Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj różnice między relacyjnymi i nierelacyjnymi bazami danych. Poznaj ich zalety, ograniczenia i idealne przypadki użycia, aby pomóc Ci wybrać najlepszy model bazy danych dla Twojej aplikacji.

Relacyjna baza danych to system zarządzania bazami danych (DBMS) zaprojektowany do przechowywania ustrukturyzowanych danych i zarządzania nimi przy użyciu schematu definiującego typy danych, relacje i ograniczenia między tabelami. Relacyjne bazy danych opierają się na modelu relacyjnym, koncepcji wprowadzonej w 1970 roku przez Edgara F. Codda, informatyka w IBM. W tym modelu dane są zorganizowane w tabele z kolumnami i wierszami, gdzie każdy wiersz reprezentuje rekord danych, a każda kolumna odpowiada atrybutowi danych.
Relacyjne bazy danych zaprojektowano w celu utrzymania spójności i integralności danych oraz egzekwowania relacji i ograniczeń między różnymi tabelami. Opierają się na Structured Query Language (SQL) do wykonywania zapytań, manipulacji i organizacji danych. SQL to potężny i powszechnie stosowany język zapytań, umożliwiający użytkownikom łatwe wykonywanie złożonych operacji na danych.
Niektóre popularne relacyjne bazy danych to MySQL, PostgreSQL , Oracle i Microsoft SQL Server. Są one najczęściej wybieranym wyborem w przypadku wielu zastosowań, szczególnie tych z dobrze zdefiniowanymi strukturami i relacjami danych, które wymagają spójnego i dokładnego przechowywania danych.
Relacyjne bazy danych mają kilka zalet, dzięki czemu są popularne w różnych zastosowaniach. Do najważniejszych korzyści należą:
Pomimo licznych zalet, relacyjne bazy danych mają również pewne ograniczenia, które należy wziąć pod uwagę przed wyborem ich do swojej aplikacji. Niektóre z tych ograniczeń obejmują:
W kolejnych sekcjach omówimy nierelacyjne bazy danych, ich zalety, ograniczenia oraz porównanie relacyjnych i nierelacyjnych baz danych, aby pomóc Ci podjąć świadomą decyzję dotyczącą Twojej aplikacji.
Nierelacyjne bazy danych, zwane także bazami NoSQL (Not Only SQL) , stanowią alternatywę dla tradycyjnych relacyjnych baz danych. Te bazy danych są przeznaczone do przechowywania danych w formatach innych niż tabele i zapewniają prostsze, bardziej elastyczne i skalowalne rozwiązanie do przechowywania i zarządzania danymi nieustrukturyzowanymi lub częściowo ustrukturyzowanymi. Nierelacyjne bazy danych mogą obsługiwać dane w różnych formatach, takich jak para klucz-wartość, rodzina kolumn, dokument i wykres.
Niektóre powszechnie używane nierelacyjne bazy danych obejmują MongoDB (oparte na dokumentach), Cassandra (rodzina kolumn), Redis (klucz-wartość) i Neo4j (wykres). Te bazy danych mają różne funkcje, architektury i możliwości, ale wszystkie mają pewne wspólne cechy, które odróżniają je od relacyjnych baz danych. Oni zazwyczaj:
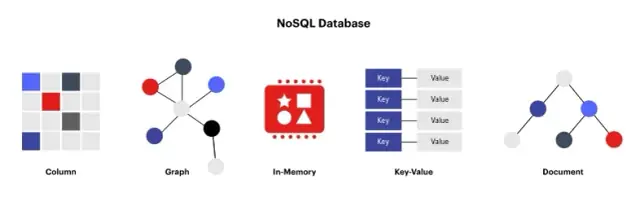
Źródło obrazu: redis.com
Nierelacyjne bazy danych mają kilka zalet w porównaniu ze swoimi relacyjnymi odpowiednikami, co czyni je atrakcyjną opcją dla nowoczesnych aplikacji zajmujących się danymi nieustrukturyzowanymi lub częściowo ustrukturyzowanymi, dużym natężeniem ruchu i szybkimi operacjami odczytu/zapisu. Niektóre z tych korzyści obejmują:
Pomimo swoich zalet, nierelacyjne bazy danych mają również pewne ograniczenia w porównaniu z relacyjnymi bazami danych. Niektóre z tych wad obejmują:
Decydując się pomiędzy relacyjnymi i nierelacyjnymi bazami danych dla swojej aplikacji, istotne jest zrozumienie kluczowych różnic pomiędzy tymi dwoma modelami. Oto krótkie porównanie ich właściwości:
Relacyjne bazy danych służą do przechowywania ustrukturyzowanych danych w tabelach z predefiniowanymi relacjami. Wymagają stałego schematu, który określa typy danych, strukturę tabeli i relacje między tabelami. Z drugiej strony nierelacyjne bazy danych mogą przechowywać dane nieustrukturyzowane lub częściowo ustrukturyzowane w różnych formatach, takich jak para klucz-wartość, dokument, rodzina kolumn i wykres. Są bardziej elastyczni w obsłudze danych bez ustalonego schematu.
Relacyjne bazy danych korzystają ze strukturalnego języka zapytań (SQL) do manipulacji i wyszukiwania danych. SQL to potężny i powszechnie używany język, który umożliwia tworzenie złożonych zapytań. Nierelacyjne bazy danych używają różnych języków zapytań w zależności od ich struktury danych. Na przykład MongoDB używa zapytań BSON (Binary JSON), podczas gdy Cassandra używa CQL (Cassandra Query Language).
