장비 예약 앱으로 충돌을 방지하고 반납을 추적하는 방법
이중 예약을 방지하고 반납과 손상을 기록하며 고장 난 장비를 유지보수 보류 상태로 전환하는 장비 예약 앱을 계획해 보세요.
관계형 데이터베이스와 비관계형 데이터베이스의 차이점을 살펴보세요. 귀하의 애플리케이션에 가장 적합한 데이터베이스 모델을 선택하는 데 도움이 되는 각각의 장점, 제한 사항 및 이상적인 사용 사례를 알아보십시오.

관계형 데이터베이스는 테이블 간의 데이터 유형, 관계, 제약 조건을 정의하는 스키마를 사용하여 구조화된 데이터를 저장하고 관리하도록 설계된 데이터베이스 관리 시스템(DBMS)입니다. 관계형 데이터베이스는 IBM의 컴퓨터 과학자인 Edgar F. Codd가 1970년에 도입한 개념인 관계형 모델을 기반으로 합니다. 이 모델에서 데이터는 열과 행이 있는 테이블로 구성됩니다. 여기서 각 행은 데이터 레코드를 나타내고 각 열은 데이터 속성에 해당합니다.
관계형 데이터베이스는 데이터 일관성, 무결성을 유지하고 서로 다른 테이블 간의 관계 및 제약 조건을 적용하도록 설계되었습니다. 이들은 데이터 쿼리, 조작 및 구성을 위해 SQL(구조적 쿼리 언어)을 사용합니다. SQL은 강력하고 널리 채택되는 쿼리 언어로, 사용자가 데이터에 대해 복잡한 작업을 쉽게 실행할 수 있도록 해줍니다.
널리 사용되는 관계형 데이터베이스로는 MySQL, PostgreSQL , Oracle 및 Microsoft SQL Server가 있습니다. 이는 많은 애플리케이션, 특히 일관되고 정확한 데이터 저장이 필요한 잘 정의된 데이터 구조 및 관계가 있는 애플리케이션에서 선택되었습니다.
관계형 데이터베이스는 여러 가지 장점을 제공하므로 다양한 애플리케이션에 널리 사용됩니다. 가장 중요한 이점 중 일부는 다음과 같습니다.
수많은 장점에도 불구하고 관계형 데이터베이스에는 애플리케이션에 선택하기 전에 고려해야 할 몇 가지 제한 사항이 있습니다. 이러한 제한 사항 중 일부는 다음과 같습니다.
다음 섹션에서는 비관계형 데이터베이스, 장점, 제한 사항, 관계형 데이터베이스와 비관계형 데이터베이스 간의 비교에 대해 논의하여 애플리케이션에 대한 정보를 바탕으로 결정을 내리는 데 도움을 드립니다.
NoSQL(Not Only SQL) 데이터베이스라고도 하는 비관계형 데이터베이스는 기존 관계형 데이터베이스의 대안입니다. 이러한 데이터베이스는 테이블 이외의 형식으로 데이터를 저장하고 비정형 또는 반정형 데이터를 저장하고 관리하기 위한 더 간단하고 유연하며 확장 가능한 솔루션을 제공하도록 설계되었습니다. 비관계형 데이터베이스는 키-값, 컬럼 패밀리, 문서, 그래프 등 다양한 형식의 데이터를 처리할 수 있습니다.
널리 사용되는 비관계형 데이터베이스로는 MongoDB (문서 기반), Cassandra(열 계열), Redis(키-값) 및 Neo4j (그래프)가 있습니다. 이러한 데이터베이스는 서로 다른 기능, 아키텍처 및 기능을 갖추고 있지만 모두 관계형 데이터베이스와 구별되는 몇 가지 공통된 특성을 공유합니다. 그들은 대게:
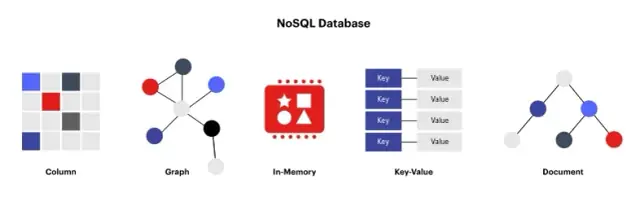
이미지 출처: redis.com
비관계형 데이터베이스는 관계형 데이터베이스에 비해 몇 가지 장점을 제공하므로 비정형 또는 반정형 데이터, 높은 트래픽 볼륨 및 빠른 읽기/쓰기 작업을 처리하는 최신 애플리케이션에 매력적인 옵션이 됩니다. 이러한 이점 중 일부는 다음과 같습니다.
