Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Khám phá sự khác biệt giữa cơ sở dữ liệu quan hệ và phi quan hệ. Tìm hiểu các ưu điểm, hạn chế và trường hợp sử dụng lý tưởng tương ứng của chúng để giúp bạn chọn mô hình cơ sở dữ liệu tốt nhất cho ứng dụng của mình.

Cơ sở dữ liệu quan hệ là một hệ thống quản lý cơ sở dữ liệu (DBMS) được thiết kế để lưu trữ và quản lý dữ liệu có cấu trúc bằng cách sử dụng lược đồ xác định các kiểu dữ liệu, mối quan hệ và ràng buộc giữa các bảng. Cơ sở dữ liệu quan hệ dựa trên mô hình quan hệ, một khái niệm được Edgar F. Codd, một nhà khoa học máy tính tại IBM đưa ra vào năm 1970. Trong mô hình này, dữ liệu được tổ chức trong các bảng có cột và hàng, trong đó mỗi hàng đại diện cho một bản ghi dữ liệu và mỗi cột tương ứng với một thuộc tính của dữ liệu.
Cơ sở dữ liệu quan hệ được thiết kế để duy trì tính nhất quán, tính toàn vẹn của dữ liệu và thực thi các mối quan hệ cũng như ràng buộc giữa các bảng khác nhau. Họ dựa vào Ngôn ngữ truy vấn có cấu trúc (SQL) để truy vấn, thao tác và tổ chức dữ liệu. SQL là ngôn ngữ truy vấn mạnh mẽ và được áp dụng rộng rãi, cho phép người dùng thực hiện các thao tác phức tạp trên dữ liệu một cách dễ dàng.
Một số cơ sở dữ liệu quan hệ phổ biến bao gồm MySQL, PostgreSQL , Oracle và Microsoft SQL Server. Chúng là lựa chọn phù hợp cho nhiều ứng dụng, đặc biệt là những ứng dụng có cấu trúc và mối quan hệ dữ liệu được xác định rõ ràng, yêu cầu lưu trữ dữ liệu nhất quán và chính xác.
Cơ sở dữ liệu quan hệ có nhiều ưu điểm, khiến chúng trở nên phổ biến cho nhiều ứng dụng khác nhau. Một số lợi ích đáng kể nhất bao gồm:
Mặc dù có nhiều ưu điểm nhưng cơ sở dữ liệu quan hệ cũng có một số hạn chế cần cân nhắc trước khi chọn chúng cho ứng dụng của bạn. Một số hạn chế này bao gồm:
Trong các phần tiếp theo, chúng ta sẽ thảo luận về cơ sở dữ liệu phi quan hệ, ưu điểm, hạn chế của chúng và so sánh giữa cơ sở dữ liệu quan hệ và cơ sở dữ liệu phi quan hệ để giúp bạn đưa ra quyết định sáng suốt cho ứng dụng của mình.
Cơ sở dữ liệu phi quan hệ, còn được gọi là cơ sở dữ liệu NoSQL (Không chỉ SQL) , là một giải pháp thay thế cho cơ sở dữ liệu quan hệ truyền thống. Các cơ sở dữ liệu này được thiết kế để lưu trữ dữ liệu ở các định dạng khác ngoài bảng và cung cấp giải pháp đơn giản hơn, linh hoạt hơn và có thể mở rộng hơn để lưu trữ và quản lý dữ liệu phi cấu trúc hoặc bán cấu trúc. Cơ sở dữ liệu phi quan hệ có thể xử lý dữ liệu ở nhiều định dạng khác nhau như khóa-giá trị, họ cột, tài liệu và biểu đồ.
