
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
SQL でコーディングするときに最初に知っておくべきことは、create table ステートメントです。テーブルを作成する際に知っておくべきことはすべてここにあります。

SQL は、エンジニアがリレーショナル データベースに格納されたデータを処理したり、リレーショナル データ ストリーム管理システムでストリーム処理を行うために使用するドメイン固有の言語です。テーブルを介して リレーショナル データベース にデータを格納できます。このプロセスで最初に行うことは、作業対象のデータベースを作成することです。次に、実際のデータが格納されるテーブルを作成します。このようなデータベースのテーブルには、行と列の両方があります。
各列には、格納できるデータの種類を決定する特定のデータ型が関連付けられています。テーブルの作成中に、各列の名前とデータ型を指定する必要があります。 MySQL データベースと PostgreSQL データベースの両方で、SQL CREATE TABLE コマンドを使用してテーブルを作成できます。
CREATE TABLE SQL ステートメントを詳しく見てみましょう。
次の構文を使用して、MySQL でテーブルを作成できます。
CREATE TABLE テーブル名(
column_1 data_type デフォルト値 column_constraint ,
column_2 data_type デフォルト値 column_constraint ,
...、
…、
table_constraint
);
テーブルを作成する際に必要な基本的なものは、その名前と少なくとも 1 つの列名です。特定 のテーブル名 を持つデータベース テーブルは 1 つだけ存在する必要があります。同じ名前のテーブルを 2 つ作成しようとすると、データベースからエラー メッセージが表示されます。
括弧内に、テーブルに作成する列の名前と、そこに入力されるデータのデータ型を指定します。これらの列の名前はコンマで区切られます。列の名前、データ型、デフォルト値、および 1 つ以上の列制限によって、各列が構成されます。
列の制約は、列に格納できる実際のデータ値を制御します。たとえば、 NOT NULL 制約は、その特定の列に NULL 値が存在しないことを保証します。 1 つの列に対して複数の制約を設定できます。たとえば、列には NOT NULL と UNIQUE の両方の制限を含めることができます。
テーブル内のすべての列に制約を適用する場合は、テーブル制約を使用できます。同じ例として、 FOREIGN KEY 、 CHECK 、および UNIQUE があります。各テーブルは、1 つまたは複数の列で構成される主キーを持つことができます。この主キーは、テーブルの各レコードを一意に識別するために使用されます。通常、最初に主キー列をリストし、次に他の列をリストします。 PRIMARY KEY 制約が 2 つ以上の列で構成される場合は、テーブル制約として宣言する必要があります。
例を見てみましょう:
テーブルの顧客を作成する(
ID INT NOT NULL、
NAME VARCHAR (20) NOT NULL,
年齢INT NOT NULL、
給与小数 (18, 2),
主キー (ID)
);
ここでは、テーブルの名前は「CUSTOMERS」で、主キーは ID です。 ID、NAME、および AGE 列には、 NOT NULL の制約があります。名前の長さは 20 文字未満にする必要があります。これで、SQL CREATE TABLE コマンドを使用してテーブルが作成され、関連データをそのテーブルとデータベースに挿入できます。
テーブル内にテーブルを持つことは、テーブルのネストと呼ばれます。このためには、SQL CREATE TABLE コマンドを使用して、別のテーブル内にテーブルを作成する必要があります。これは MySQL には存在しない概念です。ただし、主キーと外部キーを使用することで、ネストしたテーブルと同じ結果を得ることができます。これにより、2 つのテーブル間に親子関係が作成されます。
別のテーブルの PRIMARY KEY を参照する 1 つのテーブル内のフィールドまたはフィールドのグループは、 FOREIGN KEY と呼ばれます。メイン主キーを持つテーブルは親テーブルと呼ばれ、外部キーを持つテーブルは子テーブルと呼ばれます。
たとえば、主キーが VehId である親テーブル Vehicle があるとします。さらに 2 つのテーブルがあります。主キー CarId を持つ Car と主キー TruckId を持つ Truck です。 Car と Truck の両方に VehId を外部キーとして配置すると、Vehicle が親テーブルになり、親子関係が作成されます。
親テーブル 車両 {VehId}
子テーブル
1. 車 {VehId,CarId}
2. トラック {VehId,TruckId}
最初に作成せずに SQL テーブルを選択することは可能ですか?
