Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Dowiedz się, jak utworzyć dostosowany ChatGPT za pomocą narzędzia GPT Builder OpenAI, aby uzyskać dostosowane do potrzeb konwersacyjne doświadczenia AI. Przeprowadzimy Cię przez kolejne etapy, od wyboru zbioru danych po dopracowanie modelu.

ChatGPT , wywodzący się z potężnej rodziny GPT (Generative Pretrained Transformer) OpenAI, to najnowocześniejszy model konwersacyjnej sztucznej inteligencji, który jest w stanie zapewnić ludzkie odpowiedzi na różne pytania i zadania. Jest szeroko stosowany w różnych aplikacjach, takich jak chatboty , systemy obsługi klienta i generowanie treści, a jego głównym celem jest angażowanie się w interakcje z użytkownikami w języku naturalnym. Dzięki niezwykłej wydajności w generowaniu realistycznych i odpowiednich odpowiedzi tekstowych ChatGPT stał się integralną częścią wielu nowoczesnych systemów AI.
Aby zbudować niestandardowy ChatGPT, który będzie odpowiadał konkretnym wymaganiom projektu, dostosuj wstępnie wyszkolony model na zestawie danych pasującym do Twojej domeny. Umożliwia to modelowi poznanie niuansów domeny docelowej i wygenerowanie odpowiedzi, które są bardziej dopasowane do pożądanego doświadczenia związanego z konwersacją AI.
Konstruktor GPT OpenAI to narzędzie, które pozwala tworzyć własne, dostosowane instancje ChatGPT, koncentrując się na unikalnych potrzebach Twojej aplikacji. Wykorzystując potężny model GPT, GPT Builder pomaga dostroić oryginalny model na wybranym zbiorze danych, zapewniając zoptymalizowane konwersacyjne doświadczenia AI specjalnie dostosowane do Twojego projektu.
GPT Builder usprawnia dostosowywanie modeli ChatGPT, udostępniając łatwą w użyciu platformę do obsługi zbiorów danych, uczenia modeli, oceny i wdrażania. Umożliwia eksperymentowanie z konfiguracjami i przeprowadzanie niezbędnych korekt w celu osiągnięcia pożądanych wyników lub zrównoważenia wydajności modelu i ograniczeń zasobów.
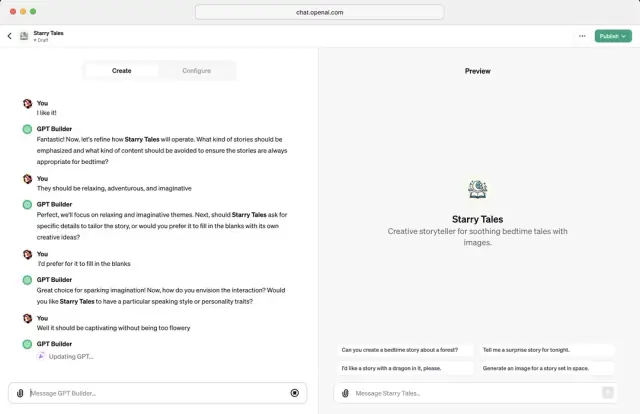
Źródło obrazu: The Verge
Przed zbudowaniem niestandardowego ChatGPT ważne jest skonfigurowanie odpowiedniego środowiska programistycznego. Będzie to wymagało określonej konfiguracji sprzętu i oprogramowania:
Zainstaluj w systemie następujące składniki oprogramowania:
Po skonfigurowaniu środowiska programistycznego możesz rozpocząć tworzenie niestandardowej instancji ChatGPT za pomocą narzędzia GPT Builder OpenAI. W nadchodzących sekcjach przeprowadzimy Cię przez kroki wymagane do wybrania i przygotowania zbioru danych, zbudowania i dostrojenia modelu, przetestowania i oceny jego wydajności oraz wdrożenia go do praktycznych zastosowań.
