile utilizzare la parola chiave DESC per ordinare le voci in ordine decrescente.
La sintassi dell'ordine è la seguente
SELECT colonna_1, colonna_2, ...
DA nome_tabella
ORDINA PER colonna_1, colonna_2, ... ASC|DESC;
Ad esempio, supponiamo che esista una tabella chiamata Utenti; è possibile ordinarla in ordine crescente o decrescente in base alla città degli utenti.
SELEZIONARE * DA UTENTI
ORDINARE PER CITTA';
Per ordinare la stessa tabella in ordine decrescente:
SELECT * FROM Utenti
ORDINARE PER CITTA' DESC;
È sufficiente utilizzare ORDER BY come di consueto sul nome della chiave primaria, ad esempio "RollID":
SELECT * FROM my_table WHERE col_1 < 5 ORDER BY RollID;
L'ottimizzatore di query potrebbe decidere di utilizzare o meno la struttura dell'indice della chiave primaria per analizzare l'ordinamento piuttosto che eseguire un ordinamento attivo sul set di risultati della query per risolvere l'ORDER BY, in base a come decide di valutare la query.
La maggior parte delle query a tabella singola senza clausola ORDER BY restituirà i risultati nell'ordine della chiave primaria, poiché MySQL InnoDB memorizza le tabelle in quello che è l'ordine nativo della chiave primaria. Tuttavia, è possibile utilizzare un ORDER BY se l'applicazione richiede effettivamente un ordine di chiave primaria.
La metodologia di sviluppo senza codice è uno dei principali fattori che promuovono la democratizzazione della codifica. Al giorno d'oggi, un numero sempre maggiore di persone ha accesso all'informatica in linea di principio senza conoscere la codifica. Questo facilita la creazione di siti web reattivi e di applicazioni mobili.
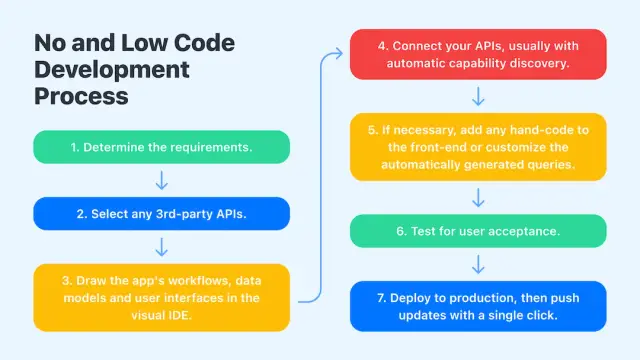
AppMaster può aiutarvi a generare automaticamente il codice sorgente. Il codice è sempre disponibile per essere visualizzato ed esaminato. Con AppMaster è possibile modificare i dettagli del progetto utilizzando un linguaggio di programmazione. Inoltre, gli utenti hanno la possibilità di esportare il codice. Questa è una promessa che il software che state sviluppando con AppMaster è interamente sotto il vostro controllo e proprietà.
SQL ha diverse applicazioni che lo rendono molto interessante. La creazione di script di integrazione dei dati, la progettazione e l'esecuzione di query analitiche e l'accesso a sottoinsiemi di dati da un database per l'analisi e l'elaborazione delle transazioni sono alcuni dei suoi scopi più importanti. Può anche essere utilizzato per inserire, modificare e rimuovere righe e colonne di dati in un database.
Prima di addentrarci nelle profondità di SQL, dobbiamo familiarizzare con i suoi comandi e la sua sintassi di base. Leggendo l'articolo qui sopra, possiamo conoscere meglio le istruzioni di base utilizzate in SQL, come CREATE TABLE, INSERT INTO, SELECT e altre ancora.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