データベースからデータを選択するには、SELECT ステートメントを使用します。ここからのデータは、結果セットと呼ばれる結果テーブルに保持されます。これは、テーブルの一部またはテーブル全体を選択するために使用されます。コーディング中に SQL CREATE TABLE コマンドを使用してテーブルを作成した場合、SELECT コマンドを使用して、作成したテーブルを表示できます。
その構文は次のようになります。
列_1、列_2、…を選択
FROM テーブル名;
たとえば、次のコマンドはテーブル全体を選択します。
SELECT * FROM テーブル名;
に選択
SELECT INTO ステートメントを使用して、あるテーブルのデータを別のテーブルに転送します。あるテーブルのすべての列を別のテーブルにコピーできます。これは通常、データのコピー先のテーブルが既に存在する場合に使用されます。
テーブルのすべての列を選択するには:
選択する *
INTO new_table [IN externaldb]
FROM old_table
WHERE 条件;
新しいテーブルにいくつかの列のみを選択するには:
SELECT column_1、column_2、column_3、...
INTO new_table [IN externaldb]
FROM old_table
WHERE 条件;
では、SQL CREATE TABLE でまだテーブルを作成していない場合、テーブルを選択できますか?
論理的には、答えはノーであるべきです。しかし、これは当てはまりません。テーブルをまだ作成していなくても、テーブルを選択できます。テーブルを形成する必要があり、あるテーブルのデータを新しく生成されたテーブルに転送する必要がある場合、このアプローチが利用されます。選択した列と同じデータ型を使用して、新しいテーブルが生成されます。
SQL の製品テーブルは、さまざまな方法で作成できます。 SQL CREATE TABLE ステートメントを使用することも 1 つのオプションです。製品情報は、このステートメントが作成するテーブルに含まれます。 SELECT コマンドを使用して、テーブルからデータを表示および取得することもできます。これらの両方の構文は上記で説明されています。
INSERT コマンドを使用して、新しいデータをテーブルに挿入することもできます。 INSERT ステートメントのおかげで、データは指定された位置のテーブルに挿入されます。データは、SELECT クエリを使用してテーブルから取り出し、INSERT ステートメントを使用して別のテーブルに追加することもできます。
に挿入
INSERT INTO ステートメントを使用して、新しいレコードをテーブルに追加します。 INSERT ステートメントの構文は次のとおりです。
INSERT INTO テーブル名 (列 1、列 2、...)
