Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Das erste, was Sie wissen müssen, wenn Sie in SQL codieren, ist die Anweisung zum Erstellen einer Tabelle. Hier ist alles, was Sie beim Erstellen einer Tabelle beachten sollten.

SQL ist eine domänenspezifische Sprache, die Ingenieure verwenden, um Daten zu verarbeiten, die in relationalen Datenbanken gespeichert sind, oder für die Stream-Verarbeitung in Managementsystemen für relationale Datenströme. Sie können Daten in einer relationalen Datenbank über Tabellen speichern. Das erste, was Sie in diesem Prozess tun müssen, ist, die Datenbank zu erstellen, an der Sie arbeiten möchten. Dann erstellen wir Tabellen, in denen die eigentlichen Daten gespeichert werden. Eine Tabelle in einer solchen Datenbank hat sowohl Zeilen als auch Spalten.
Jeder Spalte ist ein bestimmter Datentyp zugeordnet, der die Art der Daten bestimmt, die sie speichern kann. Beim Erstellen der Tabelle müssen wir den Namen und den Datentyp jeder Spalte angeben. Sie können eine Tabelle mit dem SQL-Befehl CREATE TABLE sowohl in MySQL- als auch in PostgreSQL-Datenbanken erstellen.
Werfen wir einen genaueren Blick auf die SQL-Anweisung CREATE TABLE.
Sie können eine Tabelle in MySQL mit der folgenden Syntax erstellen:
TABELLE ERSTELLEN Tabellenname(
column_1 data_type Standardwert column_constraint ,
column_2 data_type Standardwert column_constraint ,
...,
…,
table_constraint
);
Die grundlegenden Dinge, die Sie beim Erstellen einer Tabelle haben sollten, sind ihr Name und mindestens ein Spaltenname. Es sollte nur eine Datenbanktabelle mit einem bestimmten Tabellennamen vorhanden sein. Die Datenbank zeigt Ihnen eine Fehlermeldung an, wenn Sie versuchen, zwei Tabellen mit demselben Namen zu erstellen.
Innerhalb der Klammern geben wir die Namen der Spalten an, die wir in der Tabelle erstellen möchten, zusammen mit dem Datentyp der Daten, die darin eingegeben werden. Kommas trennen die Namen dieser Spalten. Jede Spalte besteht aus dem Namen, dem Datentyp, dem Standardwert der Spalte und einer oder mehreren Spalteneinschränkungen.
Die Spaltenbeschränkungen steuern den tatsächlichen Datenwert, der in der Spalte gespeichert werden kann. Beispielsweise garantiert die NOT NULL- Einschränkung, dass in dieser bestimmten Spalte keine NULL- Werte vorhanden sind. Sie können mehr als eine Einschränkung für eine einzelne Spalte haben. Beispielsweise kann eine Spalte sowohl die NOT NULL- als auch die UNIQUE- Einschränkung enthalten.
Wenn Sie Einschränkungen auf alle Spalten in der Tabelle anwenden möchten, können Sie die Tabelleneinschränkungen verwenden. Einige Beispiele dafür sind FOREIGN KEY , CHECK und UNIQUE . Jede Tabelle kann einen Primärschlüssel haben, der aus einer oder mehreren Spalten besteht. Dieser Primärschlüssel wird verwendet, um jeden Datensatz einer Tabelle eindeutig zu identifizieren. Normalerweise listen Sie zuerst die Primärschlüsselspalte und dann die anderen auf. Sie müssen die PRIMARY KEY -Einschränkung als Tabelleneinschränkung deklarieren, wenn sie aus zwei oder mehr Spalten besteht.
Schauen wir uns ein Beispiel an:
TABELLE KUNDEN ERSTELLEN(
ID INT NICHT NULL,
NAME VARCHAR (20) NICHT NULL,
ALTER INT NICHT NULL,
GEHALT DEZIMAL (18, 2),
PRIMÄRSCHLÜSSEL (ID)
);
Hier lautet der Name der Tabelle „CUSTOMERS“, und ihr Primärschlüssel ist ID. Die Spalten ID, NAME und AGE haben die Einschränkung NOT NULL . Die Länge des Namens sollte weniger als 20 Zeichen betragen. Jetzt haben wir mit dem SQL-Befehl CREATE TABLE eine Tabelle erstellt und können die relevanten Daten in diese und die Datenbank einfügen.