Relacyjne bazy danych wymuszają spójność i integralność za pomocą właściwości ACID (atomowość, spójność, izolacja, trwałość), zapewniając niezawodne przetwarzanie transakcji i spójność danych. W nierelacyjnych bazach danych zazwyczaj priorytetem jest wydajność i skalowalność, a nie ścisła spójność i integralność. W zależności od typu bazy danych NoSQL mogą zapewniać różne poziomy spójności poprzez ostateczne modele spójności lub dostrajalne poziomy spójności.
Relacyjne bazy danych skupiają się na skalowaniu wertykalnym, co wymaga dodania zasobów (takich jak procesor, pamięć i pamięć masowa) do pojedynczego serwera. Takie podejście może być ograniczające w przypadku dużych ilości danych i aplikacji o dużej przepustowości. Nierelacyjne bazy danych są zaprojektowane do skalowania poziomego, umożliwiając dystrybucję danych i obciążenia na wielu serwerach. Takie podejście poprawia wydajność i skalowalność w przypadku ogromnych zbiorów danych i dużych obciążeń odczytu/zapisu.
Aby wybrać pomiędzy relacyjną i nierelacyjną bazą danych, należy wziąć pod uwagę następujące kryteria w oparciu o wymagania aplikacji:
Wybór pomiędzy relacyjnymi i nierelacyjnymi bazami danych odnosi się do konkretnych wymagań i rozważań aplikacji. Warto również zauważyć, że niektóre aplikacje wykorzystują podejścia hybrydowe, w których wykorzystują zarówno relacyjne, jak i nierelacyjne bazy danych, aby wykorzystać zalety obu modeli.
Tworząc aplikacje przy użyciu 's bez kodu AppMaster , możesz wybierać pomiędzy relacyjnymi i nierelacyjnymi bazami danych, w zależności od Twoich wymagań. AppMaster zapewnia bezproblemową integrację baz danych, ułatwiając tworzenie aplikacji internetowych, mobilnych i backendowych, które działają z dowolną bazą danych kompatybilną z Postgresql jako podstawową bazą danych.
Niezależnie od rodzaju bazy danych, którą wybierzesz, AppMaster oferuje zaawansowane funkcje, które obejmują tworzenie wizualnych modeli danych na potrzeby projektowania schematów, projektowanie procesów biznesowych, obsługę interfejsu API REST i wbudowaną kompatybilność z różnymi bazami danych. Wykorzystując możliwości AppMaster, możesz tworzyć aplikacje do 10 razy szybciej i 3 razy taniej niż tradycyjne metody tworzenia oprogramowania.
Wybór odpowiedniego modelu bazy danych ma kluczowe znaczenie dla rozwoju aplikacji. Dokładnie oceń zalety i ograniczenia relacyjnych i nierelacyjnych baz danych, rozważ potrzeby aplikacji i wybierz typ, który najlepiej pasuje do Twoich przypadków użycia. Mając do dyspozycji AppMaster, możesz budować wydajne i skalowalne aplikacje, które skutecznie spełnią Twoje wymagania biznesowe.
Relacyjne bazy danych zaprojektowano do przechowywania danych strukturalnych i zarządzania nimi przy użyciu schematu definiującego typy danych, relacje i ograniczenia między tabelami. Opierają się na modelu relacyjnym i wykorzystują SQL do odpytywania danych.
Nierelacyjne bazy danych, zwane także bazami danych NoSQL, przechowują dane w formatach innych niż tabele ze zdefiniowanymi relacjami. Są przeznaczone do obsługi danych nieustrukturyzowanych lub częściowo ustrukturyzowanych i wykorzystują języki zapytań inne niż SQL.
Relacyjne bazy danych oferują takie korzyści, jak spójność i integralność danych oraz możliwość obsługi złożonych zapytań przy użyciu języka SQL. Są szeroko stosowane w aplikacjach z danymi strukturalnymi i dobrze zdefiniowanymi relacjami.
Nierelacyjne bazy danych zapewniają wysoką skalowalność, elastyczność i wydajność podczas pracy z dużymi ilościami danych nieustrukturyzowanych lub częściowo ustrukturyzowanych. Nadają się do zastosowań wymagających szybkich operacji odczytu/zapisu i skalowania poziomego.
Relacyjne bazy danych mogą mieć ograniczenia pod względem skalowalności, szczególnie w przypadku dużych zbiorów danych. Mogą być mniej elastyczne w obsłudze danych nieustrukturyzowanych i mogą wymagać więcej zasobów do zarządzania złożonymi relacjami i zapytaniami.
W nierelacyjnych bazach danych może brakować niektórych funkcji, takich jak właściwości ACID i złożone możliwości wykonywania zapytań oferowane przez relacyjne bazy danych. Mogą również mieć różną obsługę spójności i integralności danych, w zależności od konkretnego typu bazy danych NoSQL.
Wybierając bazę danych, należy wziąć pod uwagę takie czynniki, jak struktura danych, złożoność zapytań, skalowalność, wydajność i wymagania aplikacji. Oceń zalety i wady każdego typu, aby określić najlepsze dopasowanie do konkretnego przypadku użycia.
Platforma AppMaster no-code umożliwia łatwą integrację zarówno relacyjnych, jak i nierelacyjnych baz danych, zapewniając elastyczność w tworzeniu aplikacji internetowych, mobilnych i backendowych, które mogą współpracować z dowolną bazą danych kompatybilną z Postgresql jako podstawową bazą danych.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