Sukces niestandardowego modelu ChatGPT w dużej mierze zależy od jakości i różnorodności zbioru danych wykorzystywanych podczas procesu dostrajania. Wybierając odpowiedni zbiór danych, możesz stworzyć model spełniający Twoje specyficzne wymagania i zapewniający pożądany poziom wydajności. Poniżej znajdują się kroki, które pomogą Ci wybrać i przygotować zbiór danych do szkolenia niestandardowego modelu ChatGPT.
Pierwszym krokiem jest zidentyfikowanie odpowiedniego zbioru danych konwersacyjnych, który jest zgodny z celami projektu. Istnieje kilka opcji wyboru zbioru danych:
Przed wprowadzeniem zbioru danych do niestandardowego modelu ChatGPT konieczne jest oczyszczenie i wstępne przetworzenie danych. Proces ten składa się z kilku etapów, w tym:
Po oczyszczeniu i wstępnym przetworzeniu musisz sformatować zbiór danych zgodnie z wymaganiami narzędzia GPT Builder OpenAI. Zazwyczaj modele oparte na czacie wymagają sformatowania rozmowy jako sekwencji naprzemiennych wypowiedzi użytkownika i odpowiedzi modelu. Każda para stwierdzeń i odpowiedzi powinna być wyraźnie oznaczona, a początek i koniec zdania lub rozmowy należy zastosować za pomocą specjalnych żetonów. Na przykład, jeśli Twój zbiór danych zawiera rozmowę pomiędzy użytkownikiem (U) a modelem (M), możesz sformatować go w następujący sposób: ``` { "dialog": [ {"role": "user, {"role" : "asystent, {"rola": "użytkownik, {"rola": "asystent ] } ```
Wybierając odpowiedni zbiór danych, oczyszczając go i wstępnie przetwarzając oraz formatując zgodnie z wymaganiami modelu, możesz stworzyć solidną podstawę do zbudowania wydajnego i dokładnego niestandardowego modelu ChatGPT.
Po przygotowaniu zestawu danych następnym krokiem jest zbudowanie i dostrojenie niestandardowego ChatGPT za pomocą narzędzia GPT Builder OpenAI. Poniższe kroki opisują proces budowania i dostrajania modelu:
Rozpocznij od zainicjowania modelu GPT za pomocą narzędzia GPT Builder OpenAI. Możesz wybierać pomiędzy różnymi rozmiarami modeli GPT, takimi jak GPT-3 , GPT-2, a nawet mniejszym modelem GPT, w zależności od wymagań dotyczących wydajności i zasobów.
Załaduj wstępnie wyszkolone wagi modeli z modelu GPT OpenAI. Wagi te zostały przeszkolone na podstawie miliardów danych wejściowych i stanowią mocny punkt wyjścia dla Twojego niestandardowego modelu.
Przed dostrojeniem niestandardowego modelu ChatGPT skonfiguruj środowisko szkoleniowe, określając niezbędne parametry i hiperparametry szkoleniowe, takie jak:
Po przygotowaniu konfiguracji treningu dostosuj niestandardowy model ChatGPT na przygotowanym zestawie danych za pomocą narzędzia GPT Builder. Ten proces aktualizuje wagi modeli w oparciu o wzorce w zestawie danych, dzięki czemu ChatGPT jest dostosowany do konkretnego przypadku użycia.
Dostrajanie modelu ChatGPT to proces iteracyjny. Monitoruj metryki wydajności modelu, takie jak zakłopotanie lub strata, i w razie potrzeby dostosuj hiperparametry. Być może będziesz musiał poeksperymentować z różnymi szybkościami uczenia się i rozmiarami partii, a nawet wstępnie przetworzyć zestaw danych w inny sposób, aby osiągnąć lepsze wyniki.
Budując i dostrajając niestandardowy model ChatGPT, możesz stworzyć konwersacyjny model AI, który zapewnia użytkownikom specyficzne dla domeny, bardzo trafne i dokładne odpowiedzi.