Eine Tabelle in einer Tabelle zu haben, würde man als Verschachtelung von Tabellen bezeichnen. Dazu müssten wir mit dem SQL-Befehl CREATE TABLE eine Tabelle in einer anderen Tabelle erstellen. Dies ist ein Konzept, das in MySQL nicht existiert. Wir können jedoch das gleiche Ergebnis wie bei verschachtelten Tabellen erzielen, indem wir einen Primärschlüssel und einen Fremdschlüssel verwenden. Dadurch wird eine Eltern-Kind-Beziehung zwischen den beiden Tabellen erstellt.
Ein Feld oder eine Gruppe von Feldern in einer Tabelle, die auf den PRIMARY KEY einer anderen Tabelle verweist, wird als FOREIGN KEY bezeichnet. Die Tabelle mit dem Hauptprimärschlüssel wird als übergeordnete Tabelle bezeichnet, während die mit dem Fremdschlüssel als untergeordnete Tabelle bezeichnet wird.
Angenommen, wir haben eine übergeordnete Tabelle Fahrzeug, deren Primärschlüssel VehId ist. Wir haben zwei weitere Tabellen, „Car“ mit dem Primärschlüssel „CarId“ und „Truck“ mit dem Primärschlüssel „TruckId“. Wenn wir VehId sowohl in Car als auch in Truck als Fremdschlüssel einfügen, wird Vehicle zur übergeordneten Tabelle, wodurch eine Eltern-Kind-Beziehung entsteht.
Übergeordnete Tabelle Fahrzeug {VehId}
Untergeordnete Tabellen
1. Auto {VehId,CarId}
2. LKW {VehId,TruckId}
Ist es möglich, eine SQL-Tabelle auszuwählen, ohne sie zuerst zu erstellen?
Um Daten aus einer Datenbank auszuwählen, verwenden wir die SELECT-Anweisung. Die Daten daraus werden in einer Ergebnistabelle gespeichert, die Ergebnismenge genannt wird. Dies wird verwendet, um einen Teil einer Tabelle oder die gesamte Tabelle auszuwählen. Wenn Sie codieren und eine Tabelle mit dem SQL-Befehl CREATE TABLE erstellt haben, können Sie den SELECT-Befehl verwenden, um die von Ihnen erstellten Tabellen anzuzeigen.
Seine Syntax ist wie folgt:
SELECT Spalte_1, Spalte_2, …
FROM Tabellenname;
Der folgende Befehl wählt beispielsweise die gesamte Tabelle aus.
SELECT * FROM Tabellenname;
AUSWÄHLEN IN
Daten aus einer Tabelle werden mit der Anweisung SELECT INTO in eine andere Tabelle übertragen. Es kann alle Spalten einer Tabelle in eine andere kopieren. Dies wird normalerweise verwendet, wenn die Tabelle, in die die Daten kopiert werden, bereits vorhanden ist.
So wählen Sie alle Spalten einer Tabelle aus:
AUSWÄHLEN *
INTO neue_Tabelle [IN externe Datenbank]
VON old_table
WHERE-Bedingung;
So wählen Sie nur wenige Spalten in der neuen Tabelle aus:
SELECT Spalte_1, Spalte_2, Spalte_3, ...
INTO neue_Tabelle [IN externe Datenbank]
VON old_table
WHERE-Bedingung;
Können wir also eine Tabelle auswählen, wenn wir sie noch nicht mit SQL CREATE TABLE erstellt haben?
Logischerweise sollte die Antwort nein lauten. Dies ist jedoch nicht der Fall, und wir können in eine Tabelle auswählen, auch wenn wir sie noch nicht erstellt haben. Wenn eine Tabelle gebildet werden muss und Daten aus einer Tabelle in die neu erzeugte Tabelle übertragen werden müssen, wird dieser Ansatz verwendet. Die gleichen Datentypen wie die ausgewählten Spalten werden verwendet, um die neue Tabelle zu generieren.