비관계형 데이터베이스는 장점에도 불구하고 관계형 데이터베이스에 비해 몇 가지 제한 사항이 있습니다. 이러한 단점 중 일부는 다음과 같습니다.
애플리케이션에 대해 관계형 데이터베이스와 비관계형 데이터베이스를 결정할 때 두 모델 간의 주요 차이점을 이해하는 것이 중요합니다. 다음은 그 특성을 간략하게 비교한 것입니다.
관계형 데이터베이스는 미리 정의된 관계가 있는 테이블에 구조화된 데이터를 저장하도록 설계되었습니다. 여기에는 데이터 유형, 테이블 구조 및 테이블 간의 관계를 결정하는 고정된 스키마가 필요합니다. 반면 비관계형 데이터베이스는 비정형 또는 반정형 데이터를 키-값, 문서, 열 패밀리, 그래프 등 다양한 형식으로 저장할 수 있습니다. 고정된 스키마 없이 데이터를 처리하는 데 더 유연합니다.
관계형 데이터베이스는 데이터 조작 및 검색을 위해 SQL(구조적 쿼리 언어)을 사용합니다. SQL은 복잡한 쿼리 기능을 가능하게 하는 강력하고 널리 사용되는 언어입니다. 비관계형 데이터베이스는 데이터 구조에 따라 다양한 쿼리 언어를 사용합니다. 예를 들어 MongoDB는 BSON(Binary JSON) 쿼리를 사용하는 반면 Cassandra는 CQL(Cassandra Query Language)을 사용합니다.
관계형 데이터베이스는 ACID(원자성, 일관성, 격리, 내구성) 속성을 사용하여 일관성과 무결성을 강화하여 트랜잭션이 안정적으로 처리되고 데이터가 일관성을 유지하도록 보장합니다. 비관계형 데이터베이스는 일반적으로 엄격한 일관성과 무결성보다 성능과 확장성을 우선시합니다. NoSQL 데이터베이스 유형에 따라 최종 일관성 모델 또는 조정 가능한 일관성 수준을 통해 다양한 수준의 일관성을 제공할 수 있습니다.
관계형 데이터베이스는 단일 서버에 리소스(예: CPU, 메모리, 스토리지)를 추가해야 하는 수직적 확장에 중점을 둡니다. 이 접근 방식은 대량의 데이터와 높은 처리량의 애플리케이션을 처리할 때 제한될 수 있습니다. 비관계형 데이터베이스는 수평 확장을 위해 설계되어 여러 서버에 걸쳐 데이터와 로드를 분산할 수 있습니다. 이 접근 방식은 대규모 데이터 세트와 높은 읽기/쓰기 워크로드를 처리할 때 성능과 확장성을 향상시킵니다.
관계형 데이터베이스와 비관계형 데이터베이스 중에서 선택하려면 애플리케이션 요구 사항에 따라 다음 기준을 고려하세요.
관계형 데이터베이스와 비관계형 데이터베이스 중에서 선택하는 것은 애플리케이션의 특정 요구 사항과 고려 사항을 참조합니다. 일부 애플리케이션은 관계형 데이터베이스와 비관계형 데이터베이스를 모두 사용하여 두 모델의 장점을 활용하는 하이브리드 접근 방식을 사용한다는 점도 주목할 가치가 있습니다.