Po zbudowaniu i dopracowaniu niestandardowego modelu ChatGPT kluczowe znaczenie ma przetestowanie i ocena jego wydajności. Dzięki temu model zapewnia wysokiej jakości odpowiedzi i jest zgodny z celami projektu. Oto kilka kroków, które możesz wykonać, aby przetestować i ocenić swój model:
Metryki oceny ilościowej, takie jak BLEU, ROUGE lub METEOR, można wykorzystać do oceny jakości odpowiedzi wygenerowanych przez model. Metryki te porównują podobieństwo między odpowiedziami modelu a odpowiedziami referencyjnymi wygenerowanymi przez człowieka. Chociaż te metryki są pomocne w ocenie wydajności modelu, nie zawsze mogą uchwycić niuanse i znaczenie kontekstowe odpowiedzi.
Wdrożenie niestandardowego modelu ChatGPT w kontrolowanym środowisku może dostarczyć cennych informacji na temat jego rzeczywistej wydajności. Wejdź w interakcję z modelem, zadawaj różne pytania, stwierdzenia lub scenariusze i analizuj jakość, trafność i dokładność jego odpowiedzi.
Czasami ręczna ocena dokonana przez ekspertów dziedzinowych lub docelowych użytkowników może zapewnić cenny wgląd w wydajność modelu. Te oceny mogą pomóc Ci odkryć wszelkie rozbieżności, które mogły zostać przeoczone przez automatyczne dane. Może także rzucić światło na obszary wymagające dalszej poprawy lub udoskonalenia.
W oparciu o opinie i wyniki zebrane podczas fazy testowania i oceny, wykonaj iterację niestandardowego modelu ChatGPT, dostosowując konfigurację treningu, zbiór danych lub parametry treningu zgodnie z potrzebami. Pamiętaj, że utworzenie wysokowydajnego niestandardowego modelu ChatGPT wymaga ciągłych iteracji i optymalizacji.
Dokładnie testując, oceniając i udoskonalając swój model, możesz mieć pewność, że jest on ściśle zgodny z Twoimi wymaganiami i zapewnia użytkownikom wyjątkowe wrażenia z konwersacji. A jeśli planujesz zintegrować niestandardowy ChatGPT ze swoim oprogramowaniem, platformy takie jak AppMaster ułatwiają to dzięki swoim przyjaznym dla użytkownika interfejsom, które nie wymagają kodu .
Po zbudowaniu i dopracowaniu niestandardowego modelu ChatGPT konieczne jest jego skuteczne wdrożenie, aby użytkownicy mieli do niego dostęp i mogli z nim wchodzić w interakcję. Wykonaj poniższe kroki, aby wdrożyć niestandardowy model ChatGPT:
Po wdrożeniu niestandardowego ChatGPT i udostępnieniu go za pośrednictwem interfejsu API możesz zintegrować go z aplikacjami zewnętrznymi, takimi jak chatboty, systemy obsługi klienta lub platformy zarządzania treścią. Oto kilka wskazówek dotyczących integracji niestandardowego ChatGPT z aplikacjami zewnętrznymi:

Ciągła optymalizacja jest niezbędna, aby w pełni wykorzystać niestandardowy model ChatGPT. Skorzystaj z tych strategii, aby zoptymalizować niestandardowy model ChatGPT w celu uzyskania lepszej wydajności:
Postępując zgodnie z tymi wytycznymi, możesz jeszcze bardziej zwiększyć wydajność i możliwości niestandardowego modelu ChatGPT, upewniając się, że niezawodnie spełnia on potrzeby Twoich użytkowników i aplikacji.
W tym przewodniku przedstawiliśmy przegląd tworzenia własnego niestandardowego ChatGPT za pomocą narzędzia GPT Builder OpenAI. Tworząc dostosowany do potrzeb konwersacyjny model sztucznej inteligencji, możesz osiągnąć lepszą wydajność i dokładniejsze zrozumienie konkretnego przypadku użycia. Następnym krokiem jest zapoznanie się z podstawowymi tematami, takimi jak uczenie maszynowe, przetwarzanie języka naturalnego i ocena modelu, aby uzyskać dogłębne zrozumienie podstawowych pojęć. Stale twórz iteracje i ulepszaj swój niestandardowy ChatGPT, aby zmaksymalizować jego efektywność i dostroić jego możliwości, aby lepiej spełniać wymagania Twojego projektu.