Eine Produkttabelle in SQL kann auf verschiedene Arten erstellt werden. Die Verwendung der SQL-Anweisung CREATE TABLE ist eine Option. Die Produktinformationen sind in einer Tabelle enthalten, die diese Anweisung erstellt. Der SELECT-Befehl kann auch verwendet werden, um die Daten aus der Tabelle anzuzeigen und abzurufen. Die Syntax für beide wurde oben erwähnt.
Mit dem INSERT-Befehl können auch neue Daten in die Tabelle eingefügt werden. Dank der INSERT-Anweisung werden die Daten an der angegebenen Position in die Tabelle eingefügt. Die Daten können auch mit der SELECT-Abfrage aus der Tabelle genommen und dann mit der INSERT-Anweisung einer anderen Tabelle hinzugefügt werden.
EINFÜGEN IN
Wir verwenden die INSERT INTO-Anweisung, um neue Datensätze zu einer Tabelle hinzuzufügen. Die Syntax der INSERT-Anweisung lautet:
INSERT INTO Tabellenname (Spalte_1, Spalte_2, ...)
WERTE (Wert_1, Wert_2, ...);
Was einen Produkttisch anders macht, ist nur der Designaspekt desselben. Name, Modell, Klasse, Modelljahr und Listenpreis des Produkts werden alle in der Produktdatenbank gespeichert. Jeder Artikel ist Teil der Marke, die durch die Marken-ID-Spalte identifiziert wird. Folglich kann eine Marke ein Produkt oder viele haben. Jedes Produkt ist Mitglied einer Kategorie, die durch ihre Kategorie-ID in der Tabelle identifiziert wird.
Bei der Verwendung des SQL CREATE TABLE-Befehls müssen wir die Datentypen der Spalten erwähnen. Die Daten, die eine Spalte enthalten kann, hängen von diesem Datentyp ab. Beispiele sind Ganzzahl, Zeichen, Binär, Datum und Uhrzeit und mehr. Eine Datenbanktabelle muss für jede Spalte einen Namen sowie einen Datentyp haben.
Beim Erstellen einer Tabelle muss ein SQL-Programmierer bestimmen, welche Art von Daten in jeder Spalte enthalten sein werden. Der Datentyp gibt an, wie SQL mit den gespeicherten Daten kommuniziert. Es hilft bei der Bestimmung, welche Art von Daten in jeder Spalte erwartet wird. Die drei primären Datentypen in MySQL 8.0 sind Zeichenfolgen, Zahlen sowie Datum und Uhrzeit.
String-Datentypen
String-Datentypen sind im Allgemeinen eine Reihe von Zeichen, die zum englischen Alphabet gehören. Die wichtigsten String-Datentypen sind:
Dabei steht SIZE für die maximale Größe, die die gespeicherten Daten annehmen können. Ein CHAR ist eine Zeichenfolge mit fester Länge, während ein VARCHAR eine Zeichenfolge mit variabler Zeichenfolgenlänge ist. Dies sind die am häufigsten verwendeten String-Datentypen. Ein BLOB ist ein binäres großes Objekt.
Numerische Datentypen
Numerische Datentypvariablen werden verwendet, um numerische Daten zu speichern. Sie werden weiter in zwei Arten von Datentypen unterteilt - exakt und ungefähr. Exakte Datentypen werden verwendet, um den Datenwert in seiner wörtlichen Form zu halten. Während reelle Zahlen in ungefähren Datentypen enthalten sind, werden die Informationen nicht buchstäblich als Kopie der wahren Werte gespeichert. Die wichtigsten numerischen Datentypen sind:
Der am häufigsten verwendete numerische Datentyp ist INT . Es wird verwendet, um Nichtdezimalzahlen zu speichern, während Variablen mit dem Datentyp FLOAT verwendet werden, um Dezimalzahlen zu speichern. Beim Datentyp BOOL wird Null als FALSE betrachtet und Werte ungleich Null werden als TRUE betrachtet.
Datum (und Uhrzeit
Die Datums- und Zeitdatentypen werden verwendet, um Datumsdaten zu speichern. Die wichtigsten Datentypen für Datum und Uhrzeit sind:
Die Datentypen des SQL-Servers ähneln den oben angegebenen Datentypen, jedoch mit kleinen syntaktischen Unterschieden.