値 (値_1、値_2、...);
製品テーブルの違いは、デザイン面のみです。製品の名前、モデル、クラス、モデルの年、および定価はすべて製品データベースに保存されます。すべてのアイテムは、ブランド ID 列で識別されるブランドの一部です。したがって、ブランドは 1 つまたは複数の製品を持つことができます。各製品は、テーブル内のカテゴリ ID によって識別されるカテゴリのメンバーです。
SQL CREATE TABLE コマンドを使用するときは、列のデータ型について言及する必要があります。列に含めることができるデータは、このデータ型によって異なります。例には、整数、文字、バイナリ、日付と時刻などが含まれます。データベース テーブルには、すべての列の名前とデータ型が必要です。
テーブルを作成するとき、SQL プログラマーは、各列に含まれるデータの種類を決定する必要があります。データ型は、SQL が格納されたデータとどのようにやり取りするかを指定します。各列内で予想されるデータの種類を判断するのに役立ちます。 MySQL 8.0 の 3 つの主要なデータ型は、文字列、数値、および日付と時刻です。
文字列データ型
文字列データ型は、通常、英語のアルファベットに属する一連の文字です。主な文字列データ型は次のとおりです。
ここで、 SIZE は、格納されたデータが取り得る最大サイズを表します。 CHAR は固定長の文字列ですが、 VARCHAR は可変長の文字列です。これらは、最もよく使用される文字列データ型です。 BLOB はバイナリ ラージ オブジェクトです。
数値データ型
数値データ型変数は、数値データを保持するために使用されます。それらはさらに、正確なデータ型と近似的なデータ型の 2 種類に分類されます。正確なデータ型は、データ値をリテラル形式で保持するために使用されます。実数は近似データ型に含まれていますが、情報は実際の値のコピーとして文字通り保存されるわけではありません。主な数値データ型は次のとおりです。
最も一般的に使用される数値データ型は INT です。非 10 進数を保持するために使用されますが、データ型が FLOAT の変数は 10 進数を保持するために使用されます。 BOOL データ型では、ゼロは FALSE と見なされ、ゼロ以外の値は TRUE と見なされます。
日時
日付と時刻のデータ型は、日付データを保持するために使用されます。主な日付と時刻のデータ型は次のとおりです。
SQL サーバーのデータ型は上記のデータ型に似ていますが、構文が少し異なります。
MS SQL サーバーには、次の 2 つのカテゴリの変数が存在します。
ユーザーがローカル変数を宣言します。常に @ で始まります。各ローカル変数のスコープは、特定のセッション内で現在実行されているバッチまたはプロセスに制限されます。 Transact-SQL ローカル変数は、特定の 1 種類のデータ値のみを格納できる一種のオブジェクトです。スクリプトとバッチは変数を頻繁に使用します。
システムはグローバル変数を維持します。ユーザーはそれらを公開できません。 @@ は、グローバル変数が始まる場所です。セッションに関するデータを保持します。
バッチまたはプロセスで使用する前に変数を定義しておくと役立ちます。メモリ位置置換変数は、DECLARE コマンドを使用して宣言されます。変数は、後続のバッチまたはプロシージャ ステップで宣言された後にのみ使用できます。
変数を宣言する TSQL 構文は次のようになります。
DECLARE { @LOCAL_VARIABLE[AS] データ型 [ = 値 ] }
プログラマーは、次の方法で定義済み変数の値を決定することもできます。
データ型は、C などのプログラミング言語であろうと、SQL などのデータ操作言語であろうと、コーディング言語の重要なコンポーネントの 1 つです。実際、SQL は、さまざまな形式の実際のデータを格納できる 30 を超えるデータ型をサポートしています。データの処理を開始する前に、さまざまな SQL データ型をしっかりと把握しておくことをお勧めします。
テーブルなどのデータベース オブジェクトに保持できる情報の種類は、SQL データ型によって指定されます。テーブルのすべての列には名前とデータ型があり、すべてのテーブルには列があります。それらを使用せずにデータを操作することはできないため、それらはあらゆる言語のバックボーンを形成します。
すべてのデータ型がデータベース システムでサポートされているわけではないことに注意してください。したがって、特定のデータ型を使用する前に確認する必要があります。たとえば、このデータ型が許可されていないため、Oracle で DateTime を使用することはできません。
同様に、MySQL はデータ型として Unicode を使用しません。特定のデータベースが持つ追加のデータ型を使用できます。たとえば、Microsoft SQL Server の「money」と「smallmoney」は「float」と「real」の代わりに使用できますが、これらの用語はデータベース固有のものであり、他のデータベース システムには存在しません。一部のデータベースでは、特定のデータ型がさまざまな名前で参照されることがあります。たとえば、Oracle では、「10 進数」を「数値」と呼び、「ブロブ」を「生」と呼びます。
はい。いくつかのテーブルでは、主キーが同じ列名を共有できます。テーブル内では、列名は区別する必要があります。エンティティの整合性を決定するため、テーブルには主キーを 1 つだけ含めることができます。すべてのテーブルには主キーが含まれる場合がありますが、必須ではありません。 1 つまたは複数の列が主キーとして指定されているため、2 つの行が同じ主キーを共有することはありません。 1 つのテーブルの主キーを使用して、別のテーブルのレコードを識別し、2 番目のテーブルの主キーの一部にすることができます。
ORDER BY コマンドを使用して、ソートされた結果セットを取得できます。これは、昇順または降順のいずれかです。通常、レコードは ORDER BY キーワードを使用して昇順に並べ替えられます。 DESC キーワードを使用して、エントリを降順に並べ替えることができます。
order の構文は次のようになります。
SELECT column_1、column_2、...