Một số cơ sở dữ liệu phi quan hệ được sử dụng rộng rãi bao gồm MongoDB (dựa trên tài liệu), Cassandra (họ cột), Redis (khóa-giá trị) và Neo4j (biểu đồ). Các cơ sở dữ liệu này có các tính năng, kiến trúc và khả năng khác nhau nhưng tất cả đều có chung một số đặc điểm chung khiến chúng khác biệt với cơ sở dữ liệu quan hệ. Họ thường:
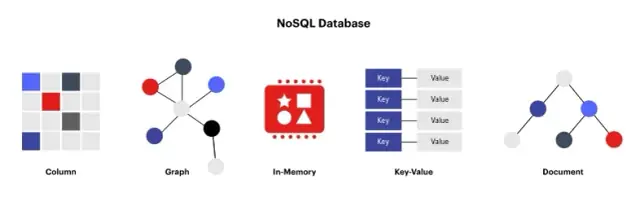
Nguồn hình ảnh: redis.com
Cơ sở dữ liệu phi quan hệ cung cấp một số lợi thế so với các cơ sở dữ liệu quan hệ, khiến chúng trở thành một lựa chọn hấp dẫn cho các ứng dụng hiện đại xử lý dữ liệu phi cấu trúc hoặc bán cấu trúc, lưu lượng truy cập cao và hoạt động đọc/ghi nhanh. Một số lợi ích này bao gồm:
Mặc dù có những ưu điểm nhưng cơ sở dữ liệu phi quan hệ cũng có những hạn chế nhất định so với cơ sở dữ liệu quan hệ. Một số nhược điểm này bao gồm:
Khi quyết định giữa cơ sở dữ liệu quan hệ và phi quan hệ cho ứng dụng của bạn, điều cần thiết là phải hiểu những điểm khác biệt chính giữa hai mô hình. Dưới đây là một so sánh ngắn gọn về đặc điểm của chúng:
Cơ sở dữ liệu quan hệ được thiết kế để lưu trữ dữ liệu có cấu trúc trong các bảng với các mối quan hệ được xác định trước. Chúng yêu cầu một lược đồ cố định xác định kiểu dữ liệu, cấu trúc bảng và mối quan hệ giữa các bảng. Mặt khác, cơ sở dữ liệu phi quan hệ có thể lưu trữ dữ liệu phi cấu trúc hoặc bán cấu trúc ở nhiều định dạng khác nhau như khóa-giá trị, tài liệu, họ cột và biểu đồ. Chúng linh hoạt hơn trong việc xử lý dữ liệu mà không cần lược đồ cố định.
Cơ sở dữ liệu quan hệ sử dụng Ngôn ngữ truy vấn có cấu trúc (SQL) để thao tác và truy xuất dữ liệu. SQL là một ngôn ngữ mạnh mẽ và được sử dụng rộng rãi, hỗ trợ khả năng truy vấn phức tạp. Cơ sở dữ liệu phi quan hệ sử dụng các ngôn ngữ truy vấn khác nhau dựa trên cấu trúc dữ liệu của chúng. Chẳng hạn, MongoDB sử dụng truy vấn BSON (JSON nhị phân), trong khi Cassandra sử dụng CQL (Ngôn ngữ truy vấn Cassandra).
Cơ sở dữ liệu quan hệ thực thi tính nhất quán và toàn vẹn bằng cách sử dụng các thuộc tính ACID (Tính nguyên tử, Tính nhất quán, Cách ly, Độ bền), đảm bảo các giao dịch được xử lý một cách đáng tin cậy và dữ liệu vẫn nhất quán. Cơ sở dữ liệu phi quan hệ thường ưu tiên hiệu suất và khả năng mở rộng hơn tính nhất quán và tính toàn vẹn nghiêm ngặt. Tùy thuộc vào loại cơ sở dữ liệu NoSQL, chúng có thể cung cấp các mức độ nhất quán khác nhau thông qua các mô hình nhất quán cuối cùng hoặc các mức độ nhất quán có thể điều chỉnh được.
Cơ sở dữ liệu quan hệ tập trung vào việc chia tỷ lệ theo chiều dọc, yêu cầu thêm tài nguyên (chẳng hạn như CPU, bộ nhớ và bộ lưu trữ) vào một máy chủ. Cách tiếp cận này có thể bị hạn chế khi xử lý lượng lớn dữ liệu và các ứng dụng có thông lượng cao. Cơ sở dữ liệu phi quan hệ được thiết kế để mở rộng theo chiều ngang, cho phép phân phối dữ liệu và tải trên nhiều máy chủ. Cách tiếp cận này cải thiện hiệu suất và khả năng mở rộng khi xử lý các tập dữ liệu lớn và khối lượng công việc đọc/ghi cao.
Để chọn giữa cơ sở dữ liệu quan hệ và phi quan hệ, hãy xem xét các tiêu chí sau dựa trên yêu cầu của ứng dụng của bạn:
Việc lựa chọn giữa cơ sở dữ liệu quan hệ và phi quan hệ đề cập đến các yêu cầu và cân nhắc cụ thể của ứng dụng của bạn. Cũng cần lưu ý rằng một số ứng dụng sử dụng các phương pháp kết hợp, trong đó chúng sử dụng cả cơ sở dữ liệu quan hệ và phi quan hệ để tận dụng lợi thế của cả hai mô hình.