Im MS SQL-Server gibt es zwei Kategorien von Variablen:
Ein Benutzer deklariert eine lokale Variable. Es beginnt immer mit @. Der Gültigkeitsbereich jeder lokalen Variablen ist auf den Stapel oder Prozess beschränkt, der jetzt in einer bestimmten Sitzung ausgeführt wird. Eine lokale Transact-SQL-Variable ist eine Art Objekt, das nur eine bestimmte Art von Datenwert speichern kann. Skripte und Stapel verwenden häufig Variablen:
Das System behält die globale Variable bei. Benutzer können sie nicht öffentlich machen. @@ ist, wo die globale Variable beginnt. Es speichert Daten über Sitzungen.
Es wäre hilfreich, wenn Sie eine Variable definieren, bevor Sie sie in einem Stapel oder Prozess verwenden. Die Speicherort-Ersetzungsvariable wird mit dem DECLARE-Befehl deklariert. Eine Variable kann erst verwendet werden, nachdem sie im nachfolgenden Stapel- oder Verfahrensschritt deklariert wurde.
Die TSQL-Syntax zum Deklarieren einer Variablen sieht folgendermaßen aus:
DECLARE { @LOCAL_VARIABLE[AS] Datentyp [ = Wert ] }
Der Programmierer kann den Wert einer definierten Variablen auch bestimmen durch:
Der Datentyp gehört zu den wesentlichen Komponenten jeder Programmiersprache, sei es eine Programmiersprache wie C oder eine Datenbearbeitungssprache wie SQL. Tatsächlich unterstützt SQL über 30 Datentypen, die verschiedene Arten von tatsächlichen Daten speichern können. Am besten wäre es, wenn Sie sich mit den verschiedenen SQL-Datentypen vertraut gemacht hätten, bevor Sie mit dem Umgang mit Daten beginnen können.
Die Arten von Informationen, die in Datenbankobjekten wie Tabellen gespeichert werden können, werden durch SQL-Datentypen angegeben. Jede Spalte in einer Tabelle hat einen Namen und einen Datentyp, und jede Tabelle hat Spalten. Sie bilden das Rückgrat jeder Sprache, da Sie Daten nicht manipulieren können, ohne sie zu verwenden.
Sie sollten wissen, dass nicht alle Datentypen von Datenbanksystemen unterstützt werden. Daher müssen Sie dies überprüfen, bevor Sie einen bestimmten Datentyp verwenden. Beispielsweise können Sie DateTime in Oracle nicht verwenden, da es diesen Datentyp nicht zulässt.
Ebenso verwendet MySQL Unicode nicht als Datentyp. Sie können zusätzliche Datentypen verwenden, die bestimmte Datenbanken haben. Beispielsweise können „money“ und „smallmoney“ in Microsoft SQL Server „float“ und „real“ ersetzen, aber diese Begriffe sind datenbankspezifisch und in anderen Datenbanksystemen nicht vorhanden. Manchmal werden bestimmte Datentypen in einigen Datenbanken mit unterschiedlichen Namen bezeichnet. Oracle bezieht sich beispielsweise auf „Dezimal“ als „Zahl“ und „Blob“ als „Raw“.
Ja. In mehreren Tabellen kann der Primärschlüssel den gleichen Spaltennamen haben. Innerhalb einer Tabelle müssen Spaltennamen eindeutig sein. Da es die Integrität der Entitäten bestimmt, kann eine Tabelle nur einen Primärschlüssel enthalten. Jede Tabelle kann einen Primärschlüssel enthalten, muss es aber nicht. Dank der als Primärschlüssel bezeichneten Spalte oder Spalten dürfen keine zwei Zeilen denselben Primärschlüssel haben. Der Primärschlüssel einer Tabelle kann verwendet werden, um die Datensätze einer anderen Tabelle zu identifizieren und ein Teil des Primärschlüssels der zweiten Tabelle zu sein.
Der Befehl ORDER BY kann verwendet werden, um die Ergebnismenge zu sortieren. Dies kann in aufsteigender oder absteigender Reihenfolge erfolgen. Datensätze werden normalerweise mit dem Schlüsselwort ORDER BY in aufsteigender Reihenfolge sortiert. Mit dem Schlüsselwort DESC können Sie die Einträge in absteigender Reihenfolge anordnen.