FROM テーブル名
ORDER BY column_1、column_2、... ASC|DESC;
たとえば、Users というテーブルがあるとします。ユーザーの都市に基づいて、昇順または降順で並べ替えることができます。
SELECT * FROM ユーザー
ORDER BY 都市;
同じものを降順で並べ替えるには:
SELECT * FROM ユーザー
市区町村で注文 DESC;
「RollID」など、主キーの名前に通常どおり ORDER BY を使用するだけです。
SELECT * FROM my_table WHERE col_1 < 5 ORDER BY RollID;
クエリ オプティマイザーは、クエリの評価方法に基づいて、クエリ結果セットに対してアクティブな並べ替えを実行するのではなく、主キー インデックス構造を使用して並べ替えを分析することを決定する場合としない場合があります。
ORDER BY 句のない単一テーブル クエリの大部分は、プライマリ キーの順序で結果を返します。これは、MySQL InnoDB がネイティブのプライマリ キーの順序に近い方法でテーブルを格納するためです。ただし、アプリケーションで本当に主キーの順序付けが必要な場合は、ORDER BY を利用できます。
ノーコード開発 方法論は、コーディングの民主化を促進する主な要因の 1 つです。最近では、コーディングをまったく知らなくても、原則としてコンピューティングにアクセスできる人が増えています。レスポンシブ Web サイトやモバイル アプリケーションの構築を容易にします。
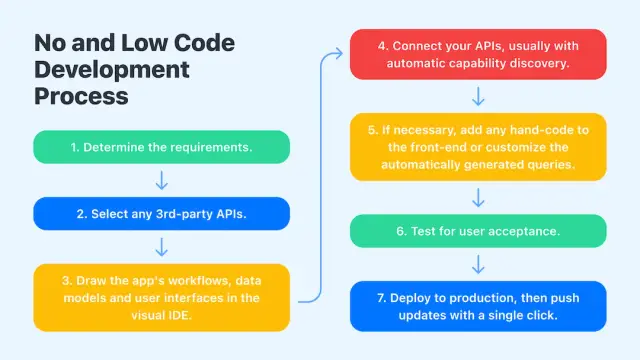
AppMaster は、ソース コードを自動的に生成するのに役立ちます。コードはいつでも表示して調べることができます。 AppMaster でプログラミング言語を使用して、プロジェクトの詳細を変更することができます。また、コードをエクスポートするオプションも提供しています。これは、AppMaster で開発しているソフトウェアが完全にあなたの管理と所有権の範囲内にあるという約束です。
SQL には、非常に魅力的なアプリケーションがいくつかあります。データ統合スクリプトの作成、分析クエリの設計と実行、洞察とトランザクション処理のためのデータベースからのデータのサブセットへのアクセスは、その最も顕著な目的の一部です。また、データベース内のデータの行と列の挿入、変更、および削除にも使用できます。
SQL の詳細に入る前に、その基本的なコマンドと構文に慣れる必要があります。上記の記事を読むことで、CREATE TABLE、INSERT INTO、SELECT など、SQL で使用される基本的なステートメントについて詳しく知ることができます。




