App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Explore as diferenças entre bancos de dados relacionais e não relacionais. Aprenda suas respectivas vantagens, limitações e casos de uso ideais para ajudá-lo a selecionar o melhor modelo de banco de dados para seu aplicativo.

Um banco de dados relacional é um sistema de gerenciamento de banco de dados (SGBD) projetado para armazenar e gerenciar dados estruturados usando um esquema que define os tipos de dados, relacionamentos e restrições entre tabelas. Os bancos de dados relacionais são baseados no modelo relacional, um conceito introduzido em 1970 por Edgar F. Codd, cientista da computação da IBM. Neste modelo, os dados são organizados em tabelas com colunas e linhas, onde cada linha representa um registro de dados e cada coluna corresponde a um atributo dos dados.
Os bancos de dados relacionais são projetados para manter a consistência e integridade dos dados e impor relacionamentos e restrições entre diferentes tabelas. Eles contam com Structured Query Language (SQL) para consulta, manipulação e organização de dados. SQL é uma linguagem de consulta poderosa e amplamente adotada, que permite aos usuários executar facilmente operações complexas em dados.
Alguns bancos de dados relacionais populares incluem MySQL, PostgreSQL , Oracle e Microsoft SQL Server. Eles têm sido a escolha certa para muitas aplicações, especialmente aquelas com estruturas e relacionamentos de dados bem definidos que exigem armazenamento de dados consistente e preciso.
Os bancos de dados relacionais oferecem diversas vantagens, tornando-os populares para diversas aplicações. Alguns dos benefícios mais significativos incluem:
Apesar das inúmeras vantagens, os bancos de dados relacionais também apresentam algumas limitações a serem consideradas antes de escolhê-los para sua aplicação. Algumas dessas limitações incluem:
Nas próximas seções, discutiremos bancos de dados não relacionais, suas vantagens, limitações e uma comparação entre bancos de dados relacionais e não relacionais para ajudá-lo a tomar uma decisão informada para sua aplicação.
Os bancos de dados não relacionais, também conhecidos como bancos de dados NoSQL (Not Only SQL) , são uma alternativa aos bancos de dados relacionais tradicionais. Esses bancos de dados são projetados para armazenar dados em formatos diferentes de tabelas e fornecem uma solução mais simples, flexível e escalável para armazenar e gerenciar dados não estruturados ou semiestruturados. Bancos de dados não relacionais podem lidar com dados em vários formatos, como valor-chave, família de colunas, documento e gráfico.
Alguns bancos de dados não relacionais amplamente utilizados incluem MongoDB (baseado em documentos), Cassandra (família de colunas), Redis (valor-chave) e Neo4j (gráfico). Esses bancos de dados vêm com diferentes recursos, arquiteturas e capacidades, mas todos compartilham algumas características comuns que os diferenciam dos bancos de dados relacionais. Eles normalmente:
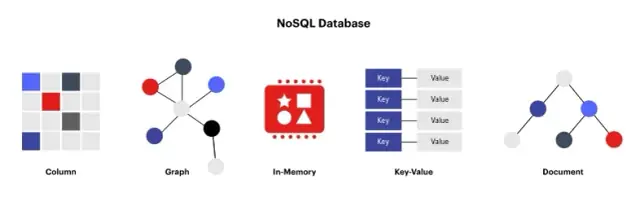
Fonte da imagem: redis.com
Os bancos de dados não relacionais oferecem diversas vantagens sobre seus equivalentes relacionais, tornando-os uma opção atraente para aplicações modernas que lidam com dados não estruturados ou semiestruturados, altos volumes de tráfego e operações rápidas de leitura/gravação. Alguns desses benefícios incluem:
Apesar de suas vantagens, os bancos de dados não relacionais também apresentam certas limitações em comparação aos bancos de dados relacionais. Algumas dessas desvantagens incluem:
Ao decidir entre bancos de dados relacionais e não relacionais para sua aplicação, é essencial compreender as principais diferenças entre os dois modelos. Aqui está uma breve comparação de suas características:
Os bancos de dados relacionais são projetados para armazenar dados estruturados em tabelas com relacionamentos predefinidos. Eles exigem um esquema fixo que determina os tipos de dados, a estrutura da tabela e os relacionamentos entre as tabelas. Os bancos de dados não relacionais, por outro lado, podem armazenar dados não estruturados ou semiestruturados em vários formatos, como valor-chave, documento, família de colunas e gráfico. Eles são mais flexíveis no tratamento de dados sem um esquema fixo.
Os bancos de dados relacionais usam a Structured Query Language (SQL) para manipulação e recuperação de dados. SQL é uma linguagem poderosa e amplamente utilizada que permite recursos de consulta complexos. Os bancos de dados não relacionais usam diferentes linguagens de consulta com base em sua estrutura de dados. Por exemplo, MongoDB usa consultas BSON (JSON binário), enquanto Cassandra usa CQL (Cassandra Query Language).
