उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
संबंधपरक और गैर-संबंधपरक डेटाबेस के बीच अंतर का अन्वेषण करें। अपने एप्लिकेशन के लिए सर्वश्रेष्ठ डेटाबेस मॉडल चुनने में मदद के लिए उनके संबंधित फायदे, सीमाएं और आदर्श उपयोग के मामलों को जानें।

रिलेशनल डेटाबेस एक डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) है जिसे एक स्कीमा का उपयोग करके संरचित डेटा को संग्रहीत और प्रबंधित करने के लिए डिज़ाइन किया गया है जो तालिकाओं के बीच डेटा प्रकार, संबंधों और बाधाओं को परिभाषित करता है। रिलेशनल डेटाबेस रिलेशनल मॉडल पर आधारित होते हैं, यह अवधारणा 1970 में आईबीएम के कंप्यूटर वैज्ञानिक एडगर एफ. कॉड द्वारा पेश की गई थी। इस मॉडल में, डेटा को कॉलम और पंक्तियों के साथ तालिकाओं में व्यवस्थित किया जाता है, जहां प्रत्येक पंक्ति एक डेटा रिकॉर्ड का प्रतिनिधित्व करती है और प्रत्येक कॉलम डेटा की एक विशेषता से मेल खाती है।
रिलेशनल डेटाबेस को डेटा स्थिरता, अखंडता बनाए रखने और विभिन्न तालिकाओं के बीच संबंधों और बाधाओं को लागू करने के लिए डिज़ाइन किया गया है। वे डेटा क्वेरी, हेरफेर और संगठन के लिए स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) पर भरोसा करते हैं। SQL एक शक्तिशाली और व्यापक रूप से अपनाई जाने वाली क्वेरी भाषा है, जो उपयोगकर्ताओं को डेटा पर जटिल ऑपरेशन आसानी से चलाने की अनुमति देती है।
कुछ लोकप्रिय रिलेशनल डेटाबेस में MySQL, PostgreSQL , Oracle और Microsoft SQL सर्वर शामिल हैं। वे कई अनुप्रयोगों के लिए पसंदीदा विकल्प रहे हैं, विशेष रूप से अच्छी तरह से परिभाषित डेटा संरचनाओं और रिश्तों वाले जिनके लिए लगातार और सटीक डेटा भंडारण की आवश्यकता होती है।
रिलेशनल डेटाबेस कई लाभ प्रदान करते हैं, जो उन्हें विभिन्न अनुप्रयोगों के लिए लोकप्रिय बनाते हैं। कुछ सबसे महत्वपूर्ण लाभों में शामिल हैं:
कई फायदों के बावजूद, रिलेशनल डेटाबेस की भी कुछ सीमाएँ हैं जिन पर आपको अपने एप्लिकेशन के लिए चयन करने से पहले विचार करना होगा। इनमें से कुछ सीमाओं में शामिल हैं:
अगले अनुभागों में, हम आपके आवेदन के लिए एक सूचित निर्णय लेने में मदद करने के लिए गैर-संबंधपरक डेटाबेस, उनके फायदे, सीमाओं और संबंधपरक और गैर-संबंधपरक डेटाबेस के बीच तुलना पर चर्चा करेंगे।
गैर-संबंधपरक डेटाबेस, जिन्हें NoSQL (न केवल SQL) डेटाबेस के रूप में भी जाना जाता है, पारंपरिक संबंधपरक डेटाबेस का एक विकल्प हैं। ये डेटाबेस डेटा को तालिकाओं के अलावा अन्य प्रारूपों में संग्रहीत करने और असंरचित या अर्ध-संरचित डेटा को संग्रहीत और प्रबंधित करने के लिए एक सरल, अधिक लचीला और स्केलेबल समाधान प्रदान करने के लिए डिज़ाइन किए गए हैं। गैर-संबंधपरक डेटाबेस कुंजी-मूल्य, कॉलम-परिवार, दस्तावेज़ और ग्राफ़ जैसे विभिन्न स्वरूपों में डेटा को संभाल सकते हैं।