Khi phát triển ứng dụng sử dụng nền tảng không mã's AppMaster , bạn có thể chọn giữa cơ sở dữ liệu quan hệ và không quan hệ dựa trên yêu cầu của mình. AppMaster cung cấp khả năng tích hợp cơ sở dữ liệu liền mạch, giúp dễ dàng tạo các ứng dụng web, thiết bị di động và chương trình phụ trợ hoạt động với bất kỳ cơ sở dữ liệu nào tương thích với Postgresql làm cơ sở dữ liệu chính.
Bất kể loại cơ sở dữ liệu nào bạn chọn, AppMaster đều cung cấp cho bạn các tính năng mạnh mẽ, bao gồm tạo mô hình dữ liệu trực quan để thiết kế lược đồ, thiết kế quy trình nghiệp vụ, hỗ trợ API REST và khả năng tương thích tích hợp với nhiều cơ sở dữ liệu khác nhau. Bằng cách tận dụng các khả năng của AppMaster, bạn có thể phát triển ứng dụng nhanh hơn gấp 10 lần và tiết kiệm chi phí gấp 3 lần so với các phương pháp phát triển phần mềm truyền thống.
Việc chọn mô hình cơ sở dữ liệu phù hợp là rất quan trọng để phát triển ứng dụng. Đánh giá cẩn thận những ưu điểm và hạn chế của cơ sở dữ liệu quan hệ và phi quan hệ, xem xét nhu cầu của ứng dụng và chọn loại phù hợp nhất với trường hợp sử dụng của bạn. Với AppMaster theo ý của bạn, bạn có thể xây dựng các ứng dụng mạnh mẽ và có thể mở rộng, đáp ứng hiệu quả các yêu cầu kinh doanh của mình.
Cơ sở dữ liệu quan hệ được thiết kế để lưu trữ và quản lý dữ liệu có cấu trúc bằng cách sử dụng lược đồ xác định kiểu dữ liệu, mối quan hệ và ràng buộc giữa các bảng. Chúng dựa trên mô hình quan hệ và sử dụng SQL để truy vấn dữ liệu.
Cơ sở dữ liệu phi quan hệ, còn được gọi là cơ sở dữ liệu NoSQL, lưu trữ dữ liệu ở các định dạng khác với các bảng có mối quan hệ được xác định. Chúng được thiết kế để xử lý dữ liệu phi cấu trúc hoặc bán cấu trúc và sử dụng các ngôn ngữ truy vấn không phải SQL.
Cơ sở dữ liệu quan hệ mang lại những lợi thế như tính nhất quán, tính toàn vẹn của dữ liệu và khả năng xử lý các truy vấn phức tạp bằng SQL. Chúng được sử dụng rộng rãi cho các ứng dụng có dữ liệu có cấu trúc và các mối quan hệ được xác định rõ ràng.
Cơ sở dữ liệu phi quan hệ cung cấp khả năng mở rộng, tính linh hoạt và hiệu suất cao khi làm việc với khối lượng lớn dữ liệu phi cấu trúc hoặc bán cấu trúc. Chúng phù hợp cho các ứng dụng yêu cầu thao tác đọc/ghi nhanh và chia tỷ lệ theo chiều ngang.
Cơ sở dữ liệu quan hệ có thể có những hạn chế về khả năng mở rộng, đặc biệt là với các bộ dữ liệu lớn. Chúng có thể kém linh hoạt hơn trong việc xử lý dữ liệu phi cấu trúc và có thể cần nhiều tài nguyên hơn để quản lý các mối quan hệ và truy vấn phức tạp.
Cơ sở dữ liệu phi quan hệ có thể thiếu một số tính năng như thuộc tính ACID và khả năng truy vấn phức tạp do cơ sở dữ liệu quan hệ cung cấp. Họ cũng có thể có nhiều hỗ trợ khác nhau về tính nhất quán và tính toàn vẹn của dữ liệu, tùy thuộc vào loại cơ sở dữ liệu NoSQL cụ thể.
Hãy xem xét các yếu tố như cấu trúc dữ liệu, độ phức tạp của truy vấn, khả năng mở rộng, hiệu suất và yêu cầu ứng dụng khi chọn cơ sở dữ liệu. Đánh giá ưu và nhược điểm của từng loại để xác định loại phù hợp nhất cho trường hợp sử dụng cụ thể của bạn.
Nền tảng no-code của AppMaster cho phép tích hợp dễ dàng cả cơ sở dữ liệu quan hệ và phi quan hệ, mang lại sự linh hoạt trong việc tạo các ứng dụng web, thiết bị di động và phụ trợ có thể hoạt động với bất kỳ cơ sở dữ liệu tương thích Postgresql nào làm cơ sở dữ liệu chính.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