Os bancos de dados relacionais impõem consistência e integridade usando propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade), garantindo que as transações sejam processadas de maneira confiável e que os dados permaneçam consistentes. Os bancos de dados não relacionais normalmente priorizam o desempenho e a escalabilidade em vez da consistência e integridade estritas. Dependendo do tipo de banco de dados NoSQL, eles podem fornecer níveis variados de consistência por meio de modelos de consistência eventuais ou níveis de consistência ajustáveis.
Os bancos de dados relacionais concentram-se no escalonamento vertical, que requer a adição de recursos (como CPU, memória e armazenamento) a um único servidor. Essa abordagem pode ser limitante ao lidar com grandes quantidades de dados e aplicações de alto rendimento. Os bancos de dados não relacionais são projetados para escalabilidade horizontal, permitindo a distribuição de dados e carga em vários servidores. Essa abordagem melhora o desempenho e a escalabilidade ao lidar com conjuntos de dados massivos e altas cargas de trabalho de leitura/gravação.
Para escolher entre um banco de dados relacional e não relacional, considere os seguintes critérios com base nos requisitos do seu aplicativo:
A escolha entre bancos de dados relacionais e não relacionais refere-se aos requisitos e considerações específicos do seu aplicativo. Também vale a pena notar que algumas aplicações utilizam abordagens híbridas, onde empregam bancos de dados relacionais e não relacionais para aproveitar as vantagens de ambos os modelos.
Ao desenvolver aplicativos usando a plataforma sem código's AppMaster , você pode escolher entre bancos de dados relacionais e não relacionais com base em seus requisitos. AppMaster fornece recursos contínuos de integração de banco de dados, facilitando a criação de aplicativos web, móveis e de back-end que funcionam com qualquer banco de dados compatível com Postgresql como banco de dados primário.
Independentemente do tipo de banco de dados que você escolher, AppMaster oferece recursos poderosos, que incluem criação de modelo de dados visuais para design de esquema, design de processos de negócios, suporte a API REST e compatibilidade integrada com vários bancos de dados. Ao aproveitar os recursos do AppMaster, você pode desenvolver aplicativos até 10 vezes mais rápido e 3 vezes mais econômico do que os métodos tradicionais de desenvolvimento de software.
Selecionar o modelo de banco de dados correto é fundamental para o desenvolvimento de aplicativos. Avalie cuidadosamente as vantagens e limitações dos bancos de dados relacionais e não relacionais, considere as necessidades da sua aplicação e escolha o tipo que melhor se adapta aos seus casos de uso. Com AppMaster à sua disposição, você pode criar aplicativos poderosos e escalonáveis que atendam com eficácia aos seus requisitos de negócios.
Os bancos de dados relacionais são projetados para armazenar e gerenciar dados estruturados usando um esquema que define os tipos de dados, relacionamentos e restrições entre tabelas. Eles são baseados no modelo relacional e usam SQL para consultar dados.
Os bancos de dados não relacionais, também conhecidos como bancos de dados NoSQL, armazenam dados em formatos diferentes de tabelas com relacionamentos definidos. Eles são projetados para lidar com dados não estruturados ou semiestruturados e usar linguagens de consulta não SQL.
Os bancos de dados relacionais oferecem vantagens como consistência de dados, integridade e capacidade de lidar com consultas complexas usando SQL. Eles são amplamente utilizados para aplicações com dados estruturados e relacionamentos bem definidos.
Os bancos de dados não relacionais oferecem alta escalabilidade, flexibilidade e desempenho ao trabalhar com grandes volumes de dados não estruturados ou semiestruturados. Eles são adequados para aplicações que exigem operações rápidas de leitura/gravação e escalabilidade horizontal.
Os bancos de dados relacionais podem ter limitações em termos de escalabilidade, especialmente com grandes conjuntos de dados. Eles podem ser menos flexíveis no tratamento de dados não estruturados e exigir mais recursos para gerenciar relacionamentos e consultas complexas.
Os bancos de dados não relacionais podem não ter alguns recursos, como propriedades ACID e recursos de consulta complexos oferecidos pelos bancos de dados relacionais. Eles também podem ter suporte variado para consistência e integridade de dados, dependendo do tipo específico de banco de dados NoSQL.
Considere fatores como estrutura de dados, complexidade de consulta, escalabilidade, desempenho e requisitos de aplicação ao escolher um banco de dados. Avalie os prós e os contras de cada tipo para determinar a melhor opção para seu caso de uso específico.
A plataforma no-code do AppMaster permite fácil integração de bancos de dados relacionais e não relacionais, proporcionando flexibilidade na criação de aplicativos web, móveis e backend que podem funcionar com qualquer banco de dados compatível com Postgresql como banco de dados primário.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