कुछ व्यापक रूप से उपयोग किए जाने वाले गैर-संबंधपरक डेटाबेस में MongoDB (दस्तावेज़-आधारित), कैसेंड्रा (कॉलम-परिवार), रेडिस (कुंजी-मूल्य), और Neo4j (ग्राफ़) शामिल हैं। ये डेटाबेस विभिन्न विशेषताओं, आर्किटेक्चर और क्षमताओं के साथ आते हैं, लेकिन वे सभी कुछ सामान्य विशेषताओं को साझा करते हैं जो उन्हें रिलेशनल डेटाबेस से अलग करते हैं। वॆ अक्सर:
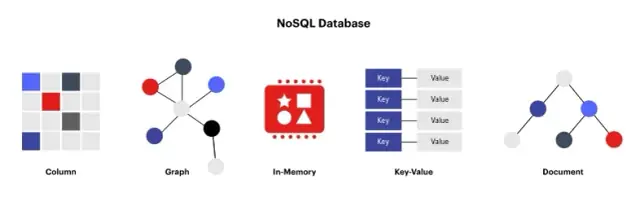
छवि स्रोत: redis.com
गैर-संबंधपरक डेटाबेस अपने संबंधपरक समकक्षों की तुलना में कई फायदे प्रदान करते हैं, जो उन्हें असंरचित या अर्ध-संरचित डेटा, उच्च ट्रैफ़िक वॉल्यूम और तेज़ पढ़ने/लिखने के संचालन से निपटने वाले आधुनिक अनुप्रयोगों के लिए एक आकर्षक विकल्प बनाते हैं। इनमें से कुछ लाभों में शामिल हैं:
अपने फायदों के बावजूद, गैर-संबंधपरक डेटाबेस की भी संबंधपरक डेटाबेस की तुलना में कुछ सीमाएँ होती हैं। इनमें से कुछ कमियों में शामिल हैं:
अपने एप्लिकेशन के लिए संबंधपरक और गैर-संबंधपरक डेटाबेस के बीच निर्णय लेते समय, दोनों मॉडलों के बीच मुख्य अंतर को समझना आवश्यक है। यहां उनकी विशेषताओं की संक्षिप्त तुलना दी गई है:
रिलेशनल डेटाबेस को पूर्वनिर्धारित संबंधों के साथ तालिकाओं में संरचित डेटा को संग्रहीत करने के लिए डिज़ाइन किया गया है। उन्हें एक निश्चित स्कीमा की आवश्यकता होती है जो डेटा प्रकार, तालिका संरचना और तालिकाओं के बीच संबंध निर्धारित करती है। दूसरी ओर, गैर-संबंधपरक डेटाबेस, कुंजी-मूल्य, दस्तावेज़, कॉलम-परिवार और ग्राफ़ जैसे विभिन्न स्वरूपों में असंरचित या अर्ध-संरचित डेटा संग्रहीत कर सकते हैं। वे किसी निश्चित स्कीमा के बिना डेटा को संभालने में अधिक लचीले होते हैं।
रिलेशनल डेटाबेस डेटा हेरफेर और पुनर्प्राप्ति के लिए स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) का उपयोग करते हैं। SQL एक शक्तिशाली और व्यापक रूप से उपयोग की जाने वाली भाषा है जो जटिल क्वेरी क्षमताओं को सक्षम बनाती है। गैर-संबंधपरक डेटाबेस अपनी डेटा संरचना के आधार पर विभिन्न क्वेरी भाषाओं का उपयोग करते हैं। उदाहरण के लिए, MongoDB BSON (बाइनरी JSON) क्वेरी का उपयोग करता है, जबकि Cassandra CQL (कैसंड्रा क्वेरी लैंग्वेज) का उपयोग करता है।