Die Syntax der Bestellung sieht folgendermaßen aus:
SELECT Spalte_1, Spalte_2, ...
FROM Tabellenname
ORDER BY Spalte_1, Spalte_2, ... ASC|DESC;
Angenommen, es gibt eine Tabelle mit dem Namen Users; Sie können es basierend auf der Stadt der Benutzer in aufsteigender oder absteigender Reihenfolge sortieren.
AUSWÄHLEN * VON Benutzern
ORDER NACH Stadt;
Um dasselbe in absteigender Reihenfolge zu sortieren:
AUSWÄHLEN * VON Benutzern
ORDER BY City DESC;
Verwenden Sie einfach ORDER BY wie gewohnt auf den Namen des Primärschlüssels, z. B. "RollID":
SELECT * FROM my_table WHERE col_1 < 5 ORDER BY RollID;
Der Abfrageoptimierer entscheidet sich möglicherweise dafür, die Primärschlüsselindexstruktur zu verwenden, um die Sortierung zu analysieren, anstatt eine aktive Sortierung der Abfrageergebnismenge durchzuführen, um ORDER BY basierend auf seiner Entscheidung zur Bewertung der Abfrage zu behandeln.
Die Mehrheit der Einzeltabellenabfragen ohne eine ORDER BY-Klausel gibt Ergebnisse in der Reihenfolge des Primärschlüssels zurück, da MySQL InnoDB Tabellen in der Reihenfolge speichert, die der nativen Primärschlüsselreihenfolge entspricht. Sie können jedoch immer noch ORDER BY verwenden, wenn Ihre Anwendung wirklich eine Primärschlüsselreihenfolge erfordert.
Die No-Code-Entwicklungsmethodik ist einer der Hauptfaktoren, die die Demokratisierung des Programmierens fördern. Heutzutage haben mehr Menschen im Prinzip Zugang zu Computern, ohne irgendeine Codierung zu kennen. Es erleichtert die Erstellung responsiver Websites sowie mobiler Anwendungen.
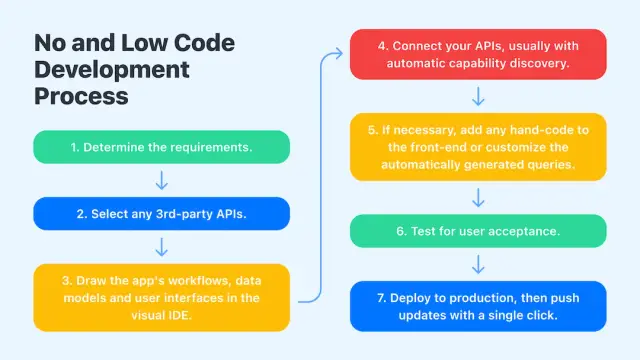
AppMaster kann Ihnen dabei helfen, Quellcode automatisch zu generieren. Der Code steht Ihnen jederzeit zur Ansicht und Prüfung zur Verfügung. Sie haben die Möglichkeit, Projektdetails mithilfe einer Programmiersprache mit AppMaster zu ändern. Wir geben Benutzern auch die Möglichkeit, den Code zu exportieren. Dies ist ein Versprechen, dass die Software, die Sie mit AppMaster entwickeln, vollständig in Ihrer Kontrolle und Ihrem Eigentum liegt.
SQL hat mehrere Anwendungen, die es sehr attraktiv machen. Das Erstellen von Datenintegrationsskripten, das Entwerfen und Ausführen analytischer Abfragen und der Zugriff auf Teilmengen von Daten aus einer Datenbank für Einblicke und Transaktionsverarbeitung sind einige der wichtigsten Zwecke. Es kann auch zum Einfügen, Ändern und Entfernen von Datenzeilen und -spalten in einer Datenbank verwendet werden.
Bevor wir in die Tiefen von SQL einsteigen, müssen wir uns mit den grundlegenden Befehlen und der Syntax vertraut machen. Indem wir den obigen Artikel durchgehen, können wir mehr über die grundlegenden Anweisungen erfahren, die in SQL verwendet werden, wie CREATE TABLE, INSERT INTO, SELECT und mehr.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