AppMaster's 코드 없는 플랫폼을 사용하여 애플리케이션을 개발할 때 요구 사항에 따라 관계형 데이터베이스와 비관계형 데이터베이스 중에서 선택할 수 있습니다. AppMaster 원활한 데이터베이스 통합 기능을 제공하므로 모든 Postgresql 호환 데이터베이스를 기본 데이터베이스로 사용하는 웹, 모바일 및 백엔드 애플리케이션을 쉽게 만들 수 있습니다.
선택한 데이터베이스 유형에 관계없이 AppMaster 스키마 디자인을 위한 시각적 데이터 모델 생성, 비즈니스 프로세스 디자인, REST API 지원 및 다양한 데이터베이스와의 내장 호환성을 포함하는 강력한 기능을 제공합니다. AppMaster 의 기능을 활용하면 기존 소프트웨어 개발 방법보다 최대 10배 더 빠르고 3배 더 비용 효율적으로 애플리케이션을 개발할 수 있습니다.
올바른 데이터베이스 모델을 선택하는 것은 애플리케이션 개발에 매우 중요합니다. 관계형 및 비관계형 데이터베이스의 장점과 제한 사항을 신중하게 평가하고, 애플리케이션의 요구 사항을 고려하고, 사용 사례에 가장 적합한 유형을 선택하세요. AppMaster 사용하면 비즈니스 요구 사항을 효과적으로 충족하는 강력하고 확장 가능한 애플리케이션을 구축할 수 있습니다.
관계형 데이터베이스는 테이블 간의 데이터 유형, 관계 및 제약 조건을 정의하는 스키마를 사용하여 구조화된 데이터를 저장하고 관리하도록 설계되었습니다. 관계형 모델을 기반으로 하며 데이터 쿼리에 SQL을 사용합니다.
NoSQL 데이터베이스라고도 하는 비관계형 데이터베이스는 정의된 관계가 있는 테이블이 아닌 다른 형식으로 데이터를 저장합니다. 비정형 또는 반정형 데이터를 처리하고 비SQL 쿼리 언어를 사용하도록 설계되었습니다.
관계형 데이터베이스는 데이터 일관성, 무결성 및 SQL을 사용하여 복잡한 쿼리를 처리하는 기능과 같은 이점을 제공합니다. 구조화된 데이터와 잘 정의된 관계가 있는 애플리케이션에 널리 사용됩니다.
비관계형 데이터베이스는 대량의 비정형 또는 반정형 데이터로 작업할 때 높은 확장성, 유연성 및 성능을 제공합니다. 빠른 읽기/쓰기 작업과 수평 확장이 필요한 애플리케이션에 적합합니다.
관계형 데이터베이스는 특히 대규모 데이터 세트의 경우 확장성 측면에서 제한이 있을 수 있습니다. 구조화되지 않은 데이터를 처리하는 데 유연성이 떨어질 수 있으며 복잡한 관계 및 쿼리를 관리하는 데 더 많은 리소스가 필요할 수 있습니다.
비관계형 데이터베이스에는 관계형 데이터베이스에서 제공하는 ACID 속성 및 복잡한 쿼리 기능과 같은 일부 기능이 부족할 수 있습니다. 또한 특정 NoSQL 데이터베이스 유형에 따라 데이터 일관성 및 무결성을 다양하게 지원할 수 있습니다.
데이터베이스를 선택할 때 데이터 구조, 쿼리 복잡성, 확장성, 성능 및 애플리케이션 요구 사항과 같은 요소를 고려하십시오. 각 유형의 장단점을 평가하여 특정 사용 사례에 가장 적합한 유형을 결정하세요.
AppMaster 의 no-code 플랫폼을 사용하면 관계형 및 비관계형 데이터베이스를 모두 쉽게 통합할 수 있어 모든 Postgresql 호환 데이터베이스를 기본 데이터베이스로 사용할 수 있는 웹, 모바일 및 백엔드 애플리케이션을 생성할 수 있는 유연성을 제공합니다.