रिलेशनल डेटाबेस ACID (एटोमिसिटी, कंसिस्टेंसी, आइसोलेशन, ड्यूरेबिलिटी) गुणों का उपयोग करके स्थिरता और अखंडता को लागू करते हैं, यह सुनिश्चित करते हैं कि लेनदेन विश्वसनीय रूप से संसाधित होते हैं और डेटा सुसंगत रहता है। गैर-संबंधपरक डेटाबेस आमतौर पर सख्त स्थिरता और अखंडता पर प्रदर्शन और स्केलेबिलिटी को प्राथमिकता देते हैं। NoSQL डेटाबेस प्रकार के आधार पर, वे अंतिम स्थिरता मॉडल या ट्यून करने योग्य स्थिरता स्तरों के माध्यम से स्थिरता के विभिन्न स्तर प्रदान कर सकते हैं।
रिलेशनल डेटाबेस वर्टिकल स्केलिंग पर ध्यान केंद्रित करते हैं, जिसके लिए एकल सर्वर में संसाधन (जैसे सीपीयू, मेमोरी और स्टोरेज) जोड़ने की आवश्यकता होती है। बड़ी मात्रा में डेटा और उच्च-थ्रूपुट अनुप्रयोगों से निपटने के दौरान यह दृष्टिकोण सीमित हो सकता है। गैर-संबंधपरक डेटाबेस क्षैतिज स्केलिंग के लिए डिज़ाइन किए गए हैं, जो कई सर्वरों पर डेटा और लोड के वितरण को सक्षम करते हैं। बड़े पैमाने पर डेटासेट और उच्च पढ़ने/लिखने के कार्यभार से निपटने के दौरान यह दृष्टिकोण प्रदर्शन और स्केलेबिलिटी में सुधार करता है।
संबंधपरक और गैर-संबंधपरक डेटाबेस के बीच चयन करने के लिए, अपने एप्लिकेशन की आवश्यकताओं के आधार पर निम्नलिखित मानदंडों पर विचार करें:
संबंधपरक और गैर-संबंधपरक डेटाबेस के बीच चयन करना आपके एप्लिकेशन की विशिष्ट आवश्यकताओं और विचारों को संदर्भित करता है। यह भी ध्यान देने योग्य है कि कुछ एप्लिकेशन हाइब्रिड दृष्टिकोण का उपयोग करते हैं, जहां वे दोनों मॉडलों के लाभों का लाभ उठाने के लिए संबंधपरक और गैर-संबंधपरक दोनों डेटाबेस का उपयोग करते हैं।
AppMaster's नो-कोड प्लेटफ़ॉर्म का उपयोग करके एप्लिकेशन विकसित करते समय, आप अपनी आवश्यकताओं के आधार पर रिलेशनल और नॉन-रिलेशनल डेटाबेस के बीच चयन कर सकते हैं। AppMaster निर्बाध डेटाबेस एकीकरण क्षमताएं प्रदान करता है, जिससे वेब, मोबाइल और बैकएंड एप्लिकेशन बनाना आसान हो जाता है जो प्राथमिक डेटाबेस के रूप में किसी भी पोस्टग्रेस्क्ल-संगत डेटाबेस के साथ काम करते हैं।
आपके द्वारा चुने गए डेटाबेस के प्रकार के बावजूद, AppMaster आपको इसकी शक्तिशाली विशेषताओं से कवर किया है, जिसमें स्कीमा डिज़ाइन के लिए विज़ुअल डेटा मॉडल निर्माण, व्यवसाय प्रक्रिया डिज़ाइन, REST API समर्थन और विभिन्न डेटाबेस के साथ अंतर्निहित संगतता शामिल है। AppMaster की क्षमताओं का लाभ उठाकर, आप पारंपरिक सॉफ्टवेयर विकास विधियों की तुलना में 10 गुना तेज और 3 गुना अधिक लागत प्रभावी ढंग से एप्लिकेशन विकसित कर सकते हैं।
अनुप्रयोग विकास के लिए सही डेटाबेस मॉडल का चयन करना महत्वपूर्ण है। संबंधपरक और गैर-संबंधपरक डेटाबेस के फायदों और सीमाओं का सावधानीपूर्वक मूल्यांकन करें, अपने एप्लिकेशन की आवश्यकताओं पर विचार करें और वह प्रकार चुनें जो आपके उपयोग के मामलों के लिए सबसे उपयुक्त हो। AppMaster के साथ, आप शक्तिशाली और स्केलेबल एप्लिकेशन बना सकते हैं जो आपकी व्यावसायिक आवश्यकताओं को प्रभावी ढंग से पूरा करते हैं।