Ponadto rozważ zbadanie innych konwersacyjnych modeli sztucznej inteligencji i alternatywnych rozwiązań ramowych, aby uzyskać szerszą perspektywę na dostępne technologie w tej dziedzinie. Nawiąż kontakt ze społecznością open source, aby uczyć się na ich doświadczeniach i wykorzystywać jej wiedzę do dostrajania i optymalizacji niestandardowego ChatGPT.
Na koniec rozważ wykorzystanie platform takich jak AppMaster, potężnego narzędzia no-code do tworzenia aplikacji internetowych, mobilnych i backendowych, aby bezproblemowo zintegrować niestandardowy ChatGPT ze swoimi projektami. Umożliwi to wykorzystanie mocy konwersacyjnej sztucznej inteligencji w różnych aspektach rozwiązań programowych, zapewniając lepszą obsługę użytkownika i optymalizując wydajność aplikacji.
Dzięki odpowiedniemu podejściu i chęci eksperymentowania możesz stworzyć potężny, niestandardowy ChatGPT, który zaspokoi Twoje unikalne potrzeby i pomoże Twojemu projektowi wyróżnić się w stale rozwijającym się świecie sztucznej inteligencji i technologii.
ChatGPT to konwersacyjny model sztucznej inteligencji, który może angażować się w interakcje z użytkownikami w języku naturalnym, zapewniając ludzkie odpowiedzi na pytania, uczestnicząc w dyskusjach i rozwiązując różne zadania.
Konstruktor GPT OpenAI umożliwia tworzenie dostosowanych do indywidualnych potrzeb instancji ChatGPT poprzez dostrojenie oryginalnego modelu GPT na konkretnym zestawie danych, oferując zoptymalizowane doświadczenia konwersacyjne AI, które lepiej odpowiadają wymaganiom Twojego projektu.
Aby skonfigurować środowisko programistyczne do pracy z GPT Builder, będziesz potrzebować wydajnego komputera, procesora graficznego NVIDIA i niezbędnego oprogramowania, takiego jak Python, TensorFlow i biblioteka OpenAI.
Wybór odpowiedniego zbioru danych ma kluczowe znaczenie dla zbudowania niestandardowego ChatGPT. Możesz skorzystać z istniejących zbiorów danych konwersacyjnych lub utworzyć własne. Przed szkoleniem modelu pamiętaj o prawidłowym wyczyszczeniu, wstępnym przetworzeniu i sformatowaniu zestawu danych.
Dostrajanie niestandardowego modelu ChatGPT obejmuje szkolenie modelu na zestawie danych, dostosowywanie hiperparametrów i powtarzanie tego procesu aż do osiągnięcia pożądanej wydajności.
Aby przetestować i ocenić niestandardowy ChatGPT, możesz użyć różnych wskaźników, takich jak BLEU, ROUGE lub METEOR, a także przeprowadzić testy w świecie rzeczywistym poprzez interakcje z użytkownikami i oceny ręczne.
Tak, możesz zintegrować swój niestandardowy ChatGPT z aplikacjami zewnętrznymi poprzez interfejsy API lub niestandardowe wtyczki, umożliwiając bezproblemową współpracę pomiędzy ChatGPT i innymi systemami.
Optymalizacja niestandardowego ChatGPT obejmuje dostrojenie modelu, dostosowanie hiperparametrów, optymalizację generowania odpowiedzi i dalsze dostosowywanie w oparciu o specyficzne wymagania projektu.
Platforma AppMaster no-code umożliwia bezproblemową integrację niestandardowych modeli ChatGPT z aplikacjami zbudowanymi na platformie, zapewniając usprawniony sposób wdrażania konwersacyjnej sztucznej inteligencji w rozwiązaniach programowych.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