रिलेशनल डेटाबेस को एक स्कीमा का उपयोग करके संरचित डेटा को संग्रहीत और प्रबंधित करने के लिए डिज़ाइन किया गया है जो तालिकाओं के बीच डेटा प्रकार, संबंधों और बाधाओं को परिभाषित करता है। वे रिलेशनल मॉडल पर आधारित हैं और डेटा को क्वेरी करने के लिए SQL का उपयोग करते हैं।
गैर-संबंधपरक डेटाबेस, जिन्हें NoSQL डेटाबेस के रूप में भी जाना जाता है, परिभाषित संबंधों वाली तालिकाओं के अलावा अन्य स्वरूपों में डेटा संग्रहीत करते हैं। वे असंरचित या अर्ध-संरचित डेटा को संभालने और गैर-एसक्यूएल क्वेरी भाषाओं का उपयोग करने के लिए डिज़ाइन किए गए हैं।
रिलेशनल डेटाबेस डेटा स्थिरता, अखंडता और SQL का उपयोग करके जटिल प्रश्नों को संभालने की क्षमता जैसे लाभ प्रदान करते हैं। संरचित डेटा और अच्छी तरह से परिभाषित संबंधों वाले अनुप्रयोगों के लिए इनका व्यापक रूप से उपयोग किया जाता है।
बड़ी मात्रा में असंरचित या अर्ध-संरचित डेटा के साथ काम करते समय गैर-संबंधपरक डेटाबेस उच्च मापनीयता, लचीलापन और प्रदर्शन प्रदान करते हैं। वे तेजी से पढ़ने/लिखने के संचालन और क्षैतिज स्केलिंग की आवश्यकता वाले अनुप्रयोगों के लिए उपयुक्त हैं।
रिलेशनल डेटाबेस में स्केलेबिलिटी के संदर्भ में सीमाएं हो सकती हैं, खासकर बड़े डेटासेट के साथ। वे असंरचित डेटा को संभालने में कम लचीले हो सकते हैं और जटिल संबंधों और प्रश्नों को प्रबंधित करने के लिए अधिक संसाधनों की आवश्यकता हो सकती है।
गैर-संबंधपरक डेटाबेस में ACID गुणों और संबंधपरक डेटाबेस द्वारा प्रदान की जाने वाली जटिल क्वेरी क्षमताओं जैसी कुछ सुविधाओं का अभाव हो सकता है। विशिष्ट NoSQL डेटाबेस प्रकार के आधार पर, उनके पास डेटा स्थिरता और अखंडता के लिए अलग-अलग समर्थन भी हो सकता है।
डेटाबेस चुनते समय डेटा संरचना, क्वेरी जटिलता, स्केलेबिलिटी, प्रदर्शन और एप्लिकेशन आवश्यकताओं जैसे कारकों पर विचार करें। अपने विशिष्ट उपयोग के मामले के लिए सबसे उपयुक्त का निर्धारण करने के लिए प्रत्येक प्रकार के पेशेवरों और विपक्षों का मूल्यांकन करें।
AppMaster का no-code प्लेटफ़ॉर्म रिलेशनल और गैर-रिलेशनल डेटाबेस दोनों के आसान एकीकरण की अनुमति देता है, जो वेब, मोबाइल और बैकएंड एप्लिकेशन बनाने में लचीलापन प्रदान करता है जो किसी भी पोस्टग्रेस्क्ल-संगत डेटाबेस के साथ प्राथमिक डेटाबेस के रूप में काम कर सकता है।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


